 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANLIP: Deep Autoregressive Networks for Locally Interpretable Probabilistic Forecasting
Jan 05, 2023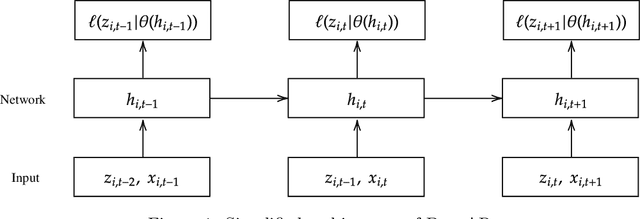
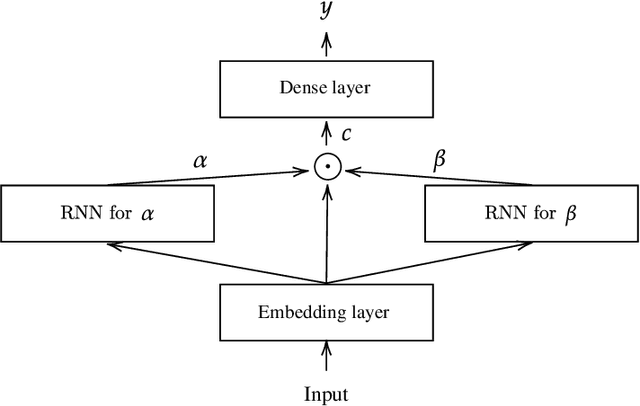
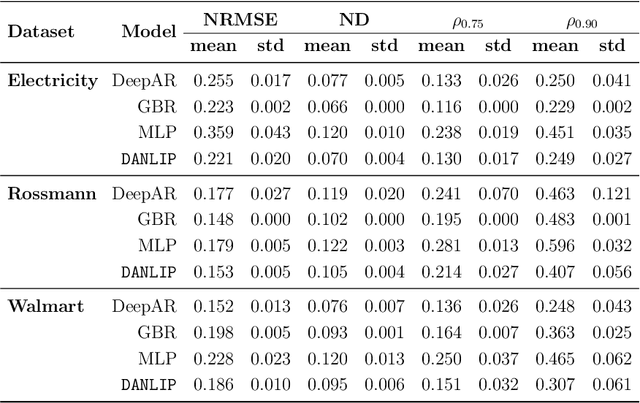
Despite the high performance of neural network-based time series forecasting methods, the inherent challenge in explaining their predictions has limited their applicability in certain application areas. Due to the difficulty in identifying causal relationships between the input and output of such black-box methods, they rarely have been adopted in domains such as legal and medical fields in which the reliability and interpretability of the results can be essential. In this paper, we propose \model, a novel deep learning-based probabilistic time series forecasting architecture that is intrinsically interpretable. We conduct experiments with multiple datasets and performance metrics and empirically show that our model is not only interpretable but also provides comparable performance to state-of-the-art probabilistic time series forecasting methods. Furthermore, we demonstrate that interpreting the parameters of the stochastic processes of interest can provide useful insights into several application areas.
Interpretable Time Series Clustering Using Local Explanations
Aug 01, 2022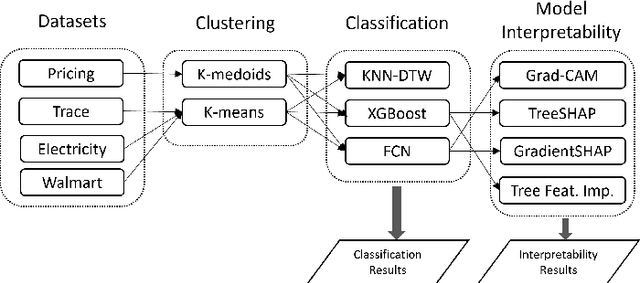
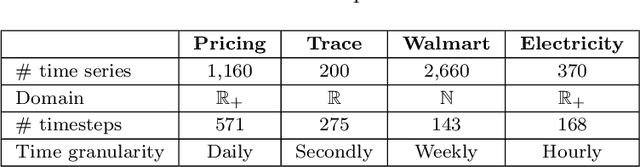
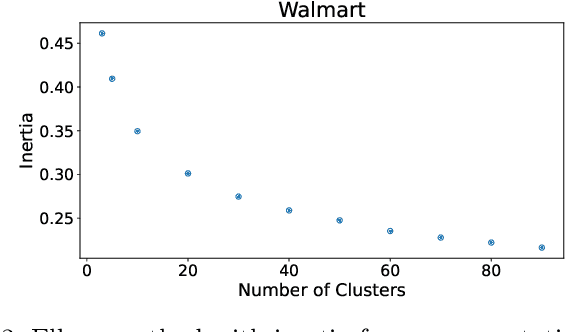
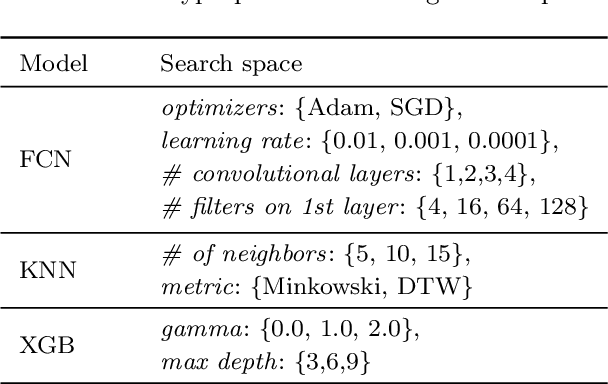
This study focuses on exploring the use of local interpretability methods for explaining time series clustering models. Many of the state-of-the-art clustering models are not directly explainable. To provide explanations for these clustering algorithms, we train classification models to estimate the cluster labels. Then, we use interpretability methods to explain the decisions of the classification models. The explanations are used to obtain insights into the clustering models. We perform a detailed numerical study to test the proposed approach on multiple datasets, clustering models, and classification models. The analysis of the results shows that the proposed approach can be used to explain time series clustering models, specifically when the underlying classification model is accurate. Lastly, we provide a detailed analysis of the results, discussing how our approach can be used in a real-life scenario.
Text Classification for Predicting Multi-level Product Categories
Sep 02, 2021
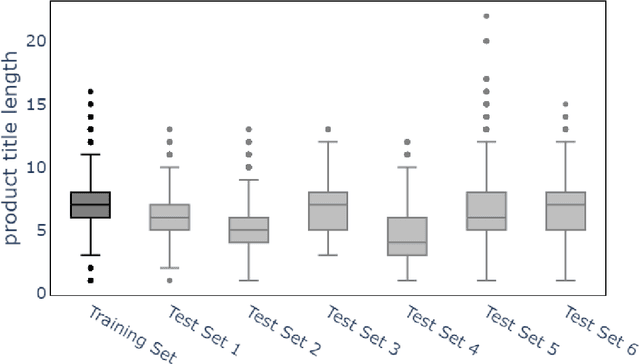
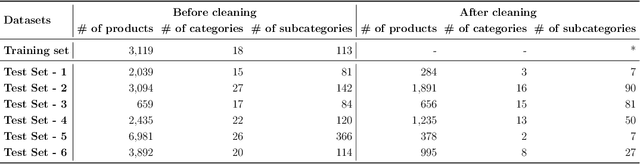
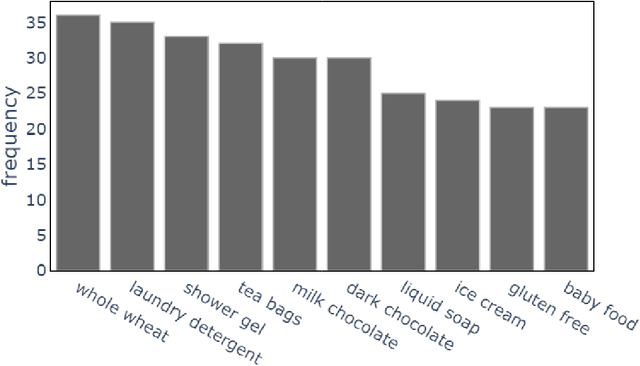
In an online shopping platform, a detailed classification of the products facilitates user navigation. It also helps online retailers keep track of the price fluctuations in a certain industry or special discounts on a specific product category. Moreover, an automated classification system may help to pinpoint incorrect or subjective categories suggested by an operator. In this study, we focus on product title classification of the grocery products. We perform a comprehensive comparison of six different text classification models to establish a strong baseline for this task, which involves testing both traditional and recent machine learning methods. In our experiments, we investigate the generalizability of the trained models to the products of other online retailers, the dynamic masking of infeasible subcategories for pretrained language models, and the benefits of incorporating product titles in multiple languages. Our numerical results indicate that dynamic masking of subcategories is effective in improving prediction accuracy. In addition, we observe that using bilingual product titles is generally beneficial, and neural network-based models perform significantly better than SVM and XGBoost models. Lastly, we investigate the reasons for the misclassified products and propose future research directions to further enhance the prediction models.
Word-level Text Highlighting of Medical Texts forTelehealth Services
May 21, 2021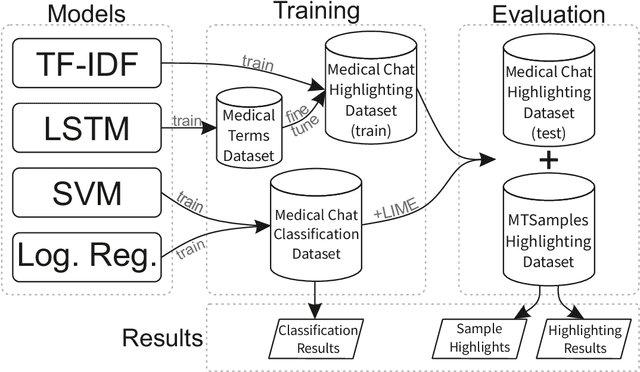
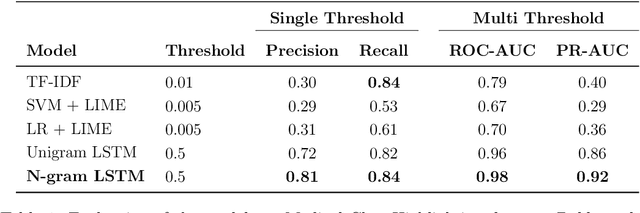

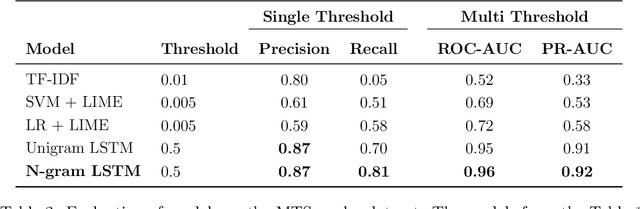
The medical domain is often subject to information overload. The digitization of healthcare, constant updates to online medical repositories, and increasing availability of biomedical datasets make it challenging to effectively analyze the data. This creates additional work for medical professionals who are heavily dependent on medical data to complete their research and consult their patients. This paper aims to show how different text highlighting techniques can capture relevant medical context. This would reduce the doctors' cognitive load and response time to patients by facilitating them in making faster decisions, thus improving the overall quality of online medical services. Three different word-level text highlighting methodologies are implemented and evaluated. The first method uses TF-IDF scores directly to highlight important parts of the text. The second method is a combination of TF-IDF scores and the application of Local Interpretable Model-Agnostic Explanations to classification models. The third method uses neural networks directly to make predictions on whether or not a word should be highlighted. The results of our experiments show that the neural network approach is successful in highlighting medically-relevant terms and its performance is improved as the size of the input segment increases.
Evaluation of Local Explanation Methods for Multivariate Time Series Forecasting
Sep 18, 2020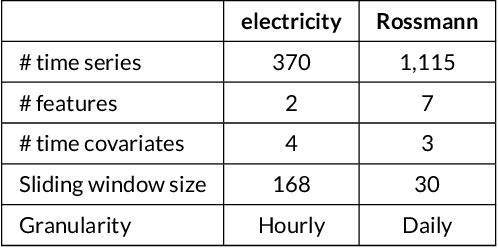
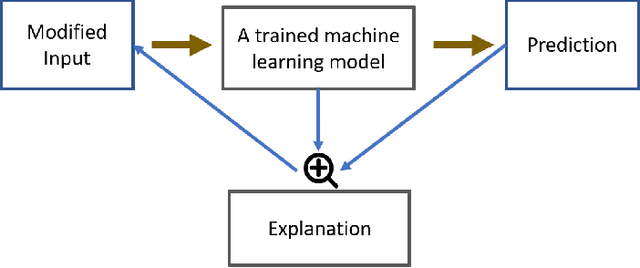
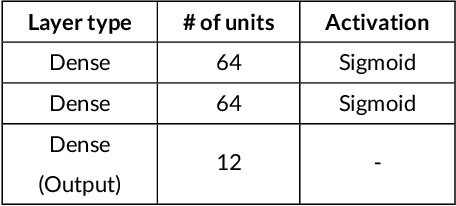
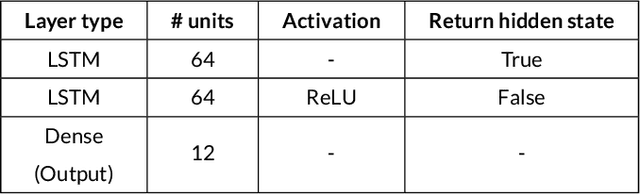
Being able to interpret a machine learning model is a crucial task in many applications of machine learning. Specifically, local interpretability is important in determining why a model makes particular predictions. Despite the recent focus on AI interpretability, there has been a lack of research in local interpretability methods for time series forecasting while the few interpretable methods that exist mainly focus on time series classification tasks. In this study, we propose two novel evaluation metrics for time series forecasting: Area Over the Perturbation Curve for Regression and Ablation Percentage Threshold. These two metrics can measure the local fidelity of local explanation models. We extend the theoretical foundation to collect experimental results on two popular datasets, \textit{Rossmann sales} and \textit{electricity}. Both metrics enable a comprehensive comparison of numerous local explanation models and find which metrics are more sensitive. Lastly, we provide heuristical reasoning for this analysis.
Deep learning approaches for fast radio signal prediction
Jul 14, 2020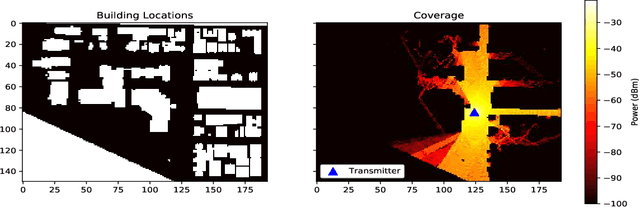
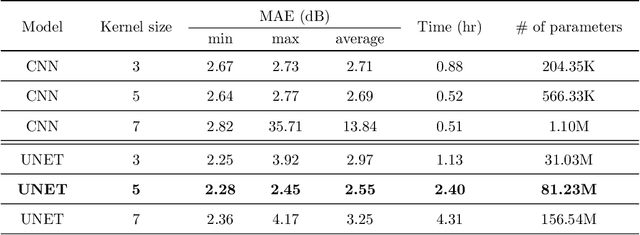
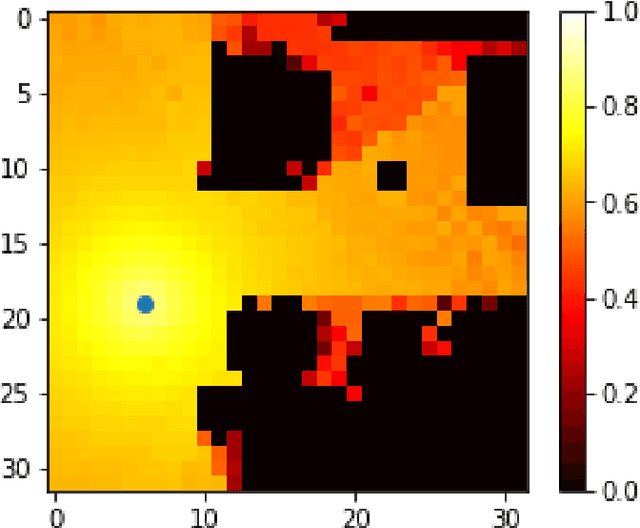
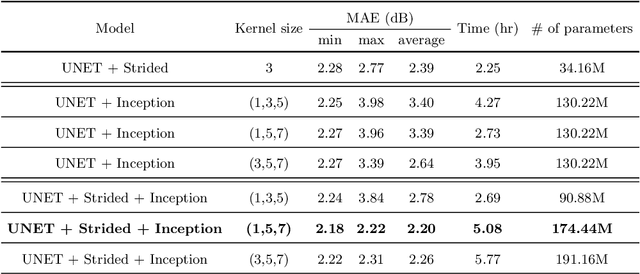
The aim of this work is the prediction of power coverage in a dense urban environment given building and transmitter locations. Conventionally ray-tracing is regarded as the most accurate method to predict energy distribution patterns in the area in the presence of diverse radio propagation phenomena. However, ray-tracing simulations are time consuming and require extensive computational resources. We propose deep neural network models to learn from ray-tracing results and predict the power coverage dynamically from buildings and transmitter properties. The proposed UNET model with strided convolutions and inception modules provide highly accurate results that are close to the ray-tracing output on 32x32 frames. This model will allow practitioners to search for the best transmitter locations effectively and reduce the design time significantly.