 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInterpretable Fine-Gray Deep Survival Model for Competing Risks: Predicting Post-Discharge Foot Complications for Diabetic Patients in Ontario
Nov 16, 2025Model interpretability is crucial for establishing AI safety and clinician trust in medical applications for example, in survival modelling with competing risks. Recent deep learning models have attained very good predictive performance but their limited transparency, being black-box models, hinders their integration into clinical practice. To address this gap, we propose an intrinsically interpretable survival model called CRISPNAM-FG. Leveraging the structure of Neural Additive Models (NAMs) with separate projection vectors for each risk, our approach predicts the Cumulative Incidence Function using the Fine-Gray formulation, achieving high predictive power with intrinsically transparent and auditable predictions. We validated the model on several benchmark datasets and applied our model to predict future foot complications in diabetic patients across 29 Ontario hospitals (2016-2023). Our method achieves competitive performance compared to other deep survival models while providing transparency through shape functions and feature importance plots.
Reliably detecting model failures in deployment without labels
Jun 05, 2025The distribution of data changes over time; models operating operating in dynamic environments need retraining. But knowing when to retrain, without access to labels, is an open challenge since some, but not all shifts degrade model performance. This paper formalizes and addresses the problem of post-deployment deterioration (PDD) monitoring. We propose D3M, a practical and efficient monitoring algorithm based on the disagreement of predictive models, achieving low false positive rates under non-deteriorating shifts and provides sample complexity bounds for high true positive rates under deteriorating shifts. Empirical results on both standard benchmark and a real-world large-scale internal medicine dataset demonstrate the effectiveness of the framework and highlight its viability as an alert mechanism for high-stakes machine learning pipelines.
Decentralised, Collaborative, and Privacy-preserving Machine Learning for Multi-Hospital Data
Jan 31, 2024Machine Learning (ML) has demonstrated its great potential on medical data analysis. Large datasets collected from diverse sources and settings are essential for ML models in healthcare to achieve better accuracy and generalizability. Sharing data across different healthcare institutions is challenging because of complex and varying privacy and regulatory requirements. Hence, it is hard but crucial to allow multiple parties to collaboratively train an ML model leveraging the private datasets available at each party without the need for direct sharing of those datasets or compromising the privacy of the datasets through collaboration. In this paper, we address this challenge by proposing Decentralized, Collaborative, and Privacy-preserving ML for Multi-Hospital Data (DeCaPH). It offers the following key benefits: (1) it allows different parties to collaboratively train an ML model without transferring their private datasets; (2) it safeguards patient privacy by limiting the potential privacy leakage arising from any contents shared across the parties during the training process; and (3) it facilitates the ML model training without relying on a centralized server. We demonstrate the generalizability and power of DeCaPH on three distinct tasks using real-world distributed medical datasets: patient mortality prediction using electronic health records, cell-type classification using single-cell human genomes, and pathology identification using chest radiology images. We demonstrate that the ML models trained with DeCaPH framework have an improved utility-privacy trade-off, showing it enables the models to have good performance while preserving the privacy of the training data points. In addition, the ML models trained with DeCaPH framework in general outperform those trained solely with the private datasets from individual parties, showing that DeCaPH enhances the model generalizability.
FENDA-FL: Personalized Federated Learning on Heterogeneous Clinical Datasets
Sep 28, 2023



Federated learning (FL) is increasingly being recognized as a key approach to overcoming the data silos that so frequently obstruct the training and deployment of machine-learning models in clinical settings. This work contributes to a growing body of FL research specifically focused on clinical applications along three important directions. First, an extension of the FENDA method (Kim et al., 2016) to the FL setting is proposed. Experiments conducted on the FLamby benchmarks (du Terrail et al., 2022a) and GEMINI datasets (Verma et al., 2017) show that the approach is robust to heterogeneous clinical data and often outperforms existing global and personalized FL techniques. Further, the experimental results represent substantive improvements over the original FLamby benchmarks and expand such benchmarks to include evaluation of personalized FL methods. Finally, we advocate for a comprehensive checkpointing and evaluation framework for FL to better reflect practical settings and provide multiple baselines for comparison.
Assessing the impact of emergency department short stay units using length-of-stay prediction and discrete event simulation
Aug 04, 2023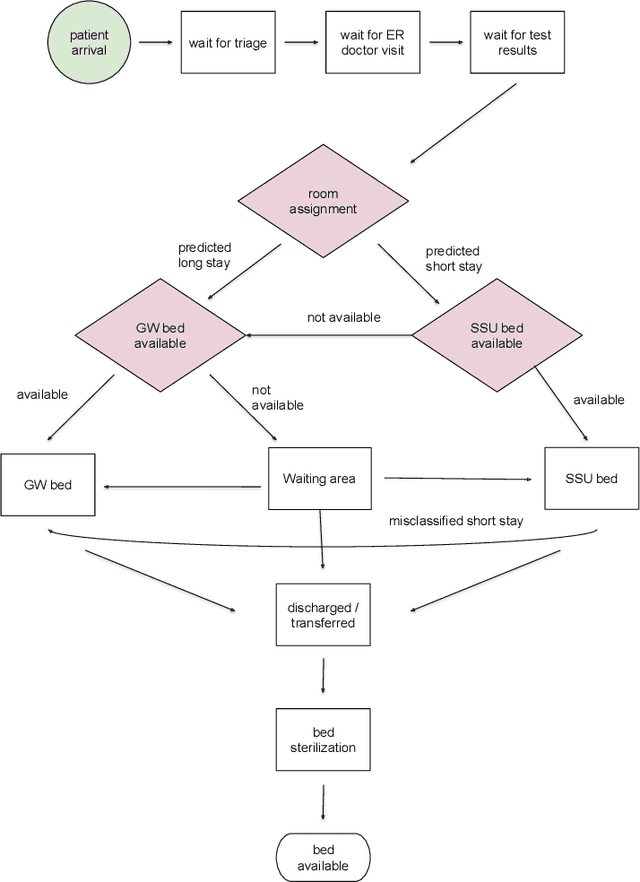
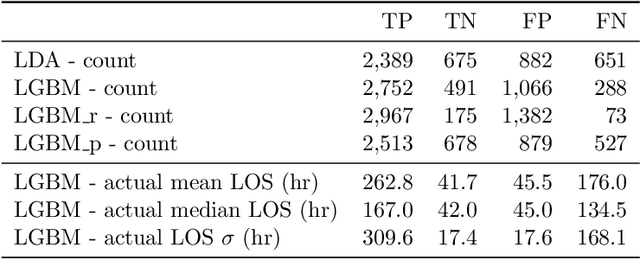
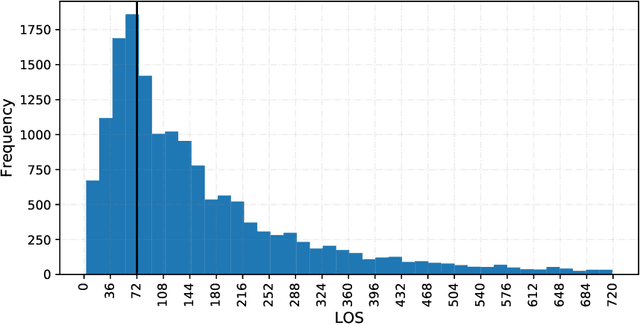
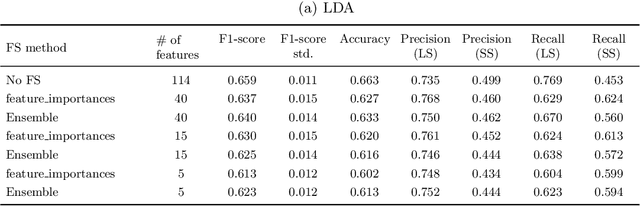
Accurately predicting hospital length-of-stay at the time a patient is admitted to hospital may help guide clinical decision making and resource allocation. In this study we aim to build a decision support system that predicts hospital length-of-stay for patients admitted to general internal medicine from the emergency department. We conduct an exploratory data analysis and employ feature selection methods to identify the attributes that result in the best predictive performance. We also develop a discrete-event simulation model to assess the performances of the prediction models in a practical setting. Our results show that the recommendation performances of the proposed approaches are generally acceptable and do not benefit from the feature selection. Further, the results indicate that hospital length-of-stay could be predicted with reasonable accuracy (e.g., AUC value for classifying short and long stay patients is 0.69) using patient admission demographics, laboratory test results, diagnostic imaging, vital signs and clinical documentation.