 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Addendum to NeBula: Towards Extending TEAM CoSTAR's Solution to Larger Scale Environments
Apr 18, 2025This paper presents an appendix to the original NeBula autonomy solution developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), participating in the DARPA Subterranean Challenge. Specifically, this paper presents extensions to NeBula's hardware, software, and algorithmic components that focus on increasing the range and scale of the exploration environment. From the algorithmic perspective, we discuss the following extensions to the original NeBula framework: (i) large-scale geometric and semantic environment mapping; (ii) an adaptive positioning system; (iii) probabilistic traversability analysis and local planning; (iv) large-scale POMDP-based global motion planning and exploration behavior; (v) large-scale networking and decentralized reasoning; (vi) communication-aware mission planning; and (vii) multi-modal ground-aerial exploration solutions. We demonstrate the application and deployment of the presented systems and solutions in various large-scale underground environments, including limestone mine exploration scenarios as well as deployment in the DARPA Subterranean challenge.
Latent Weight Diffusion: Generating Policies from Trajectories
Oct 17, 2024With the increasing availability of open-source robotic data, imitation learning has emerged as a viable approach for both robot manipulation and locomotion. Currently, large generalized policies are trained to predict controls or trajectories using diffusion models, which have the desirable property of learning multimodal action distributions. However, generalizability comes with a cost - namely, larger model size and slower inference. Further, there is a known trade-off between performance and action horizon for Diffusion Policy (i.e., diffusing trajectories): fewer diffusion queries accumulate greater trajectory tracking errors. Thus, it is common practice to run these models at high inference frequency, subject to robot computational constraints. To address these limitations, we propose Latent Weight Diffusion (LWD), a method that uses diffusion to learn a distribution over policies for robotic tasks, rather than over trajectories. Our approach encodes demonstration trajectories into a latent space and then decodes them into policies using a hypernetwork. We employ a diffusion denoising model within this latent space to learn its distribution. We demonstrate that LWD can reconstruct the behaviors of the original policies that generated the trajectory dataset. LWD offers the benefits of considerably smaller policy networks during inference and requires fewer diffusion model queries. When tested on the Metaworld MT10 benchmark, LWD achieves a higher success rate compared to a vanilla multi-task policy, while using models up to ~18x smaller during inference. Additionally, since LWD generates closed-loop policies, we show that it outperforms Diffusion Policy in long action horizon settings, with reduced diffusion queries during rollout.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
Bridging Action Space Mismatch in Learning from Demonstrations
Apr 07, 2023



Learning from demonstrations (LfD) methods guide learning agents to a desired solution using demonstrations from a teacher. While some LfD methods can handle small mismatches in the action spaces of the teacher and student, here we address the case where the teacher demonstrates the task in an action space that can be substantially different from that of the student -- thereby inducing a large action space mismatch. We bridge this gap with a framework, Morphological Adaptation in Imitation Learning (MAIL), that allows training an agent from demonstrations by other agents with significantly different morphologies (from the student or each other). MAIL is able to learn from suboptimal demonstrations, so long as they provide some guidance towards a desired solution. We demonstrate MAIL on challenging household cloth manipulation tasks and introduce a new DRY CLOTH task -- cloth manipulation in 3D task with obstacles. In these tasks, we train a visual control policy for a robot with one end-effector using demonstrations from a simulated agent with two end-effectors. MAIL shows up to 27% improvement over LfD and non-LfD baselines. It is deployed to a real Franka Panda robot, and can handle multiple variations in cloth properties (color, thickness, size, material) and pose (rotation and translation). We further show generalizability to transfers from n-to-m end-effectors, in the context of a simple rearrangement task.
Learned Parameter Selection for Robotic Information Gathering
Mar 09, 2023



When robots are deployed in the field for environmental monitoring they typically execute pre-programmed motions, such as lawnmower paths, instead of adaptive methods, such as informative path planning. One reason for this is that adaptive methods are dependent on parameter choices that are both critical to set correctly and difficult for the non-specialist to choose. Here, we show how to automatically configure a planner for informative path planning by training a reinforcement learning agent to select planner parameters at each iteration of informative path planning. We demonstrate our method with 37 instances of 3 distinct environments, and compare it against pure (end-to-end) reinforcement learning techniques, as well as approaches that do not use a learned model to change the planner parameters. Our method shows a 9.53% mean improvement in the cumulative reward across diverse environments when compared to end-to-end learning based methods; we also demonstrate via a field experiment how it can be readily used to facilitate high performance deployment of an information gathering robot.
Learning Deformable Object Manipulation from Expert Demonstrations
Jul 20, 2022
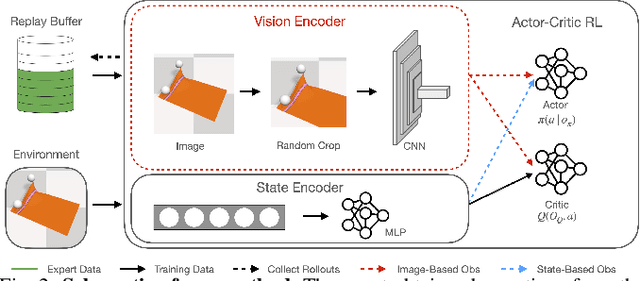
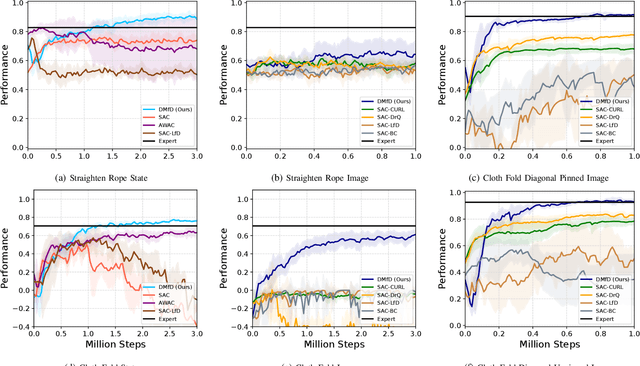
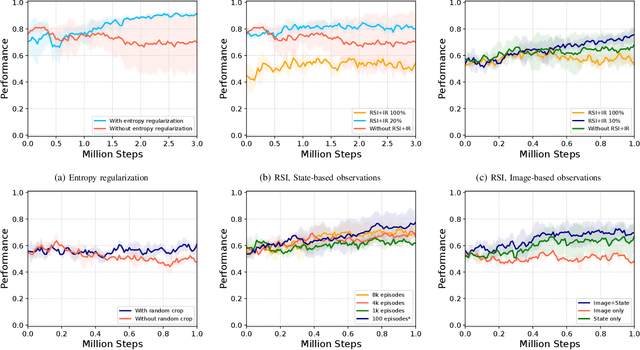
We present a novel Learning from Demonstration (LfD) method, Deformable Manipulation from Demonstrations (DMfD), to solve deformable manipulation tasks using states or images as inputs, given expert demonstrations. Our method uses demonstrations in three different ways, and balances the trade-off between exploring the environment online and using guidance from experts to explore high dimensional spaces effectively. We test DMfD on a set of representative manipulation tasks for a 1-dimensional rope and a 2-dimensional cloth from the SoftGym suite of tasks, each with state and image observations. Our method exceeds baseline performance by up to 12.9% for state-based tasks and up to 33.44% on image-based tasks, with comparable or better robustness to randomness. Additionally, we create two challenging environments for folding a 2D cloth using image-based observations, and set a performance benchmark for them. We deploy DMfD on a real robot with a minimal loss in normalized performance during real-world execution compared to simulation (~6%). Source code is on github.com/uscresl/dmfd
* Accepted to IEEE Robotics & Automation Letters (RA-L) and IEEE IROS 2022. Project website: https://uscresl.github.io/dmfd
Adaptive Sampling using POMDPs with Domain-Specific Considerations
Sep 23, 2021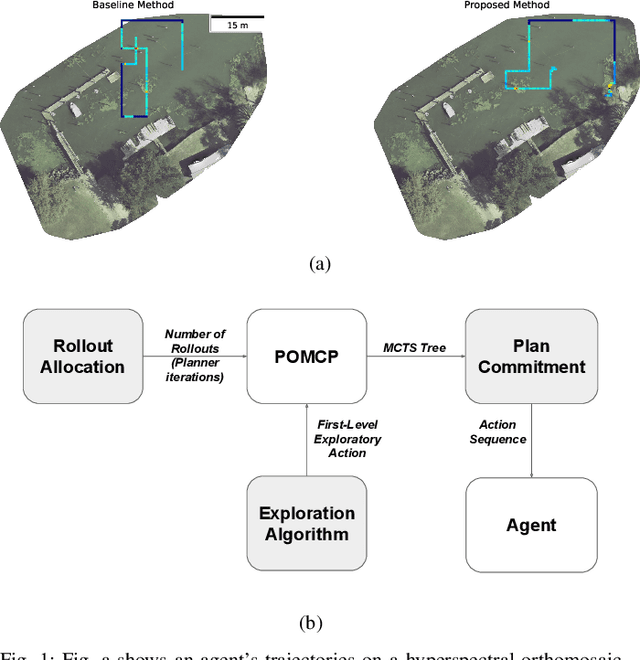



We investigate improving Monte Carlo Tree Search based solvers for Partially Observable Markov Decision Processes (POMDPs), when applied to adaptive sampling problems. We propose improvements in rollout allocation, the action exploration algorithm, and plan commitment. The first allocates a different number of rollouts depending on how many actions the agent has taken in an episode. We find that rollouts are more valuable after some initial information is gained about the environment. Thus, a linear increase in the number of rollouts, i.e. allocating a fixed number at each step, is not appropriate for adaptive sampling tasks. The second alters which actions the agent chooses to explore when building the planning tree. We find that by using knowledge of the number of rollouts allocated, the agent can more effectively choose actions to explore. The third improvement is in determining how many actions the agent should take from one plan. Typically, an agent will plan to take the first action from the planning tree and then call the planner again from the new state. Using statistical techniques, we show that it is possible to greatly reduce the number of rollouts by increasing the number of actions taken from a single planning tree without affecting the agent's final reward. Finally, we demonstrate experimentally, on simulated and real aquatic data from an underwater robot, that these improvements can be combined, leading to better adaptive sampling. The code for this work is available at https://github.com/uscresl/AdaptiveSamplingPOMCP
NeBula: Quest for Robotic Autonomy in Challenging Environments; TEAM CoSTAR at the DARPA Subterranean Challenge
Mar 28, 2021

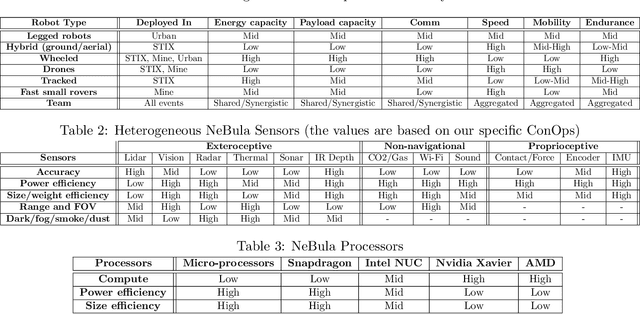
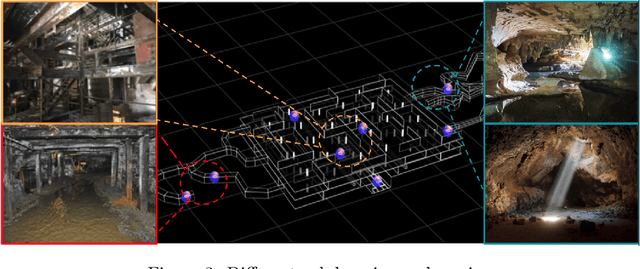
This paper presents and discusses algorithms, hardware, and software architecture developed by the TEAM CoSTAR (Collaborative SubTerranean Autonomous Robots), competing in the DARPA Subterranean Challenge. Specifically, it presents the techniques utilized within the Tunnel (2019) and Urban (2020) competitions, where CoSTAR achieved 2nd and 1st place, respectively. We also discuss CoSTAR's demonstrations in Martian-analog surface and subsurface (lava tubes) exploration. The paper introduces our autonomy solution, referred to as NeBula (Networked Belief-aware Perceptual Autonomy). NeBula is an uncertainty-aware framework that aims at enabling resilient and modular autonomy solutions by performing reasoning and decision making in the belief space (space of probability distributions over the robot and world states). We discuss various components of the NeBula framework, including: (i) geometric and semantic environment mapping; (ii) a multi-modal positioning system; (iii) traversability analysis and local planning; (iv) global motion planning and exploration behavior; (i) risk-aware mission planning; (vi) networking and decentralized reasoning; and (vii) learning-enabled adaptation. We discuss the performance of NeBula on several robot types (e.g. wheeled, legged, flying), in various environments. We discuss the specific results and lessons learned from fielding this solution in the challenging courses of the DARPA Subterranean Challenge competition.
PLGRIM: Hierarchical Value Learning for Large-scale Exploration in Unknown Environments
Feb 10, 2021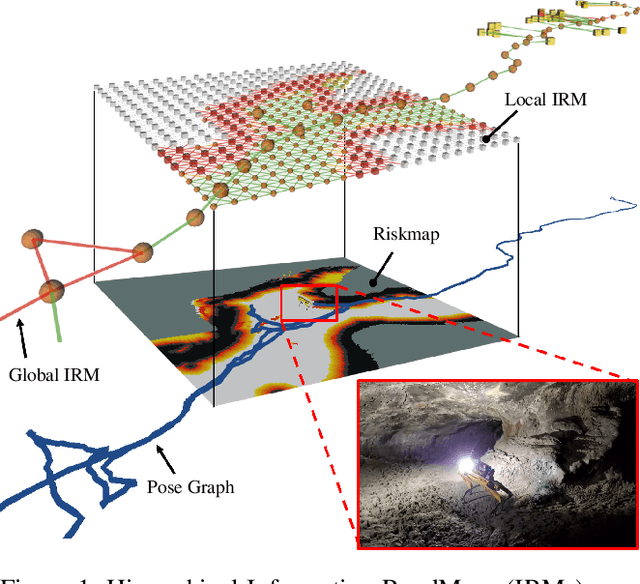
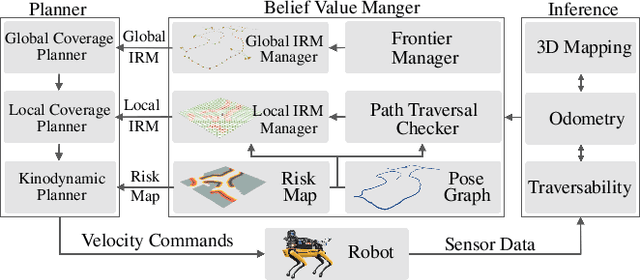
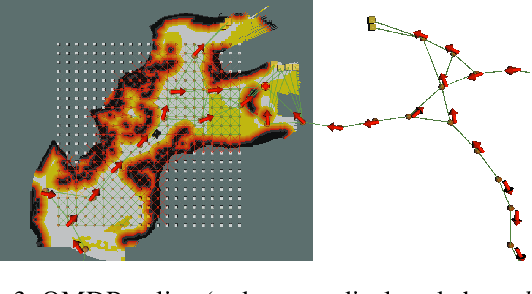
In order for a robot to explore an unknown environment autonomously, it must account for uncertainty in sensor measurements, hazard assessment, localization, and motion execution. Making decisions for maximal reward in a stochastic setting requires learning values and constructing policies over a belief space, i.e., probability distribution of the robot-world state. Value learning over belief spaces suffer from computational challenges in high-dimensional spaces, such as large spatial environments and long temporal horizons for exploration. At the same time, it should be adaptive and resilient to disturbances at run time in order to ensure the robot's safety, as required in many real-world applications. This work proposes a scalable value learning framework, PLGRIM (Probabilistic Local and Global Reasoning on Information roadMaps), that bridges the gap between (i) local, risk-aware resiliency and (ii) global, reward-seeking mission objectives. By leveraging hierarchical belief space planners with information-rich graph structures, PLGRIM can address large-scale exploration problems while providing locally near-optimal coverage plans. PLGRIM is a step toward enabling belief space planners on physical robots operating in unknown and complex environments. We validate our proposed framework with a high-fidelity dynamic simulation in diverse environments and with physical hardware, Boston Dynamics' Spot robot, in a lava tube.
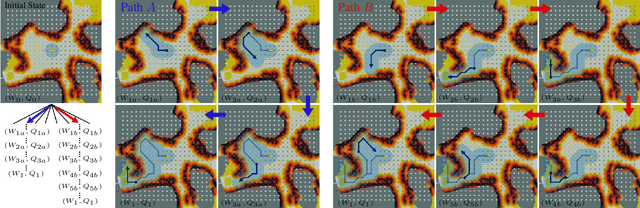
Motion Planner Augmented Reinforcement Learning for Robot Manipulation in Obstructed Environments
Oct 22, 2020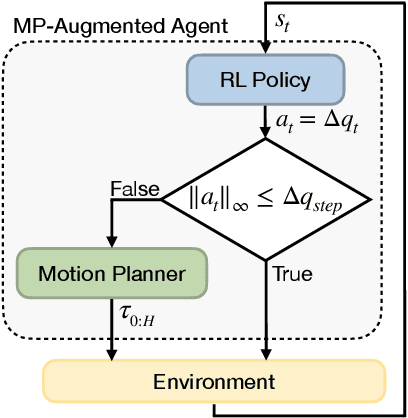

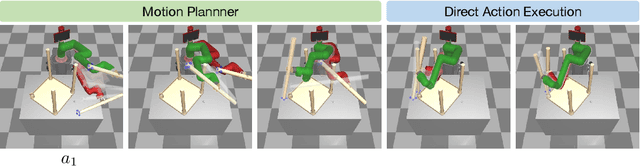

Deep reinforcement learning (RL) agents are able to learn contact-rich manipulation tasks by maximizing a reward signal, but require large amounts of experience, especially in environments with many obstacles that complicate exploration. In contrast, motion planners use explicit models of the agent and environment to plan collision-free paths to faraway goals, but suffer from inaccurate models in tasks that require contacts with the environment. To combine the benefits of both approaches, we propose motion planner augmented RL (MoPA-RL) which augments the action space of an RL agent with the long-horizon planning capabilities of motion planners. Based on the magnitude of the action, our approach smoothly transitions between directly executing the action and invoking a motion planner. We evaluate our approach on various simulated manipulation tasks and compare it to alternative action spaces in terms of learning efficiency and safety. The experiments demonstrate that MoPA-RL increases learning efficiency, leads to a faster exploration, and results in safer policies that avoid collisions with the environment. Videos and code are available at https://clvrai.com/mopa-rl .