 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePatrol Security Game: Defending Against Adversary with Freedom in Attack Timing, Location, and Duration
Oct 21, 2024



We explored the Patrol Security Game (PSG), a robotic patrolling problem modeled as an extensive-form Stackelberg game, where the attacker determines the timing, location, and duration of their attack. Our objective is to devise a patrolling schedule with an infinite time horizon that minimizes the attacker's payoff. We demonstrated that PSG can be transformed into a combinatorial minimax problem with a closed-form objective function. By constraining the defender's strategy to a time-homogeneous first-order Markov chain (i.e., the patroller's next move depends solely on their current location), we proved that the optimal solution in cases of zero penalty involves either minimizing the expected hitting time or return time, depending on the attacker model, and that these solutions can be computed efficiently. Additionally, we observed that increasing the randomness in the patrol schedule reduces the attacker's expected payoff in high-penalty cases. However, the minimax problem becomes non-convex in other scenarios. To address this, we formulated a bi-criteria optimization problem incorporating two objectives: expected maximum reward and entropy. We proposed three graph-based algorithms and one deep reinforcement learning model, designed to efficiently balance the trade-off between these two objectives. Notably, the third algorithm can identify the optimal deterministic patrol schedule, though its runtime grows exponentially with the number of patrol spots. Experimental results validate the effectiveness and scalability of our solutions, demonstrating that our approaches outperform state-of-the-art baselines on both synthetic and real-world crime datasets.
An Analysis Of Entire Space Multi-Task Models For Post-Click Conversion Prediction
Aug 18, 2021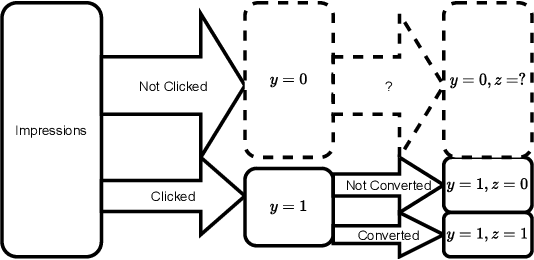
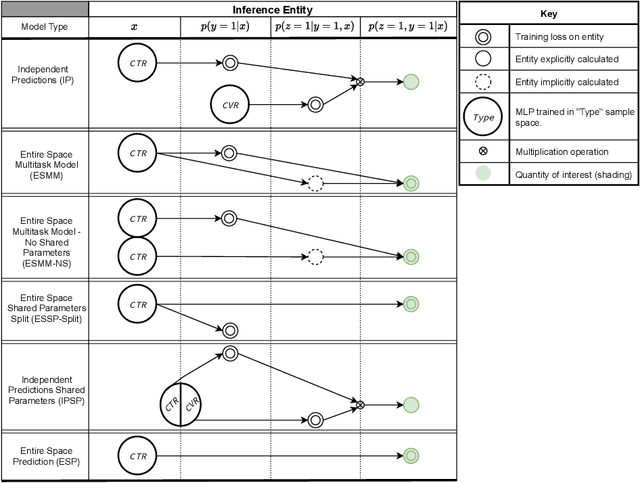
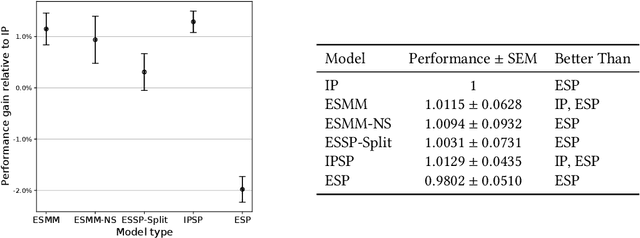
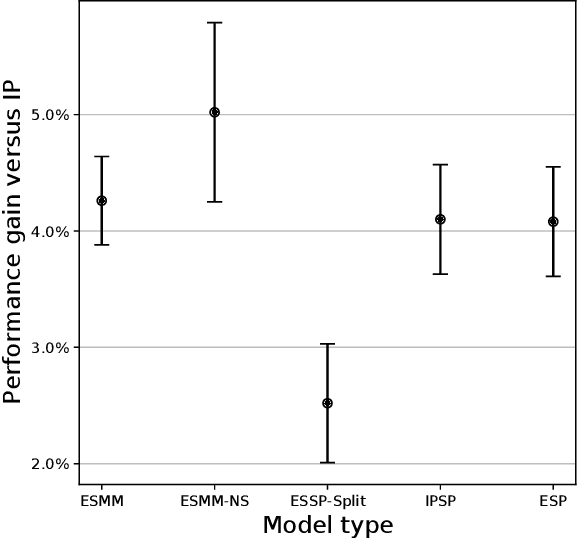
Industrial recommender systems are frequently tasked with approximating probabilities for multiple, often closely related, user actions. For example, predicting if a user will click on an advertisement and if they will then purchase the advertised product. The conceptual similarity between these tasks has promoted the use of multi-task learning: a class of algorithms that aim to bring positive inductive transfer from related tasks. Here, we empirically evaluate multi-task learning approaches with neural networks for an online advertising task. Specifically, we consider approximating the probability of post-click conversion events (installs) (CVR) for mobile app advertising on a large-scale advertising platform, using the related click events (CTR) as an auxiliary task. We use an ablation approach to systematically study recent approaches that incorporate both multitask learning and "entire space modeling" which train the CVR on all logged examples rather than learning a conditional likelihood of conversion given clicked. Based on these results we show that several different approaches result in similar levels of positive transfer from the data-abundant CTR task to the CVR task and offer some insight into how the multi-task design choices address the two primary problems affecting the CVR task: data sparsity and data bias. Our findings add to the growing body of evidence suggesting that standard multi-task learning is a sensible approach to modelling related events in real-world large-scale applications and suggest the specific multitask approach can be guided by ease of implementation in an existing system.
Layered Graph Embedding for Entity Recommendation using Wikipedia in the Yahoo! Knowledge Graph
Apr 15, 2020
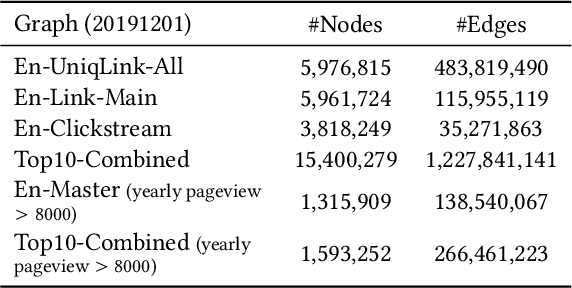
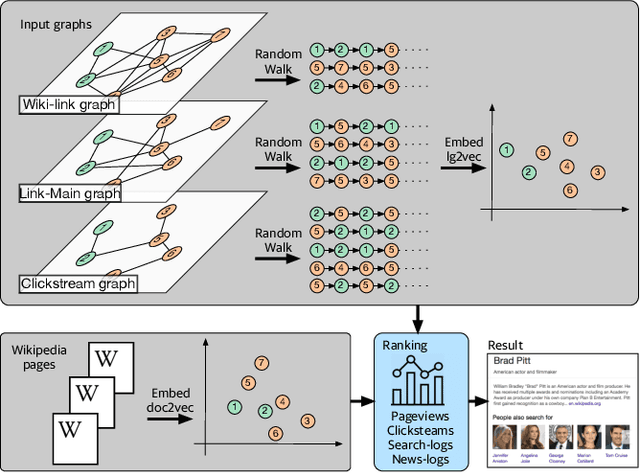
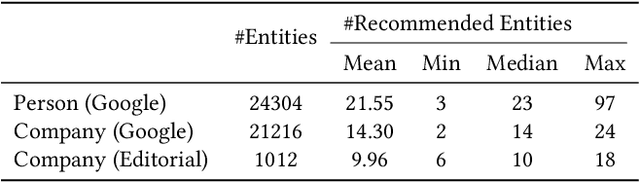
In this paper, we describe an embedding-based entity recommendation framework for Wikipedia that organizes Wikipedia into a collection of graphs layered on top of each other, learns complementary entity representations from their topology and content, and combines them with a lightweight learning-to-rank approach to recommend related entities on Wikipedia. Through offline and online evaluations, we show that the resulting embeddings and recommendations perform well in terms of quality and user engagement. Balancing simplicity and quality, this framework provides default entity recommendations for English and other languages in the Yahoo! Knowledge Graph, which Wikipedia is a core subset of.
Topology Based Scalable Graph Kernels
Jul 15, 2019
We propose a new graph kernel for graph classification and comparison using Ollivier Ricci curvature. The Ricci curvature of an edge in a graph describes the connectivity in the local neighborhood. An edge in a densely connected neighborhood has positive curvature and an edge serving as a local bridge has negative curvature. We use the edge curvature distribution to form a graph kernel which is then used to compare and cluster graphs. The curvature kernel uses purely the graph topology and thereby works for settings when node attributes are not available.
Performing Co-Membership Attacks Against Deep Generative Models
Oct 04, 2018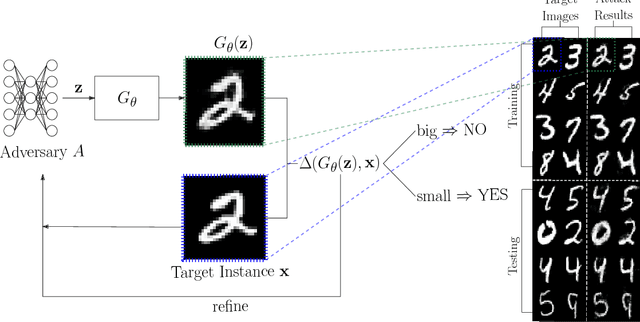
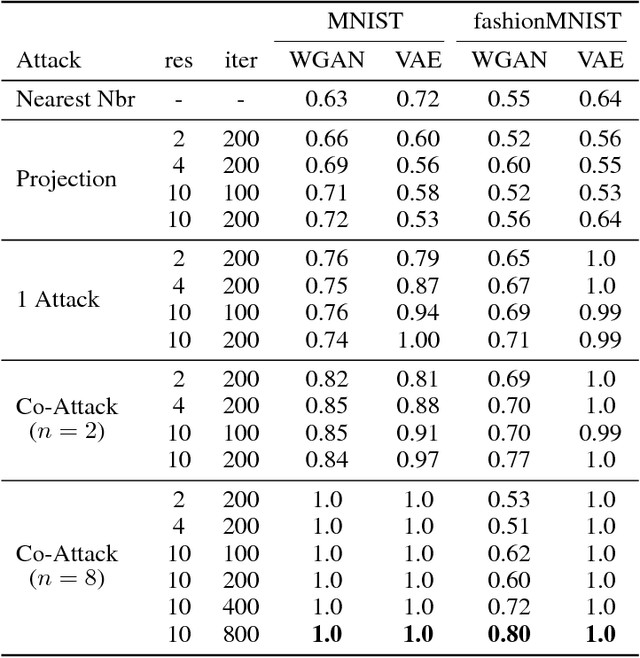
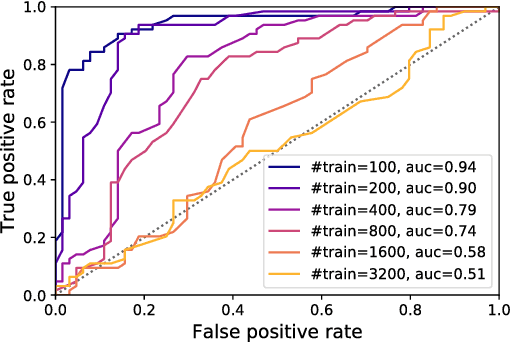

In this paper we propose new membership attacks and new attack methods against deep generative models including Variational Autoencoders (VAEs) and Generative Adversarial Networks (GANs). Specifically, a membership attack is to check whether a given instance x was used in the training data or not. And a co-membership attack is to check whether the given bundle n instances were in the training, with the prior knowledge that the bundle was either entirely used in the training or none at all. Successful membership attacks can compromise privacy of training data when the generative model is published. Our main idea is to cast membership inference of target data x as the optimization of another neural network (called the attacker network) to search for the seed to reproduce x. The final reconstruction error is used directly to conclude whether x is in the training data or not. We show through experiments on a variety of data sets and a suite of training parameters that our attacker network can be more successful than prior membership attacks; co-membership attack can be more powerful than single attacks; and VAEs are more susceptible to membership attacks compared to GANs in general. We also discussed membership attack with model generalization, overfitting, and diversity of the model.