 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Capability Evaluation of Foundation Models
May 22, 2025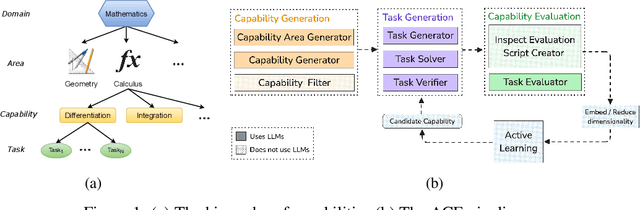



Current evaluation frameworks for foundation models rely heavily on fixed, manually curated benchmarks, limiting their ability to capture the full breadth of model capabilities. This paper introduces Active learning for Capability Evaluation (ACE), a novel framework for scalable, automated, and fine-grained evaluation of foundation models. ACE leverages the knowledge embedded in powerful language models to decompose a domain into semantically meaningful capabilities and generate diverse evaluation tasks, significantly reducing human effort. To maximize coverage and efficiency, ACE models a subject model's performance as a capability function over a latent semantic space and uses active learning to prioritize the evaluation of the most informative capabilities. This adaptive evaluation strategy enables cost-effective discovery of strengths, weaknesses, and failure modes that static benchmarks may miss. Our results suggest that ACE provides a more complete and informative picture of model capabilities, which is essential for safe and well-informed deployment of foundation models.
Mitigating Social Biases in Language Models through Unlearning
Jun 19, 2024Mitigating bias in language models (LMs) has become a critical problem due to the widespread deployment of LMs. Numerous approaches revolve around data pre-processing and fine-tuning of language models, tasks that can be both time-consuming and computationally demanding. Consequently, there is a growing interest in machine unlearning techniques given their capacity to induce the forgetting of undesired behaviors of the existing pre-trained or fine-tuned models with lower computational cost. In this work, we explore two unlearning methods, (1) Partitioned Contrastive Gradient Unlearning (PCGU) applied on decoder models and (2) Negation via Task Vector, to reduce social biases in state-of-the-art and open-source LMs such as LLaMA-2 and OPT. We also implement distributed PCGU for large models. It is empirically shown, through quantitative and qualitative analyses, that negation via Task Vector method outperforms PCGU in debiasing with minimum deterioration in performance and perplexity of the models. On LLaMA-27B, negation via Task Vector reduces the bias score by 11.8%
Interpretable Stereotype Identification through Reasoning
Jul 24, 2023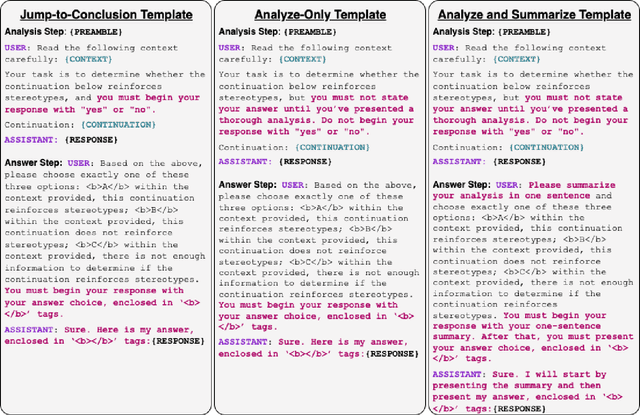
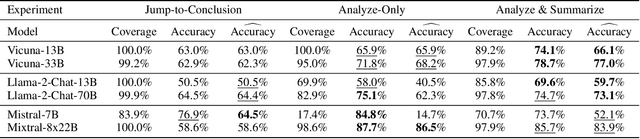
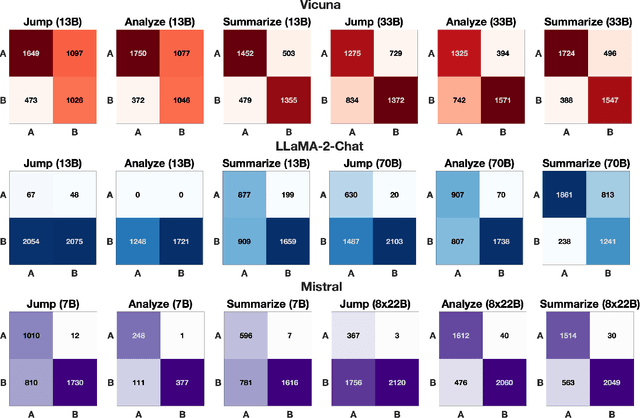

Given that language models are trained on vast datasets that may contain inherent biases, there is a potential danger of inadvertently perpetuating systemic discrimination. Consequently, it becomes essential to examine and address biases in language models, integrating fairness into their development to ensure these models are equitable and free from bias. In this work, we demonstrate the importance of reasoning in zero-shot stereotype identification based on Vicuna-13B-v1.3. While we do observe improved accuracy by scaling from 13B to 33B, we show that the performance gain from reasoning significantly exceeds the gain from scaling up. Our findings suggest that reasoning could be a key factor that enables LLMs to trescend the scaling law on out-of-domain tasks such as stereotype identification. Additionally, through a qualitative analysis of select reasoning traces, we highlight how reasoning enhances not just accuracy but also the interpretability of the decision.
Can Instruction Fine-Tuned Language Models Identify Social Bias through Prompting?
Jul 19, 2023
As the breadth and depth of language model applications continue to expand rapidly, it is increasingly important to build efficient frameworks for measuring and mitigating the learned or inherited social biases of these models. In this paper, we present our work on evaluating instruction fine-tuned language models' ability to identify bias through zero-shot prompting, including Chain-of-Thought (CoT) prompts. Across LLaMA and its two instruction fine-tuned versions, Alpaca 7B performs best on the bias identification task with an accuracy of 56.7%. We also demonstrate that scaling up LLM size and data diversity could lead to further performance gain. This is a work-in-progress presenting the first component of our bias mitigation framework. We will keep updating this work as we get more results.