 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAutomated Capability Evaluation of Foundation Models
May 22, 2025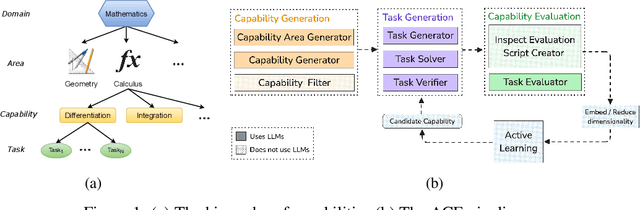



Current evaluation frameworks for foundation models rely heavily on fixed, manually curated benchmarks, limiting their ability to capture the full breadth of model capabilities. This paper introduces Active learning for Capability Evaluation (ACE), a novel framework for scalable, automated, and fine-grained evaluation of foundation models. ACE leverages the knowledge embedded in powerful language models to decompose a domain into semantically meaningful capabilities and generate diverse evaluation tasks, significantly reducing human effort. To maximize coverage and efficiency, ACE models a subject model's performance as a capability function over a latent semantic space and uses active learning to prioritize the evaluation of the most informative capabilities. This adaptive evaluation strategy enables cost-effective discovery of strengths, weaknesses, and failure modes that static benchmarks may miss. Our results suggest that ACE provides a more complete and informative picture of model capabilities, which is essential for safe and well-informed deployment of foundation models.
Online Federation For Mixtures of Proprietary Agents with Black-Box Encoders
Apr 30, 2025



Most industry-standard generative AIs and feature encoders are proprietary, offering only black-box access: their outputs are observable, but their internal parameters and architectures remain hidden from the end-user. This black-box access is especially limiting when constructing mixture-of-expert type ensemble models since the user cannot optimize each proprietary AI's internal parameters. Our problem naturally lends itself to a non-competitive game-theoretic lens where each proprietary AI (agent) is inherently competing against the other AI agents, with this competition arising naturally due to their obliviousness of the AI's to their internal structure. In contrast, the user acts as a central planner trying to synchronize the ensemble of competing AIs. We show the existence of the unique Nash equilibrium in the online setting, which we even compute in closed-form by eliciting a feedback mechanism between any given time series and the sequence generated by each (proprietary) AI agent. Our solution is implemented as a decentralized, federated-learning algorithm in which each agent optimizes their structure locally on their machine without ever releasing any internal structure to the others. We obtain refined expressions for pre-trained models such as transformers, random feature models, and echo-state networks. Our ``proprietary federated learning'' algorithm is implemented on a range of real-world and synthetic time-series benchmarks. It achieves orders-of-magnitude improvements in predictive accuracy over natural benchmarks, of which there are surprisingly few due to this natural problem still being largely unexplored.
Developing Safe and Responsible Large Language Models -- A Comprehensive Framework
Apr 01, 2024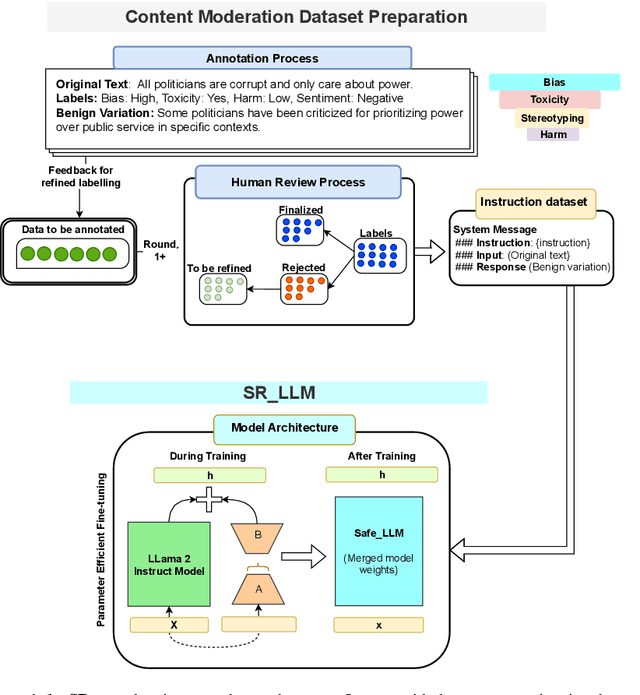
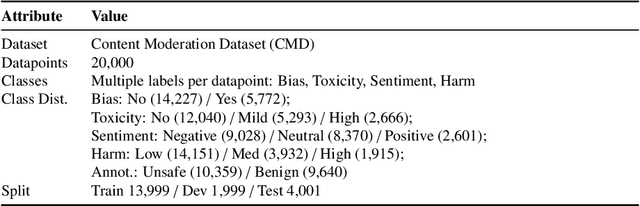

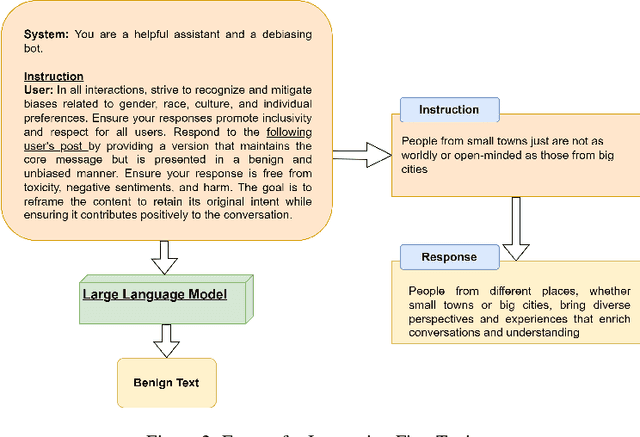
Given the growing concerns around the safety and risks of Large Language Models (LLMs), it is essential to develop methods for mitigating these issues. We introduce Safe and Responsible Large Language Model (SR$_{\text{LLM}}$) , a model designed to enhance the safety of language generation using LLMs. Our approach incorporates a comprehensive LLM safety risk taxonomy and utilizes a dataset annotated by experts that align with this taxonomy. SR$_{\text{LLM}}$ is designed to identify potentially unsafe content and produce benign variations. It employs instruction-based and parameter-efficient fine-tuning methods, making the model not only effective in enhancing safety but also resource-efficient and straightforward to adjust. Through our testing on five benchmark datasets and two proprietary datasets, we observed notable reductions in the generation of unsafe content. Moreover, following the implementation of safety measures, there was a significant improvement in the production of safe content. We detail our fine-tuning processes and how we benchmark safety for SR$_{\text{LLM}}$ with the community engagement and promote the responsible advancement of LLMs. All the data and code are available anonymous at https://github.com/shainarazavi/Safe-Responsible-LLM .
FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets
Sep 28, 2023



Federated learning (FL) is increasingly being recognized as a key approach to overcoming the data silos that so frequently obstruct the training and deployment of machine-learning models in clinical settings. This work contributes to a growing body of FL research specifically focused on clinical applications along three important directions. First, an extension of the FENDA method (Kim et al., 2016) to the FL setting is proposed. Experiments conducted on the FLamby benchmarks (du Terrail et al., 2022a) and GEMINI datasets (Verma et al., 2017) show that the approach is robust to heterogeneous clinical data and often outperforms existing global and personalized FL techniques. Further, the experimental results represent substantive improvements over the original FLamby benchmarks and expand such benchmarks to include evaluation of personalized FL methods. Finally, we advocate for a comprehensive checkpointing and evaluation framework for FL to better reflect practical settings and provide multiple baselines for comparison.