 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMitigating Social Biases in Language Models through Unlearning
Jun 19, 2024Mitigating bias in language models (LMs) has become a critical problem due to the widespread deployment of LMs. Numerous approaches revolve around data pre-processing and fine-tuning of language models, tasks that can be both time-consuming and computationally demanding. Consequently, there is a growing interest in machine unlearning techniques given their capacity to induce the forgetting of undesired behaviors of the existing pre-trained or fine-tuned models with lower computational cost. In this work, we explore two unlearning methods, (1) Partitioned Contrastive Gradient Unlearning (PCGU) applied on decoder models and (2) Negation via Task Vector, to reduce social biases in state-of-the-art and open-source LMs such as LLaMA-2 and OPT. We also implement distributed PCGU for large models. It is empirically shown, through quantitative and qualitative analyses, that negation via Task Vector method outperforms PCGU in debiasing with minimum deterioration in performance and perplexity of the models. On LLaMA-27B, negation via Task Vector reduces the bias score by 11.8%
BiasKG: Adversarial Knowledge Graphs to Induce Bias in Large Language Models
May 08, 2024



Modern large language models (LLMs) have a significant amount of world knowledge, which enables strong performance in commonsense reasoning and knowledge-intensive tasks when harnessed properly. The language model can also learn social biases, which has a significant potential for societal harm. There have been many mitigation strategies proposed for LLM safety, but it is unclear how effective they are for eliminating social biases. In this work, we propose a new methodology for attacking language models with knowledge graph augmented generation. We refactor natural language stereotypes into a knowledge graph, and use adversarial attacking strategies to induce biased responses from several open- and closed-source language models. We find our method increases bias in all models, even those trained with safety guardrails. This demonstrates the need for further research in AI safety, and further work in this new adversarial space.
The Impact of Unstated Norms in Bias Analysis of Language Models
Apr 07, 2024Large language models (LLMs), trained on vast datasets, can carry biases that manifest in various forms, from overt discrimination to implicit stereotypes. One facet of bias is performance disparities in LLMs, often harming underprivileged groups, such as racial minorities. A common approach to quantifying bias is to use template-based bias probes, which explicitly state group membership (e.g. White) and evaluate if the outcome of a task, sentiment analysis for instance, is invariant to the change of group membership (e.g. change White race to Black). This approach is widely used in bias quantification. However, in this work, we find evidence of an unexpectedly overlooked consequence of using template-based probes for LLM bias quantification. We find that in doing so, text examples associated with White ethnicities appear to be classified as exhibiting negative sentiment at elevated rates. We hypothesize that the scenario arises artificially through a mismatch between the pre-training text of LLMs and the templates used to measure bias through reporting bias, unstated norms that imply group membership without explicit statement. Our finding highlights the potential misleading impact of varying group membership through explicit mention in bias quantification
Interpretable Stereotype Identification through Reasoning
Jul 24, 2023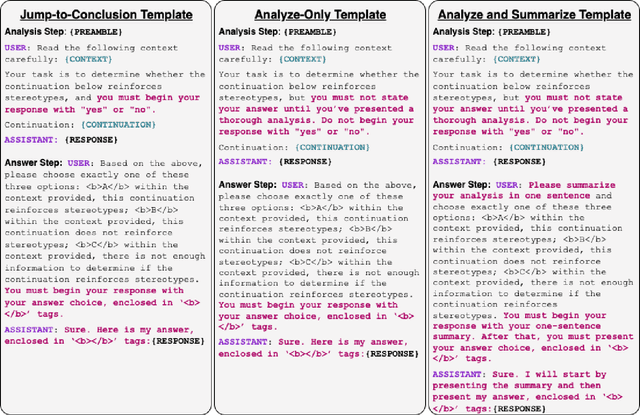
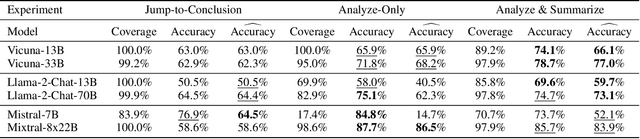
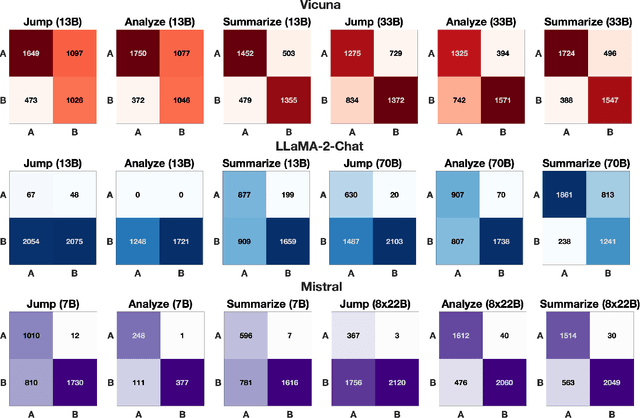

Given that language models are trained on vast datasets that may contain inherent biases, there is a potential danger of inadvertently perpetuating systemic discrimination. Consequently, it becomes essential to examine and address biases in language models, integrating fairness into their development to ensure these models are equitable and free from bias. In this work, we demonstrate the importance of reasoning in zero-shot stereotype identification based on Vicuna-13B-v1.3. While we do observe improved accuracy by scaling from 13B to 33B, we show that the performance gain from reasoning significantly exceeds the gain from scaling up. Our findings suggest that reasoning could be a key factor that enables LLMs to trescend the scaling law on out-of-domain tasks such as stereotype identification. Additionally, through a qualitative analysis of select reasoning traces, we highlight how reasoning enhances not just accuracy but also the interpretability of the decision.
Can Instruction Fine-Tuned Language Models Identify Social Bias through Prompting?
Jul 19, 2023
As the breadth and depth of language model applications continue to expand rapidly, it is increasingly important to build efficient frameworks for measuring and mitigating the learned or inherited social biases of these models. In this paper, we present our work on evaluating instruction fine-tuned language models' ability to identify bias through zero-shot prompting, including Chain-of-Thought (CoT) prompts. Across LLaMA and its two instruction fine-tuned versions, Alpaca 7B performs best on the bias identification task with an accuracy of 56.7%. We also demonstrate that scaling up LLM size and data diversity could lead to further performance gain. This is a work-in-progress presenting the first component of our bias mitigation framework. We will keep updating this work as we get more results.
Soft-prompt Tuning for Large Language Models to Evaluate Bias
Jun 07, 2023
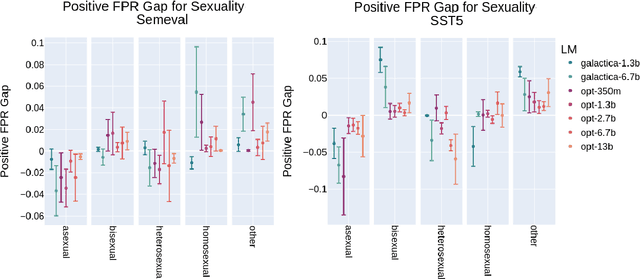
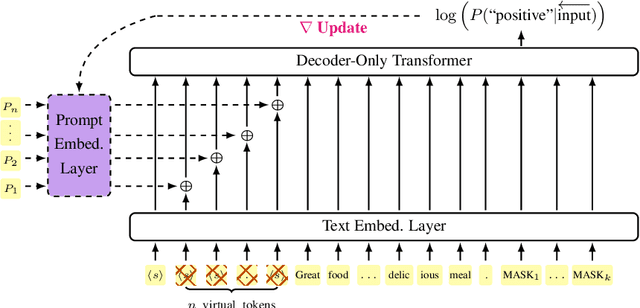
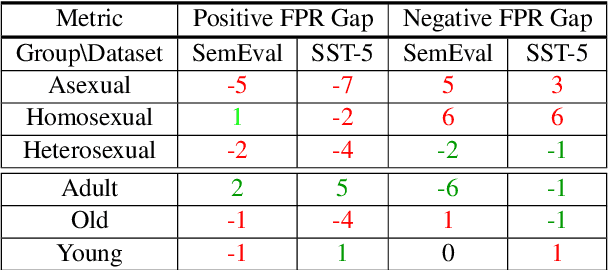
Prompting large language models has gained immense popularity in recent years due to the advantage of producing good results even without the need for labelled data. However, this requires prompt tuning to get optimal prompts that lead to better model performances. In this paper, we explore the use of soft-prompt tuning on sentiment classification task to quantify the biases of large language models (LLMs) such as Open Pre-trained Transformers (OPT) and Galactica language model. Since these models are trained on real-world data that could be prone to bias toward certain groups of populations, it is important to identify these underlying issues. Using soft-prompts to evaluate bias gives us the extra advantage of avoiding the human-bias injection that can be caused by manually designed prompts. We check the model biases on different sensitive attributes using the group fairness (bias) and find interesting bias patterns. Since LLMs have been used in the industry in various applications, it is crucial to identify the biases before deploying these models in practice. We open-source our pipeline and encourage industry researchers to adapt our work to their use cases.
MLHOps: Machine Learning for Healthcare Operations
May 04, 2023



Machine Learning Health Operations (MLHOps) is the combination of processes for reliable, efficient, usable, and ethical deployment and maintenance of machine learning models in healthcare settings. This paper provides both a survey of work in this area and guidelines for developers and clinicians to deploy and maintain their own models in clinical practice. We cover the foundational concepts of general machine learning operations, describe the initial setup of MLHOps pipelines (including data sources, preparation, engineering, and tools). We then describe long-term monitoring and updating (including data distribution shifts and model updating) and ethical considerations (including bias, fairness, interpretability, and privacy). This work therefore provides guidance across the full pipeline of MLHOps from conception to initial and ongoing deployment.
Bringing the State-of-the-Art to Customers: A Neural Agent Assistant Framework for Customer Service Support
Feb 07, 2023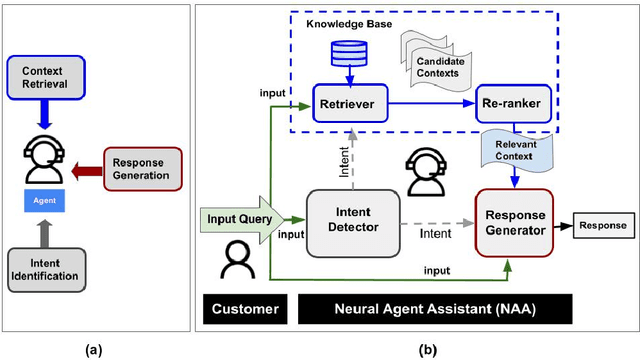
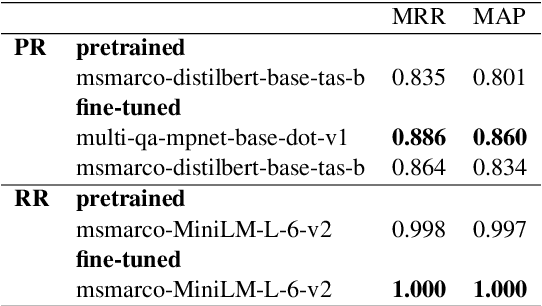
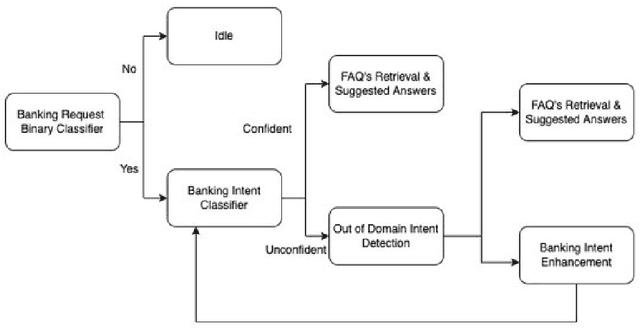
Building Agent Assistants that can help improve customer service support requires inputs from industry users and their customers, as well as knowledge about state-of-the-art Natural Language Processing (NLP) technology. We combine expertise from academia and industry to bridge the gap and build task/domain-specific Neural Agent Assistants (NAA) with three high-level components for: (1) Intent Identification, (2) Context Retrieval, and (3) Response Generation. In this paper, we outline the pipeline of the NAA's core system and also present three case studies in which three industry partners successfully adapt the framework to find solutions to their unique challenges. Our findings suggest that a collaborative process is instrumental in spurring the development of emerging NLP models for Conversational AI tasks in industry. The full reference implementation code and results are available at \url{https://github.com/VectorInstitute/NAA}
An Experimental Evaluation of Transformer-based Language Models in the Biomedical Domain
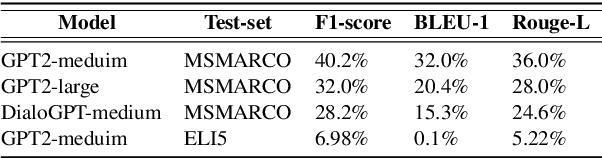
Dec 31, 2020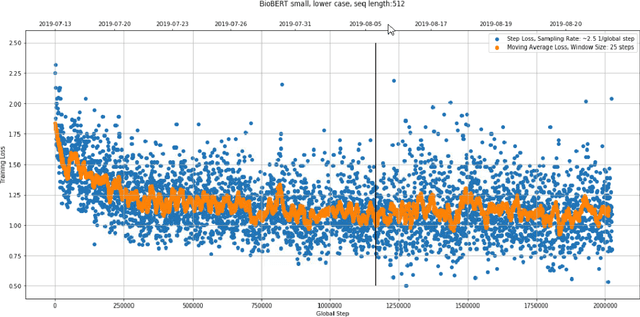
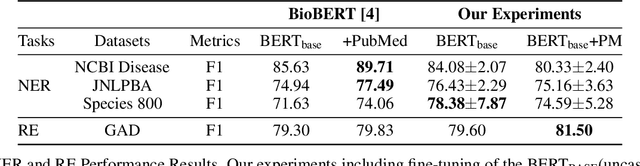
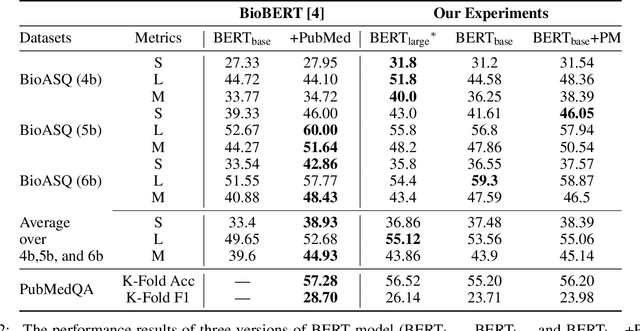

With the growing amount of text in health data, there have been rapid advances in large pre-trained models that can be applied to a wide variety of biomedical tasks with minimal task-specific modifications. Emphasizing the cost of these models, which renders technical replication challenging, this paper summarizes experiments conducted in replicating BioBERT and further pre-training and careful fine-tuning in the biomedical domain. We also investigate the effectiveness of domain-specific and domain-agnostic pre-trained models across downstream biomedical NLP tasks. Our finding confirms that pre-trained models can be impactful in some downstream NLP tasks (QA and NER) in the biomedical domain; however, this improvement may not justify the high cost of domain-specific pre-training.