 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdaptive Sampling using POMDPs with Domain-Specific Considerations
Paper and Code
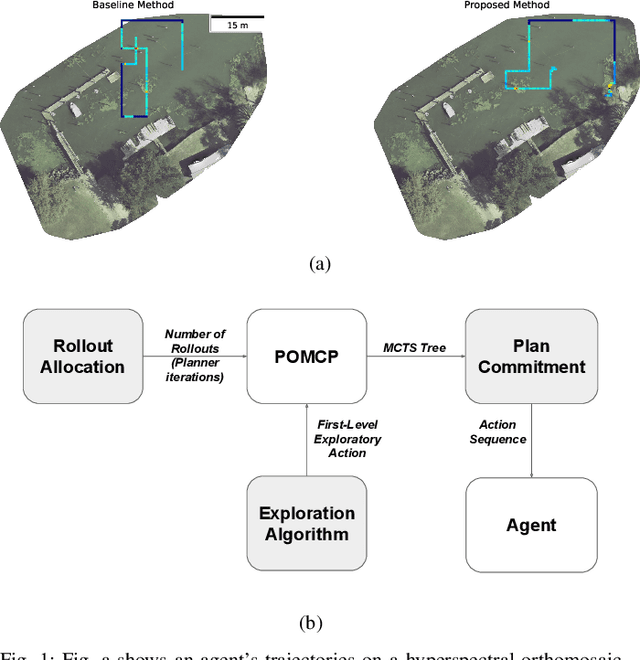



We investigate improving Monte Carlo Tree Search based solvers for Partially Observable Markov Decision Processes (POMDPs), when applied to adaptive sampling problems. We propose improvements in rollout allocation, the action exploration algorithm, and plan commitment. The first allocates a different number of rollouts depending on how many actions the agent has taken in an episode. We find that rollouts are more valuable after some initial information is gained about the environment. Thus, a linear increase in the number of rollouts, i.e. allocating a fixed number at each step, is not appropriate for adaptive sampling tasks. The second alters which actions the agent chooses to explore when building the planning tree. We find that by using knowledge of the number of rollouts allocated, the agent can more effectively choose actions to explore. The third improvement is in determining how many actions the agent should take from one plan. Typically, an agent will plan to take the first action from the planning tree and then call the planner again from the new state. Using statistical techniques, we show that it is possible to greatly reduce the number of rollouts by increasing the number of actions taken from a single planning tree without affecting the agent's final reward. Finally, we demonstrate experimentally, on simulated and real aquatic data from an underwater robot, that these improvements can be combined, leading to better adaptive sampling. The code for this work is available at https://github.com/uscresl/AdaptiveSamplingPOMCP