 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearned Parameter Selection for Robotic Information Gathering
Mar 09, 2023



When robots are deployed in the field for environmental monitoring they typically execute pre-programmed motions, such as lawnmower paths, instead of adaptive methods, such as informative path planning. One reason for this is that adaptive methods are dependent on parameter choices that are both critical to set correctly and difficult for the non-specialist to choose. Here, we show how to automatically configure a planner for informative path planning by training a reinforcement learning agent to select planner parameters at each iteration of informative path planning. We demonstrate our method with 37 instances of 3 distinct environments, and compare it against pure (end-to-end) reinforcement learning techniques, as well as approaches that do not use a learned model to change the planner parameters. Our method shows a 9.53% mean improvement in the cumulative reward across diverse environments when compared to end-to-end learning based methods; we also demonstrate via a field experiment how it can be readily used to facilitate high performance deployment of an information gathering robot.
Adaptive Sampling to Estimate Quantiles for Guiding Physical Sampling
Jan 25, 2022
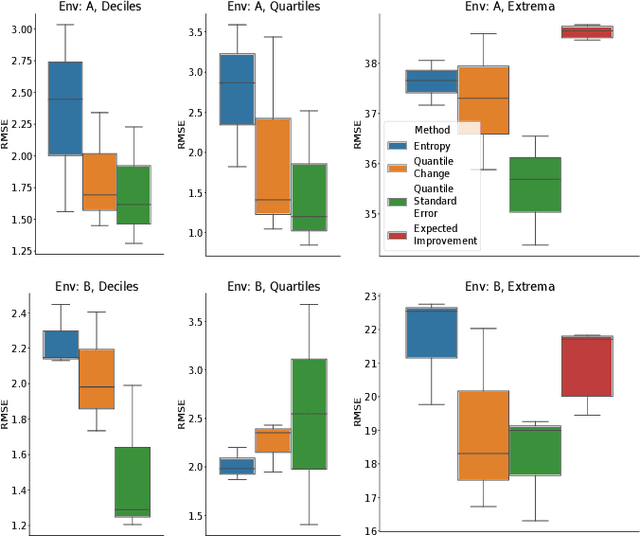
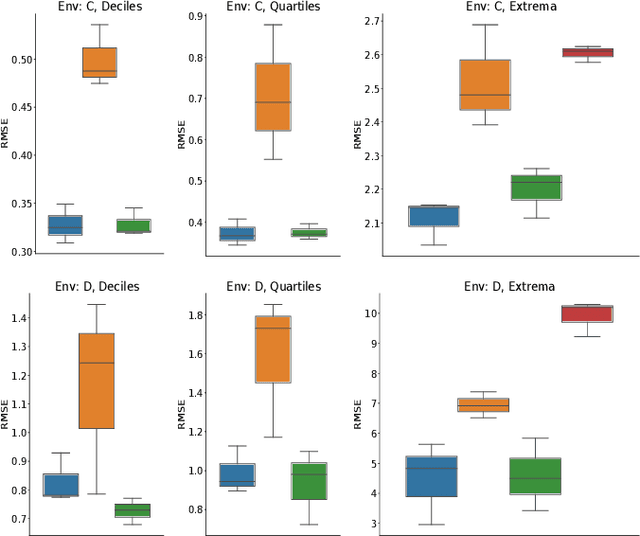
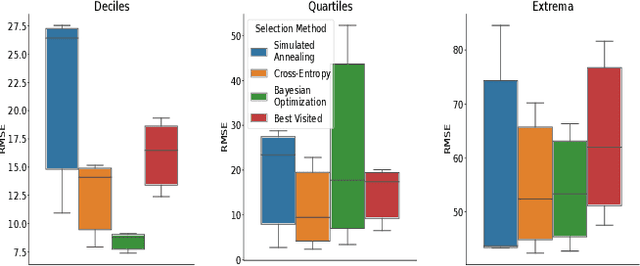
Scientists interested in studying natural phenomena often take physical samples for later analysis at locations specified by expert heuristics. Instead, we propose to guide scientists' physical sampling by using a robot to perform an adaptive sampling survey to find locations to suggest that correspond to the quantile values of pre-specified quantiles of interest. We develop a robot planner using novel objective functions to improve the estimates of the quantile values over time and an approach to find locations which correspond to the quantile values. We demonstrate our approach on two different sampling tasks in simulation using previously collected aquatic data and validate it in a field trial. Our approach outperforms objectives that maximize spatial coverage or find extrema in planning and is able to localize the quantile spatial locations.
Adaptive Sampling using POMDPs with Domain-Specific Considerations
Sep 23, 2021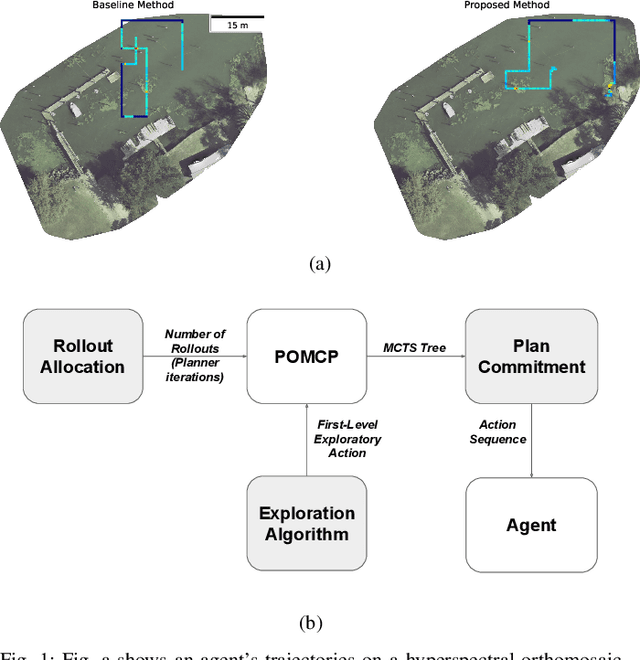



We investigate improving Monte Carlo Tree Search based solvers for Partially Observable Markov Decision Processes (POMDPs), when applied to adaptive sampling problems. We propose improvements in rollout allocation, the action exploration algorithm, and plan commitment. The first allocates a different number of rollouts depending on how many actions the agent has taken in an episode. We find that rollouts are more valuable after some initial information is gained about the environment. Thus, a linear increase in the number of rollouts, i.e. allocating a fixed number at each step, is not appropriate for adaptive sampling tasks. The second alters which actions the agent chooses to explore when building the planning tree. We find that by using knowledge of the number of rollouts allocated, the agent can more effectively choose actions to explore. The third improvement is in determining how many actions the agent should take from one plan. Typically, an agent will plan to take the first action from the planning tree and then call the planner again from the new state. Using statistical techniques, we show that it is possible to greatly reduce the number of rollouts by increasing the number of actions taken from a single planning tree without affecting the agent's final reward. Finally, we demonstrate experimentally, on simulated and real aquatic data from an underwater robot, that these improvements can be combined, leading to better adaptive sampling. The code for this work is available at https://github.com/uscresl/AdaptiveSamplingPOMCP