 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeJoint Matching and Pricing for Crowd-shipping with In-store Customers
Jul 02, 2025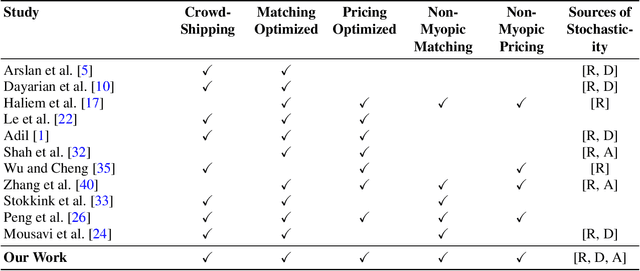
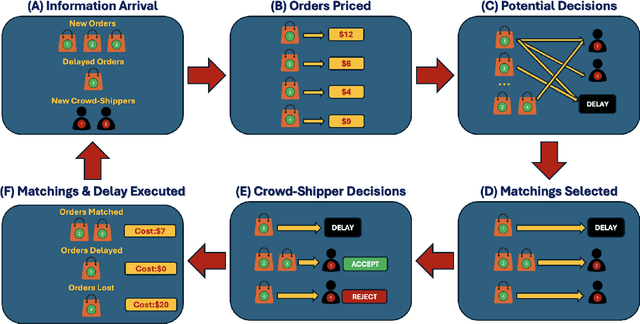
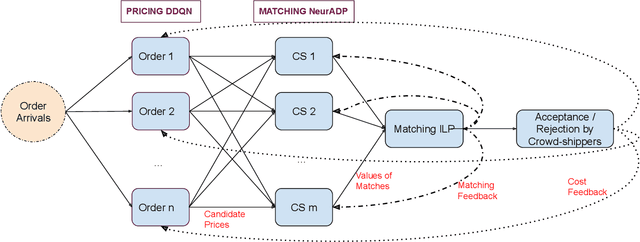

This paper examines the use of in-store customers as delivery couriers in a centralized crowd-shipping system, targeting the growing need for efficient last-mile delivery in urban areas. We consider a brick-and-mortar retail setting where shoppers are offered compensation to deliver time-sensitive online orders. To manage this process, we propose a Markov Decision Process (MDP) model that captures key uncertainties, including the stochastic arrival of orders and crowd-shippers, and the probabilistic acceptance of delivery offers. Our solution approach integrates Neural Approximate Dynamic Programming (NeurADP) for adaptive order-to-shopper assignment with a Deep Double Q-Network (DDQN) for dynamic pricing. This joint optimization strategy enables multi-drop routing and accounts for offer acceptance uncertainty, aligning more closely with real-world operations. Experimental results demonstrate that the integrated NeurADP + DDQN policy achieves notable improvements in delivery cost efficiency, with up to 6.7\% savings over NeurADP with fixed pricing and approximately 18\% over myopic baselines. We also show that allowing flexible delivery delays and enabling multi-destination routing further reduces operational costs by 8\% and 17\%, respectively. These findings underscore the advantages of dynamic, forward-looking policies in crowd-shipping systems and offer practical guidance for urban logistics operators.
Optimizing Hard-to-Place Kidney Allocation: A Machine Learning Approach to Center Ranking
Oct 10, 2024

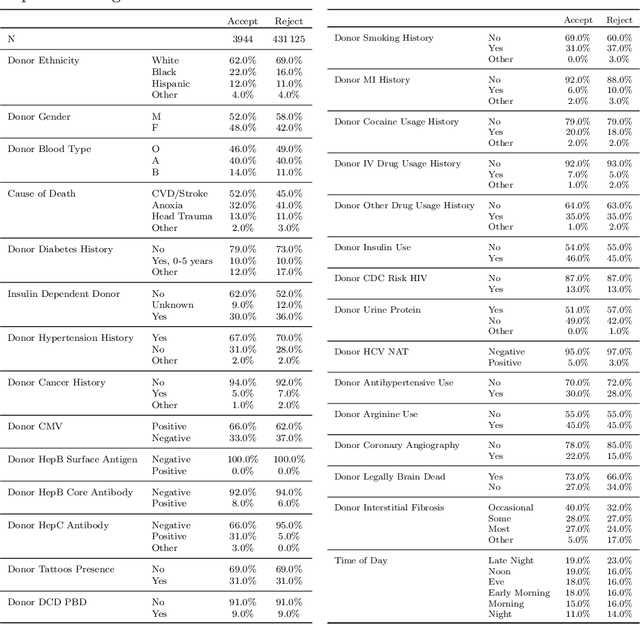

Kidney transplantation is the preferred treatment for end-stage renal disease, yet the scarcity of donors and inefficiencies in allocation systems create major bottlenecks, resulting in prolonged wait times and alarming mortality rates. Despite their severe scarcity, timely and effective interventions to prevent non-utilization of life-saving organs remain inadequate. Expedited out-of-sequence placement of hard-to-place kidneys to centers with the highest likelihood of utilizing them has been recommended in the literature as an effective strategy to improve placement success. Nevertheless, current attempts towards this practice is non-standardized and heavily rely on the subjective judgment of the decision-makers. This paper proposes a novel data-driven, machine learning-based ranking system for allocating hard-to-place kidneys to centers with a higher likelihood of accepting and successfully transplanting them. Using the national deceased donor kidney offer and transplant datasets, we construct a unique dataset with donor-, center-, and patient-specific features. We propose a data-driven out-of-sequence placement policy that utilizes machine learning models to predict the acceptance probability of a given kidney by a set of transplant centers, ranking them accordingly based on their likelihood of acceptance. Our experiments demonstrate that the proposed policy can reduce the average number of centers considered before placement by fourfold for all kidneys and tenfold for hard-to-place kidneys. This significant reduction indicates that our method can improve the utilization of hard-to-place kidneys and accelerate their acceptance, ultimately reducing patient mortality and the risk of graft failure. Further, we utilize machine learning interpretability tools to provide insights into factors influencing the kidney allocation decisions.
Dynamic AGV Task Allocation in Intelligent Warehouses
Dec 26, 2023This paper explores the integration of Automated Guided Vehicles (AGVs) in warehouse order picking, a crucial and cost-intensive aspect of warehouse operations. The booming AGV industry, accelerated by the COVID-19 pandemic, is witnessing widespread adoption due to its efficiency, reliability, and cost-effectiveness in automating warehouse tasks. This paper focuses on enhancing the picker-to-parts system, prevalent in small to medium-sized warehouses, through the strategic use of AGVs. We discuss the benefits and applications of AGVs in various warehouse tasks, highlighting their transformative potential in improving operational efficiency. We examine the deployment of AGVs by leading companies in the industry, showcasing their varied functionalities in warehouse management. Addressing the gap in research on optimizing operational performance in hybrid environments where humans and AGVs coexist, our study delves into a dynamic picker-to-parts warehouse scenario. We propose a novel approach Neural Approximate Dynamic Programming approach for coordinating a mixed team of human and AGV workers, aiming to maximize order throughput and operational efficiency. This involves innovative solutions for non-myopic decision making, order batching, and battery management. We also discuss the integration of advanced robotics technology in automating the complete order-picking process. Through a comprehensive numerical study, our work offers valuable insights for managing a heterogeneous workforce in a hybrid warehouse setting, contributing significantly to the field of warehouse automation and logistics.
Neural Approximate Dynamic Programming for the Ultra-fast Order Dispatching Problem
Nov 21, 2023Same-Day Delivery (SDD) services aim to maximize the fulfillment of online orders while minimizing delivery delays but are beset by operational uncertainties such as those in order volumes and courier planning. Our work aims to enhance the operational efficiency of SDD by focusing on the ultra-fast Order Dispatching Problem (ODP), which involves matching and dispatching orders to couriers within a centralized warehouse setting, and completing the delivery within a strict timeline (e.g., within minutes). We introduce important extensions to ultra-fast ODP such as order batching and explicit courier assignments to provide a more realistic representation of dispatching operations and improve delivery efficiency. As a solution method, we primarily focus on NeurADP, a methodology that combines Approximate Dynamic Programming (ADP) and Deep Reinforcement Learning (DRL), and our work constitutes the first application of NeurADP outside of the ride-pool matching problem. NeurADP is particularly suitable for ultra-fast ODP as it addresses complex one-to-many matching and routing intricacies through a neural network-based VFA that captures high-dimensional problem dynamics without requiring manual feature engineering as in generic ADP methods. We test our proposed approach using four distinct realistic datasets tailored for ODP and compare the performance of NeurADP against myopic and DRL baselines by also making use of non-trivial bounds to assess the quality of the policies. Our numerical results indicate that the inclusion of order batching and courier queues enhances the efficiency of delivery operations and that NeurADP significantly outperforms other methods. Detailed sensitivity analysis with important parameters confirms the robustness of NeurADP under different scenarios, including variations in courier numbers, spatial setup, vehicle capacity, and permitted delay time.
Assessing the impact of emergency department short stay units using length-of-stay prediction and discrete event simulation
Aug 04, 2023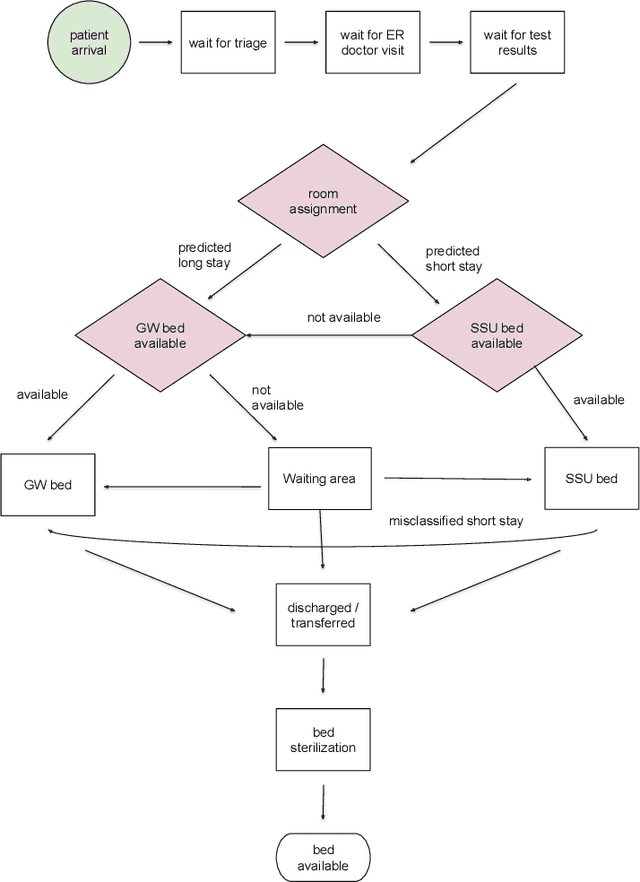
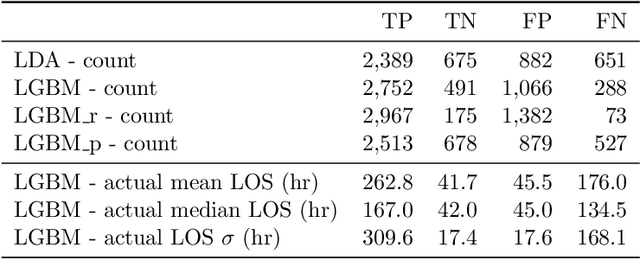
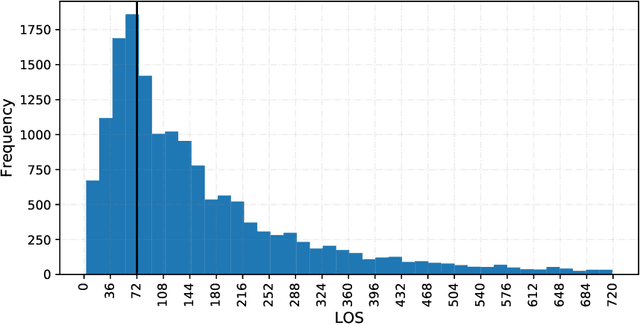
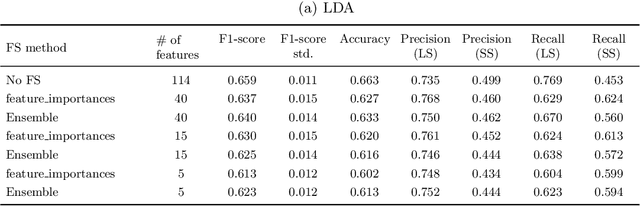
Accurately predicting hospital length-of-stay at the time a patient is admitted to hospital may help guide clinical decision making and resource allocation. In this study we aim to build a decision support system that predicts hospital length-of-stay for patients admitted to general internal medicine from the emergency department. We conduct an exploratory data analysis and employ feature selection methods to identify the attributes that result in the best predictive performance. We also develop a discrete-event simulation model to assess the performances of the prediction models in a practical setting. Our results show that the recommendation performances of the proposed approaches are generally acceptable and do not benefit from the feature selection. Further, the results indicate that hospital length-of-stay could be predicted with reasonable accuracy (e.g., AUC value for classifying short and long stay patients is 0.69) using patient admission demographics, laboratory test results, diagnostic imaging, vital signs and clinical documentation.
Data Augmentation for Conflict and Duplicate Detection in Software Engineering Sentence Pairs
May 16, 2023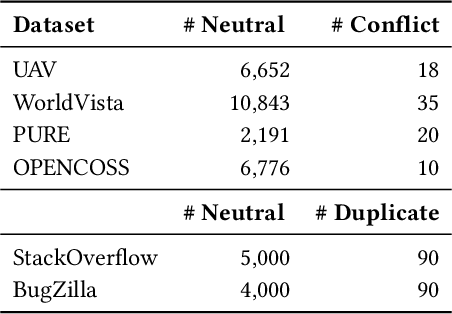
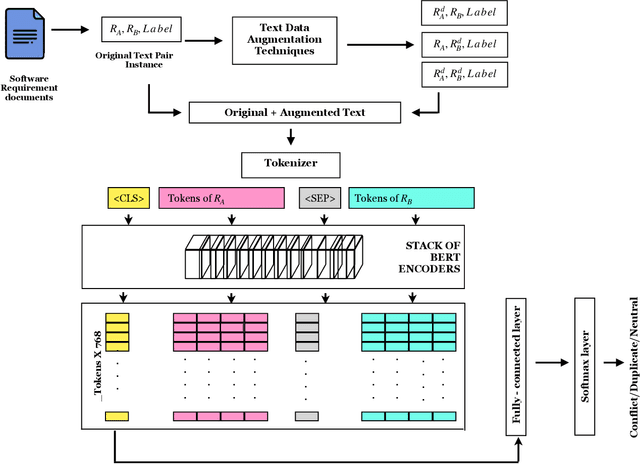

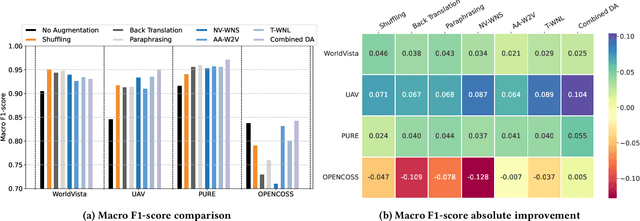
This paper explores the use of text data augmentation techniques to enhance conflict and duplicate detection in software engineering tasks through sentence pair classification. The study adapts generic augmentation techniques such as shuffling, back translation, and paraphrasing and proposes new data augmentation techniques such as Noun-Verb Substitution, target-lemma replacement and Actor-Action Substitution for software requirement texts. A comprehensive empirical analysis is conducted on six software text datasets to identify conflicts and duplicates among sentence pairs. The results demonstrate that data augmentation techniques have a significant impact on the performance of all software pair text datasets. On the other hand, in cases where the datasets are relatively balanced, the use of augmentation techniques may result in a negative effect on the classification performance.
Explaining Exchange Rate Forecasts with Macroeconomic Fundamentals Using Interpretive Machine Learning
Mar 23, 2023The complexity and ambiguity of financial and economic systems, along with frequent changes in the economic environment, have made it difficult to make precise predictions that are supported by theory-consistent explanations. Interpreting the prediction models used for forecasting important macroeconomic indicators is highly valuable for understanding relations among different factors, increasing trust towards the prediction models, and making predictions more actionable. In this study, we develop a fundamental-based model for the Canadian-U.S. dollar exchange rate within an interpretative framework. We propose a comprehensive approach using machine learning to predict the exchange rate and employ interpretability methods to accurately analyze the relationships among macroeconomic variables. Moreover, we implement an ablation study based on the output of the interpretations to improve the predictive accuracy of the models. Our empirical results show that crude oil, as Canada's main commodity export, is the leading factor that determines the exchange rate dynamics with time-varying effects. The changes in the sign and magnitude of the contributions of crude oil to the exchange rate are consistent with significant events in the commodity and energy markets and the evolution of the crude oil trend in Canada. Gold and the TSX stock index are found to be the second and third most important variables that influence the exchange rate. Accordingly, this analysis provides trustworthy and practical insights for policymakers and economists and accurate knowledge about the predictive model's decisions, which are supported by theoretical considerations.
Transfer learning for conflict and duplicate detection in software requirement pairs
Jan 09, 2023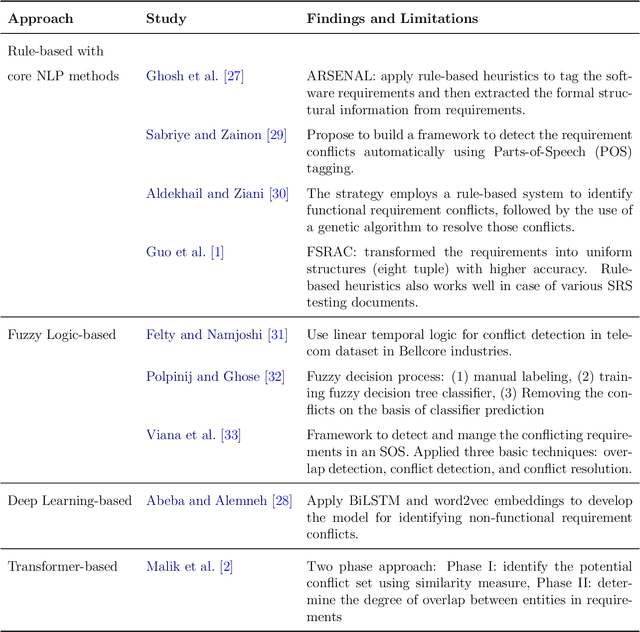
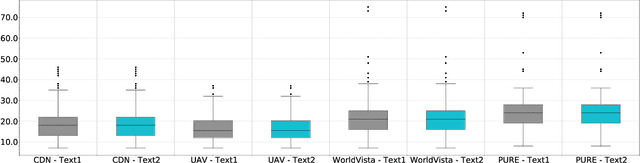
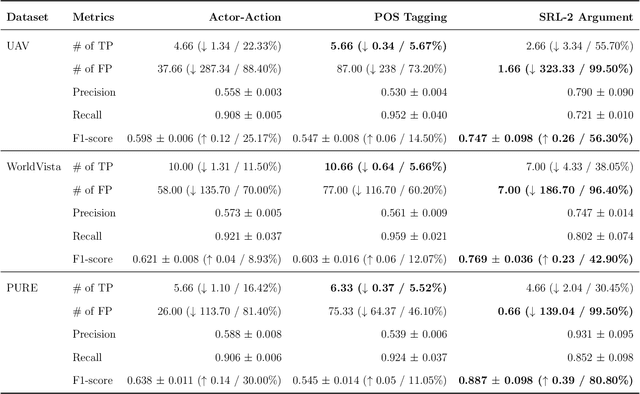
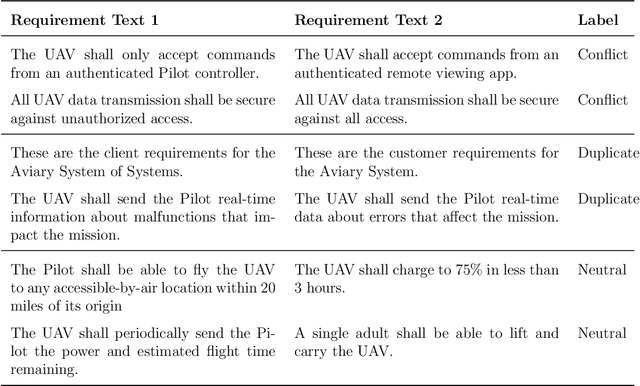
Consistent and holistic expression of software requirements is important for the success of software projects. In this study, we aim to enhance the efficiency of the software development processes by automatically identifying conflicting and duplicate software requirement specifications. We formulate the conflict and duplicate detection problem as a requirement pair classification task. We design a novel transformers-based architecture, SR-BERT, which incorporates Sentence-BERT and Bi-encoders for the conflict and duplicate identification task. Furthermore, we apply supervised multi-stage fine-tuning to the pre-trained transformer models. We test the performance of different transfer models using four different datasets. We find that sequentially trained and fine-tuned transformer models perform well across the datasets with SR-BERT achieving the best performance for larger datasets. We also explore the cross-domain performance of conflict detection models and adopt a rule-based filtering approach to validate the model classifications. Our analysis indicates that the sentence pair classification approach and the proposed transformer-based natural language processing strategies can contribute significantly to achieving automation in conflict and duplicate detection
DANLIP: Deep Autoregressive Networks for Locally Interpretable Probabilistic Forecasting
Jan 05, 2023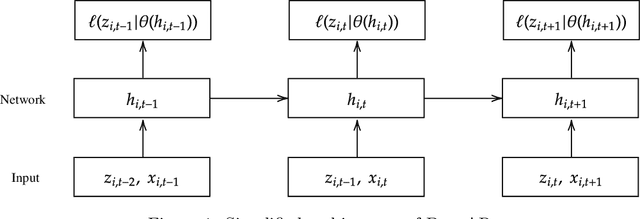
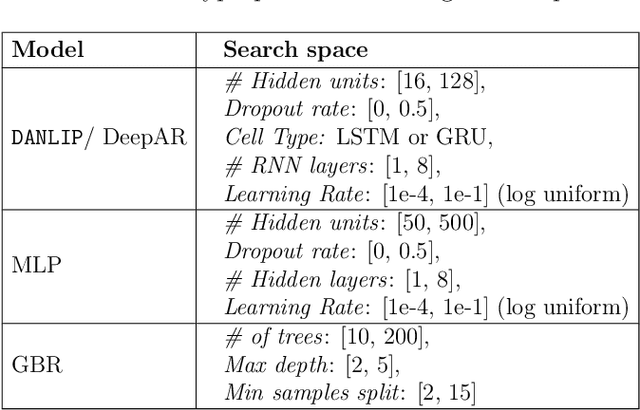
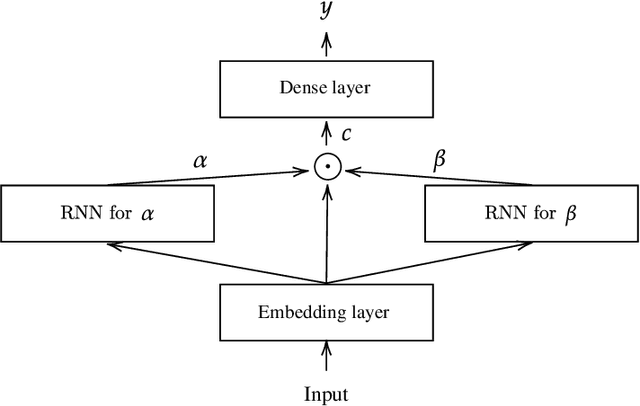
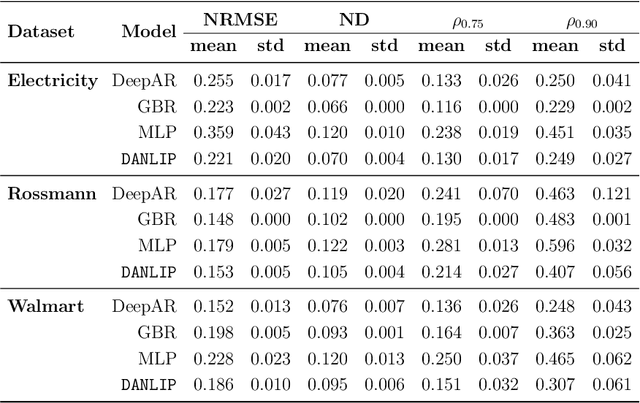
Despite the high performance of neural network-based time series forecasting methods, the inherent challenge in explaining their predictions has limited their applicability in certain application areas. Due to the difficulty in identifying causal relationships between the input and output of such black-box methods, they rarely have been adopted in domains such as legal and medical fields in which the reliability and interpretability of the results can be essential. In this paper, we propose \model, a novel deep learning-based probabilistic time series forecasting architecture that is intrinsically interpretable. We conduct experiments with multiple datasets and performance metrics and empirically show that our model is not only interpretable but also provides comparable performance to state-of-the-art probabilistic time series forecasting methods. Furthermore, we demonstrate that interpreting the parameters of the stochastic processes of interest can provide useful insights into several application areas.
A Concurrent CNN-RNN Approach for Multi-Step Wind Power Forecasting
Jan 02, 2023Wind power forecasting helps with the planning for the power systems by contributing to having a higher level of certainty in decision-making. Due to the randomness inherent to meteorological events (e.g., wind speeds), making highly accurate long-term predictions for wind power can be extremely difficult. One approach to remedy this challenge is to utilize weather information from multiple points across a geographical grid to obtain a holistic view of the wind patterns, along with temporal information from the previous power outputs of the wind farms. Our proposed CNN-RNN architecture combines convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract spatial and temporal information from multi-dimensional input data to make day-ahead predictions. In this regard, our method incorporates an ultra-wide learning view, combining data from multiple numerical weather prediction models, wind farms, and geographical locations. Additionally, we experiment with global forecasting approaches to understand the impact of training the same model over the datasets obtained from multiple different wind farms, and we employ a method where spatial information extracted from convolutional layers is passed to a tree ensemble (e.g., Light Gradient Boosting Machine (LGBM)) instead of fully connected layers. The results show that our proposed CNN-RNN architecture outperforms other models such as LGBM, Extra Tree regressor and linear regression when trained globally, but fails to replicate such performance when trained individually on each farm. We also observe that passing the spatial information from CNN to LGBM improves its performance, providing further evidence of CNN's spatial feature extraction capabilities.