 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhancing Diversity in Multi-objective Feature Selection
Jul 25, 2024Feature selection plays a pivotal role in the data preprocessing and model-building pipeline, significantly enhancing model performance, interpretability, and resource efficiency across diverse domains. In population-based optimization methods, the generation of diverse individuals holds utmost importance for adequately exploring the problem landscape, particularly in highly multi-modal multi-objective optimization problems. Our study reveals that, in line with findings from several prior research papers, commonly employed crossover and mutation operations lack the capability to generate high-quality diverse individuals and tend to become confined to limited areas around various local optima. This paper introduces an augmentation to the diversity of the population in the well-established multi-objective scheme of the genetic algorithm, NSGA-II. This enhancement is achieved through two key components: the genuine initialization method and the substitution of the worst individuals with new randomly generated individuals as a re-initialization approach in each generation. The proposed multi-objective feature selection method undergoes testing on twelve real-world classification problems, with the number of features ranging from 2,400 to nearly 50,000. The results demonstrate that replacing the last front of the population with an equivalent number of new random individuals generated using the genuine initialization method and featuring a limited number of features substantially improves the population's quality and, consequently, enhances the performance of the multi-objective algorithm.
Multi-objective Binary Coordinate Search for Feature Selection
Feb 20, 2024



A supervised feature selection method selects an appropriate but concise set of features to differentiate classes, which is highly expensive for large-scale datasets. Therefore, feature selection should aim at both minimizing the number of selected features and maximizing the accuracy of classification, or any other task. However, this crucial task is computationally highly demanding on many real-world datasets and requires a very efficient algorithm to reach a set of optimal features with a limited number of fitness evaluations. For this purpose, we have proposed the binary multi-objective coordinate search (MOCS) algorithm to solve large-scale feature selection problems. To the best of our knowledge, the proposed algorithm in this paper is the first multi-objective coordinate search algorithm. In this method, we generate new individuals by flipping a variable of the candidate solutions on the Pareto front. This enables us to investigate the effectiveness of each feature in the corresponding subset. In fact, this strategy can play the role of crossover and mutation operators to generate distinct subsets of features. The reported results indicate the significant superiority of our method over NSGA-II, on five real-world large-scale datasets, particularly when the computing budget is limited. Moreover, this simple hyper-parameter-free algorithm can solve feature selection much faster and more efficiently than NSGA-II.
* 8 pages, 1 figure
Training Artificial Neural Networks by Coordinate Search Algorithm
Feb 20, 2024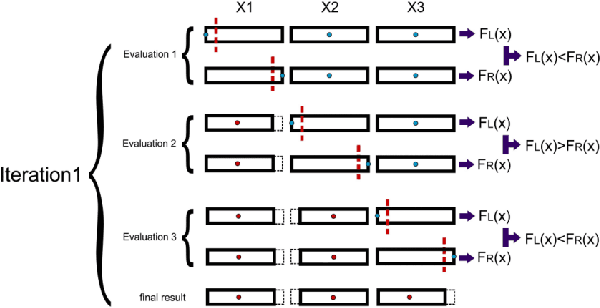
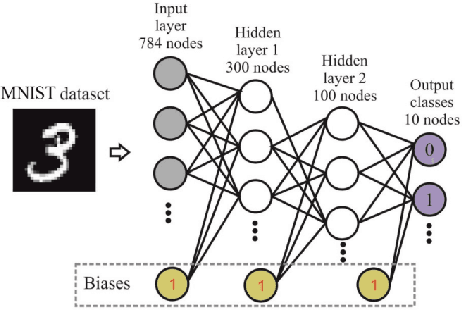
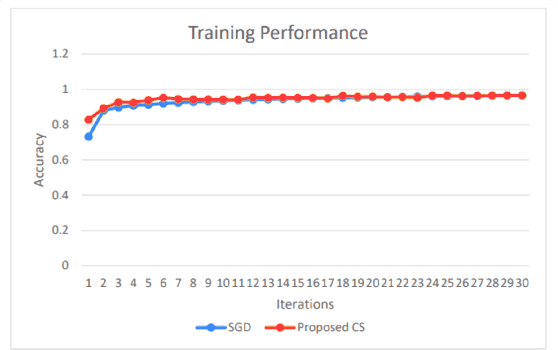
Training Artificial Neural Networks poses a challenging and critical problem in machine learning. Despite the effectiveness of gradient-based learning methods, such as Stochastic Gradient Descent (SGD), in training neural networks, they do have several limitations. For instance, they require differentiable activation functions, and cannot optimize a model based on several independent non-differentiable loss functions simultaneously; for example, the F1-score, which is used during testing, can be used during training when a gradient-free optimization algorithm is utilized. Furthermore, the training in any DNN can be possible with a small size of the training dataset. To address these concerns, we propose an efficient version of the gradient-free Coordinate Search (CS) algorithm, an instance of General Pattern Search methods, for training neural networks. The proposed algorithm can be used with non-differentiable activation functions and tailored to multi-objective/multi-loss problems. Finding the optimal values for weights of ANNs is a large-scale optimization problem. Therefore instead of finding the optimal value for each variable, which is the common technique in classical CS, we accelerate optimization and convergence by bundling the weights. In fact, this strategy is a form of dimension reduction for optimization problems. Based on the experimental results, the proposed method, in some cases, outperforms the gradient-based approach, particularly, in situations with insufficient labeled training data. The performance plots demonstrate a high convergence rate, highlighting the capability of our suggested method to find a reasonable solution with fewer function calls. As of now, the only practical and efficient way of training ANNs with hundreds of thousands of weights is gradient-based algorithms such as SGD or Adam. In this paper we introduce an alternative method for training ANN.
* 7 pages, 9 figures
Compact NSGA-II for Multi-objective Feature Selection
Feb 20, 2024



Feature selection is an expensive challenging task in machine learning and data mining aimed at removing irrelevant and redundant features. This contributes to an improvement in classification accuracy, as well as the budget and memory requirements for classification, or any other post-processing task conducted after feature selection. In this regard, we define feature selection as a multi-objective binary optimization task with the objectives of maximizing classification accuracy and minimizing the number of selected features. In order to select optimal features, we have proposed a binary Compact NSGA-II (CNSGA-II) algorithm. Compactness represents the population as a probability distribution to enhance evolutionary algorithms not only to be more memory-efficient but also to reduce the number of fitness evaluations. Instead of holding two populations during the optimization process, our proposed method uses several Probability Vectors (PVs) to generate new individuals. Each PV efficiently explores a region of the search space to find non-dominated solutions instead of generating candidate solutions from a small population as is the common approach in most evolutionary algorithms. To the best of our knowledge, this is the first compact multi-objective algorithm proposed for feature selection. The reported results for expensive optimization cases with a limited budget on five datasets show that the CNSGA-II performs more efficiently than the well-known NSGA-II method in terms of the hypervolume (HV) performance metric requiring less memory. The proposed method and experimental results are explained and analyzed in detail.
* 8 pages, 2 figures
Soft-prompt Tuning for Large Language Models to Evaluate Bias
Jun 07, 2023
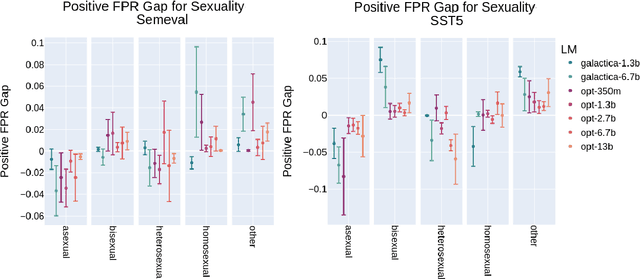
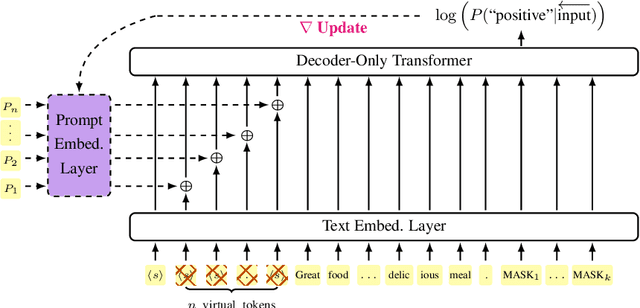
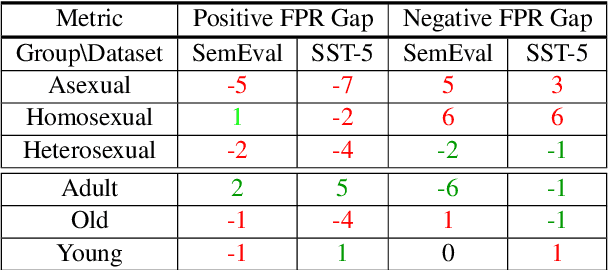
Prompting large language models has gained immense popularity in recent years due to the advantage of producing good results even without the need for labelled data. However, this requires prompt tuning to get optimal prompts that lead to better model performances. In this paper, we explore the use of soft-prompt tuning on sentiment classification task to quantify the biases of large language models (LLMs) such as Open Pre-trained Transformers (OPT) and Galactica language model. Since these models are trained on real-world data that could be prone to bias toward certain groups of populations, it is important to identify these underlying issues. Using soft-prompts to evaluate bias gives us the extra advantage of avoiding the human-bias injection that can be caused by manually designed prompts. We check the model biases on different sensitive attributes using the group fairness (bias) and find interesting bias patterns. Since LLMs have been used in the industry in various applications, it is crucial to identify the biases before deploying these models in practice. We open-source our pipeline and encourage industry researchers to adapt our work to their use cases.