 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnderstanding transit ridership in an equity context through a comparison of statistical and machine learning algorithms
Nov 30, 2022



Building an accurate model of travel behaviour based on individuals' characteristics and built environment attributes is of importance for policy-making and transportation planning. Recent experiments with big data and Machine Learning (ML) algorithms toward a better travel behaviour analysis have mainly overlooked socially disadvantaged groups. Accordingly, in this study, we explore the travel behaviour responses of low-income individuals to transit investments in the Greater Toronto and Hamilton Area, Canada, using statistical and ML models. We first investigate how the model choice affects the prediction of transit use by the low-income group. This step includes comparing the predictive performance of traditional and ML algorithms and then evaluating a transit investment policy by contrasting the predicted activities and the spatial distribution of transit trips generated by vulnerable households after improving accessibility. We also empirically investigate the proposed transit investment by each algorithm and compare it with the city of Brampton's future transportation plan. While, unsurprisingly, the ML algorithms outperform classical models, there are still doubts about using them due to interpretability concerns. Hence, we adopt recent local and global model-agnostic interpretation tools to interpret how the model arrives at its predictions. Our findings reveal the great potential of ML algorithms for enhanced travel behaviour predictions for low-income strata without considerably sacrificing interpretability.
* This is the preprint of the accepted paper in the journal of Transport Geography. Please refer to its DOI
ADPTriage: Approximate Dynamic Programming for Bug Triage
Nov 02, 2022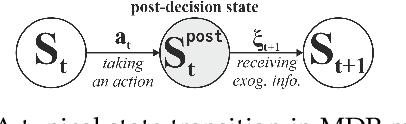
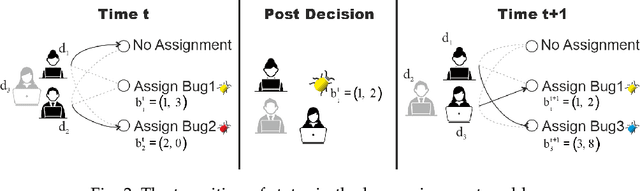
Bug triaging is a critical task in any software development project. It entails triagers going over a list of open bugs, deciding whether each is required to be addressed, and, if so, which developer should fix it. However, the manual bug assignment in issue tracking systems (ITS) offers only a limited solution and might easily fail when triagers must handle a large number of bug reports. During the automated assignment, there are multiple sources of uncertainties in the ITS, which should be addressed meticulously. In this study, we develop a Markov decision process (MDP) model for an online bug triage task. In addition to an optimization-based myopic technique, we provide an ADP-based bug triage solution, called ADPTriage, which has the ability to reflect the downstream uncertainty in the bug arrivals and developers' timetables. Specifically, without placing any limits on the underlying stochastic process, this technique enables real-time decision-making on bug assignments while taking into consideration developers' expertise, bug type, and bug fixing time. Our result shows a significant improvement over the myopic approach in terms of assignment accuracy and fixing time. We also demonstrate the empirical convergence of the model and conduct sensitivity analysis with various model parameters. Accordingly, this work constitutes a significant step forward in addressing the uncertainty in bug triage solutions
S-DABT: Schedule and Dependency-Aware Bug Triage in Open-Source Bug Tracking Systems
Apr 12, 2022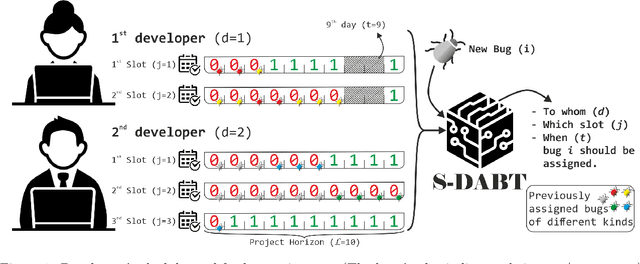
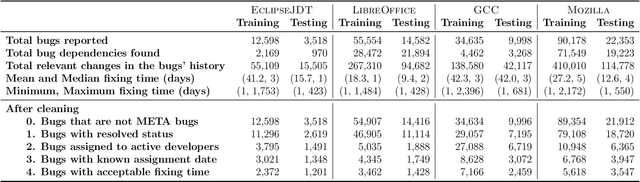


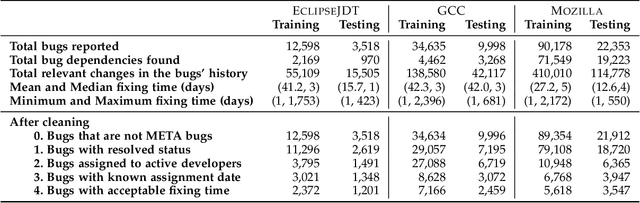
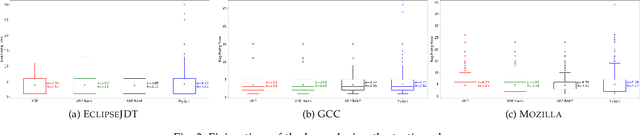
Fixing bugs in a timely manner lowers various potential costs in software maintenance. However, manual bug fixing scheduling can be time-consuming, cumbersome, and error-prone. In this paper, we propose the Schedule and Dependency-aware Bug Triage (S-DABT), a bug triaging method that utilizes integer programming and machine learning techniques to assign bugs to suitable developers. Unlike prior works that largely focus on a single component of the bug reports, our approach takes into account the textual data, bug fixing costs, and bug dependencies. We further incorporate the schedule of developers in our formulation to have a more comprehensive model for this multifaceted problem. As a result, this complete formulation considers developers' schedules and the blocking effects of the bugs while covering the most significant aspects of the previously proposed methods. Our numerical study on four open-source software systems, namely, EclipseJDT, LibreOffice, GCC, and Mozilla, shows that taking into account the schedules of the developers decreases the average bug fixing times. We find that S-DABT leads to a high level of developer utilization through a fair distribution of the tasks among the developers and efficient use of the free spots in their schedules. Via the simulation of the issue tracking system, we also show how incorporating the schedule in the model formulation reduces the bug fixing time, improves the assignment accuracy, and utilizes the capability of each developer without much comprising in the model run times. We find that S-DABT decreases the complexity of the bug dependency graph by prioritizing blocking bugs and effectively reduces the infeasible assignment ratio due to bug dependencies. Consequently, we recommend considering developers' schedules while automating bug triage.
Text Classification for Predicting Multi-level Product Categories
Sep 02, 2021
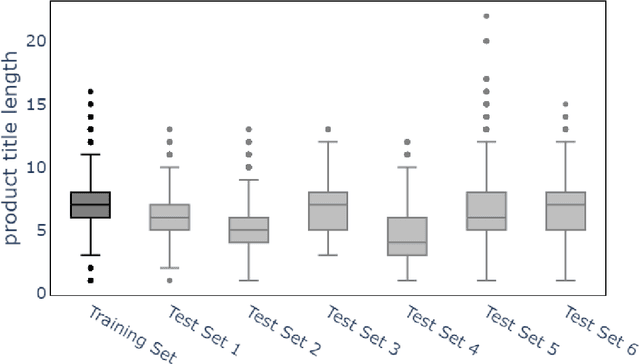
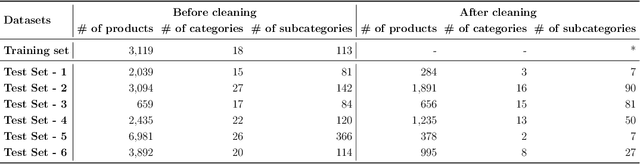
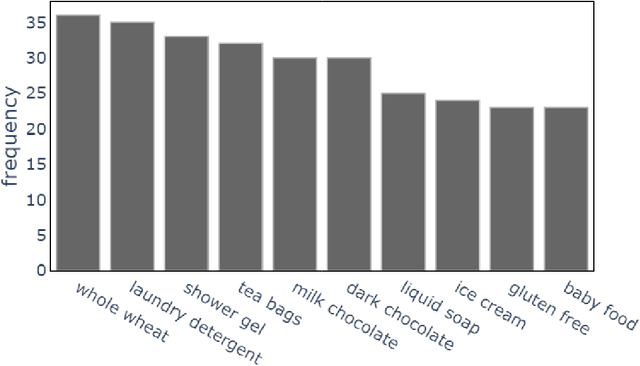
In an online shopping platform, a detailed classification of the products facilitates user navigation. It also helps online retailers keep track of the price fluctuations in a certain industry or special discounts on a specific product category. Moreover, an automated classification system may help to pinpoint incorrect or subjective categories suggested by an operator. In this study, we focus on product title classification of the grocery products. We perform a comprehensive comparison of six different text classification models to establish a strong baseline for this task, which involves testing both traditional and recent machine learning methods. In our experiments, we investigate the generalizability of the trained models to the products of other online retailers, the dynamic masking of infeasible subcategories for pretrained language models, and the benefits of incorporating product titles in multiple languages. Our numerical results indicate that dynamic masking of subcategories is effective in improving prediction accuracy. In addition, we observe that using bilingual product titles is generally beneficial, and neural network-based models perform significantly better than SVM and XGBoost models. Lastly, we investigate the reasons for the misclassified products and propose future research directions to further enhance the prediction models.
Auto Response Generation in Online Medical Chat Services
Apr 26, 2021

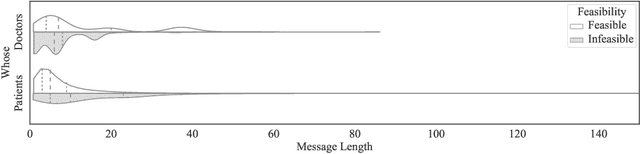
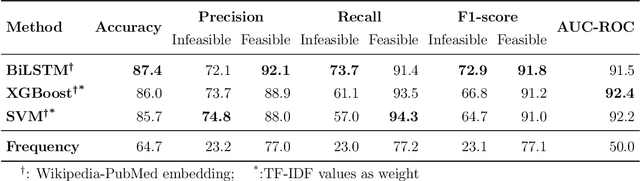
Telehealth helps to facilitate access to medical professionals by enabling remote medical services for the patients. These services have become gradually popular over the years with the advent of necessary technological infrastructure. The benefits of telehealth have been even more apparent since the beginning of the COVID-19 crisis, as people have become less inclined to visit doctors in person during the pandemic. In this paper, we focus on facilitating the chat sessions between a doctor and a patient. We note that the quality and efficiency of the chat experience can be critical as the demand for telehealth services increases. Accordingly, we develop a smart auto-response generation mechanism for medical conversations that helps doctors respond to consultation requests efficiently, particularly during busy sessions. We explore over 900,000 anonymous, historical online messages between doctors and patients collected over nine months. We implement clustering algorithms to identify the most frequent responses by doctors and manually label the data accordingly. We then train machine learning algorithms using this preprocessed data to generate the responses. The considered algorithm has two steps: a filtering (i.e., triggering) model to filter out infeasible patient messages and a response generator to suggest the top-3 doctor responses for the ones that successfully pass the triggering phase. The method provides an accuracy of 83.28\% for precision@3 and shows robustness to its parameters.
DABT: A Dependency-aware Bug Triaging Method
Apr 26, 2021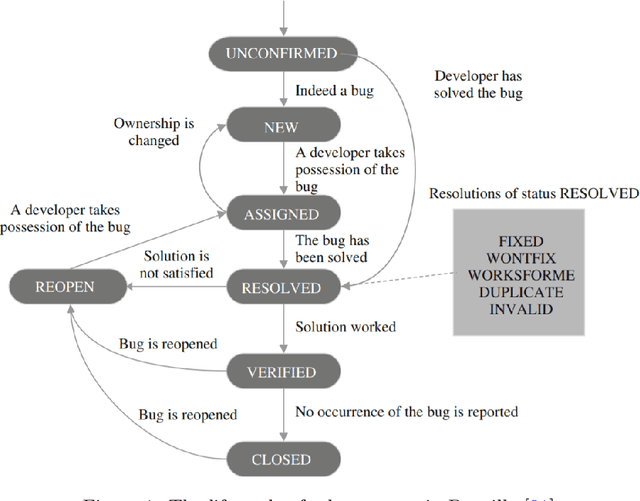
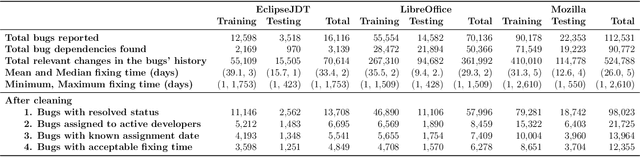
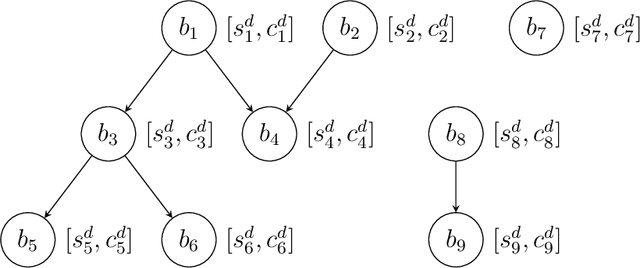
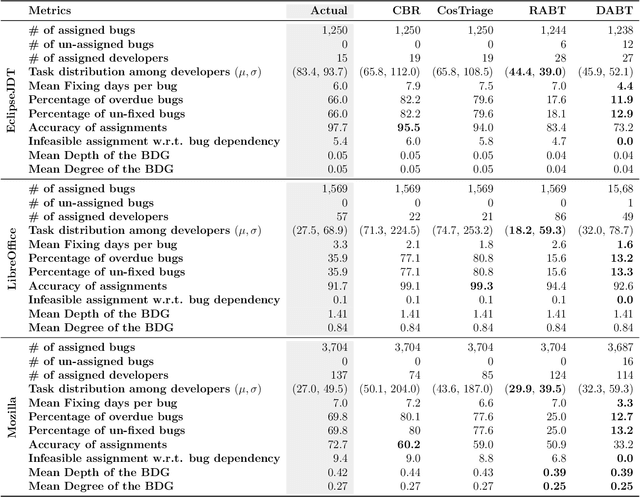
In software engineering practice, fixing a bug promptly reduces the associated costs. On the other hand, the manual bug fixing process can be time-consuming, cumbersome, and error-prone. In this work, we introduce a bug triaging method, called Dependency-aware Bug Triaging (DABT), which leverages natural language processing and integer programming to assign bugs to appropriate developers. Unlike previous works that mainly focus on one aspect of the bug reports, DABT considers the textual information, cost associated with each bug, and dependency among them. Therefore, this comprehensive formulation covers the most important aspect of the previous works while considering the blocking effect of the bugs. We report the performance of the algorithm on three open-source software systems, i.e., EclipseJDT, LibreOffice, and Mozilla. Our result shows that DABT is able to reduce the number of overdue bugs up to 12\%. It also decreases the average fixing time of the bugs by half. Moreover, it reduces the complexity of the bug dependency graph by prioritizing blocking bugs.
Predicting the Number of Reported Bugs in a Software Repository
Apr 24, 2021
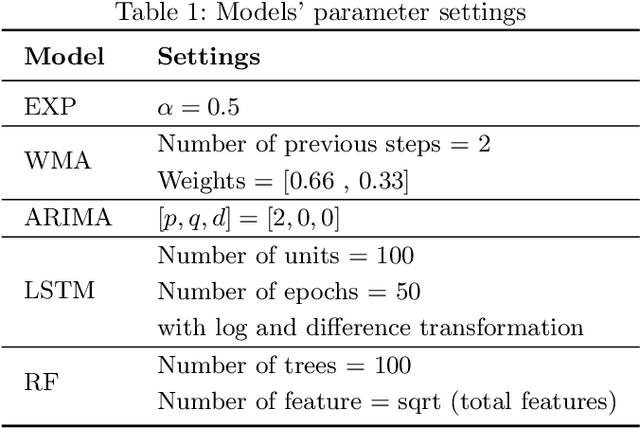
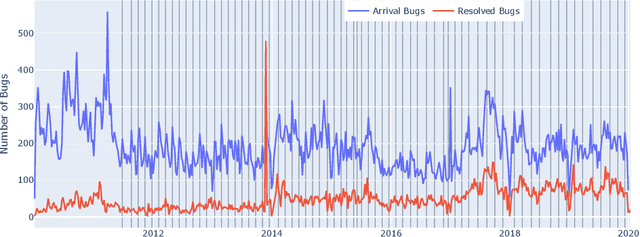
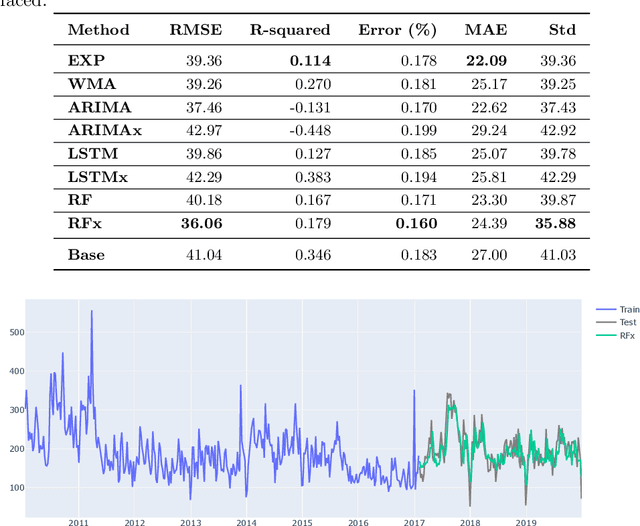
The bug growth pattern prediction is a complicated, unrelieved task, which needs considerable attention. Advance knowledge of the likely number of bugs discovered in the software system helps software developers in designating sufficient resources at a convenient time. The developers may also use such information to take necessary actions to increase the quality of the system and in turn customer satisfaction. In this study, we examine eight different time series forecasting models, including Long Short Term Memory Neural Networks (LSTM), auto-regressive integrated moving average (ARIMA), and Random Forest Regressor. Further, we assess the impact of exogenous variables such as software release dates by incorporating those into the prediction models. We analyze the quality of long-term prediction for each model based on different performance metrics. The assessment is conducted on Mozilla, which is a large open-source software application. The dataset is originally mined from Bugzilla and contains the number of bugs for the project between Jan 2010 and Dec 2019. Our numerical analysis provides insights on evaluating the trends in a bug repository. We observe that LSTM is effective when considering long-run predictions whereas Random Forest Regressor enriched by exogenous variables performs better for predicting the number of bugs in the short term.
A Deep Reinforcement Learning Approach for the Meal Delivery Problem
Apr 24, 2021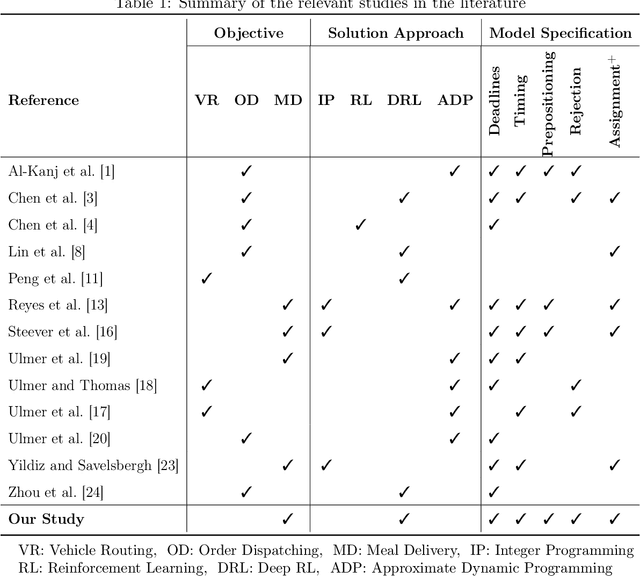
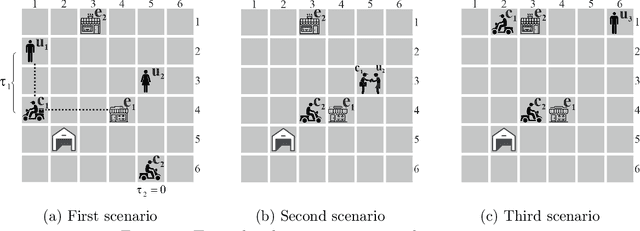

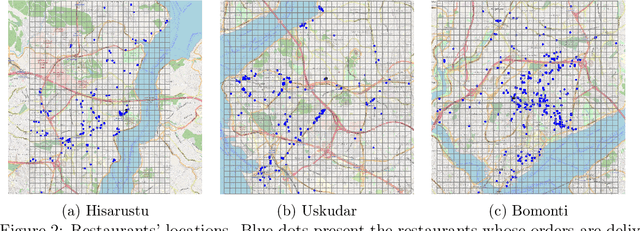
We consider a meal delivery service fulfilling dynamic customer requests given a set of couriers over the course of a day. A courier's duty is to pick-up an order from a restaurant and deliver it to a customer. We model this service as a Markov decision process and use deep reinforcement learning as the solution approach. We experiment with the resulting policies on synthetic and real-world datasets and compare those with the baseline policies. We also examine the courier utilization for different numbers of couriers. In our analysis, we specifically focus on the impact of the limited available resources in the meal delivery problem. Furthermore, we investigate the effect of intelligent order rejection and re-positioning of the couriers. Our numerical experiments show that, by incorporating the geographical locations of the restaurants, customers, and the depot, our model significantly improves the overall service quality as characterized by the expected total reward and the delivery times. Our results present valuable insights on both the courier assignment process and the optimal number of couriers for different order frequencies on a given day. The proposed model also shows a robust performance under a variety of scenarios for real-world implementation.
Does chronology matter in JIT defect prediction? A Partial Replication Study
Mar 05, 2021
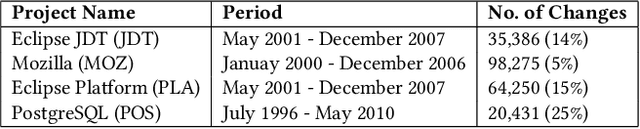
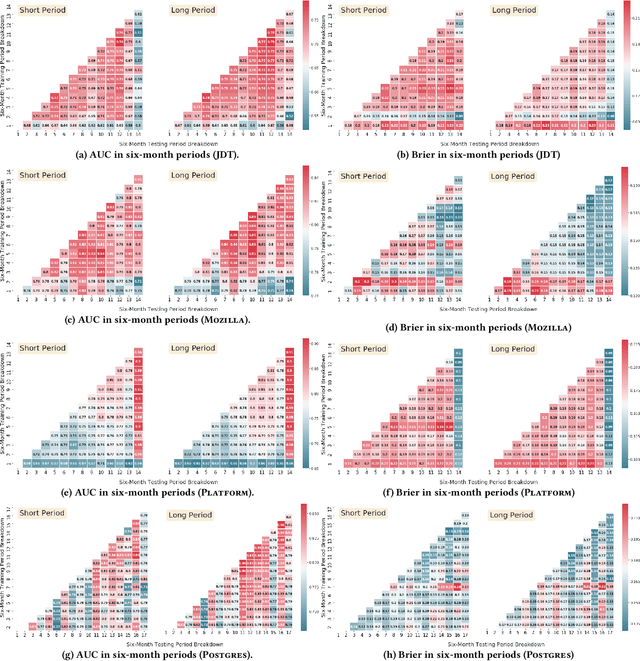
Just-In-Time (JIT) models detect the fix-inducing changes (or defect-inducing changes). These models are designed based on the assumption that past code change properties are similar to future ones. However, as the system evolves, the expertise of developers and/or the complexity of the system also changes. In this work, we aim to investigate the effect of code change properties on JIT models over time. We also study the impact of using recent data as well as all available data on the performance of JIT models. Further, we analyze the effect of weighted sampling on the performance of fix-inducing properties of JIT models. For this purpose, we used datasets from Eclipse JDT, Mozilla, Eclipse Platform, and PostgreSQL. We used five families of change-code properties such as size, diffusion, history, experience, and purpose. We used Random Forest to train and test the JIT model and Brier Score and the area under the ROC curve for performance measurement. Our paper suggests that the predictive power of JIT models does not change over time. Furthermore, we observed that the chronology of data in JIT defect prediction models can be discarded by considering all the available data. On the other hand, the importance score of families of code change properties is found to oscillate over time. To mitigate the impact of the evolution of code change properties, it is recommended to use a weighted sampling approach in which more emphasis is placed upon the changes occurring closer to the current time. Moreover, since properties such as "Expertise of the Developer" and "Size" evolve with time, the models obtained from old data may exhibit different characteristics compared to those employing the newer dataset. Hence, practitioners should constantly retrain JIT models to include fresh data.
Moving from Cross-Project Defect Prediction to Heterogeneous Defect Prediction: A Partial Replication Study
Mar 05, 2021
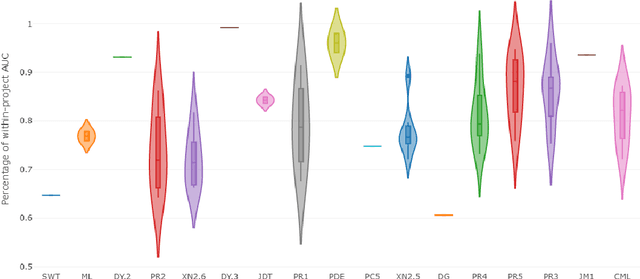
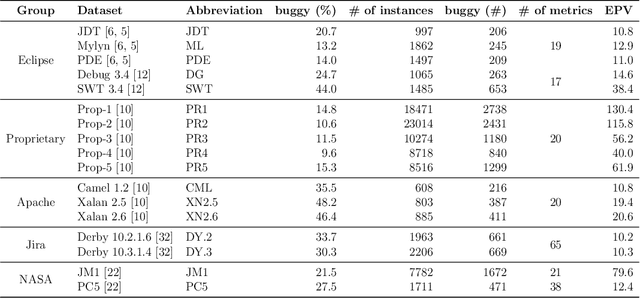
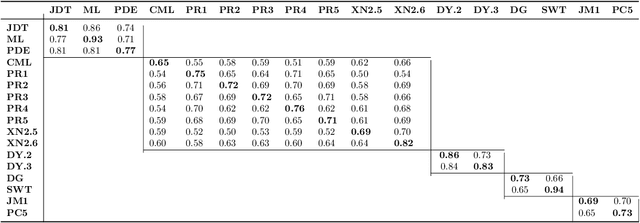
Software defect prediction heavily relies on the metrics collected from software projects. Earlier studies often used machine learning techniques to build, validate, and improve bug prediction models using either a set of metrics collected within a project or across different projects. However, techniques applied and conclusions derived by those models are restricted by how identical those metrics are. Knowledge coming from those models will not be extensible to a target project if no sufficient overlapping metrics have been collected in the source projects. To explore the feasibility of transferring knowledge across projects without common labeled metrics, we systematically integrated Heterogeneous Defect Prediction (HDP) by replicating and validating the obtained results. Our main goal is to extend prior research and explore the feasibility of HDP and finally to compare its performance with that of its predecessor, Cross-Project Defect Prediction. We construct an HDP model on different publicly available datasets. Moreover, we propose a new ensemble voting approach in the HDP context to utilize the predictive power of multiple available datasets. The result of our experiment is comparable to that of the original study. However, we also explored the feasibility of HDP in real cases. Our results shed light on the infeasibility of many cases for the HDP algorithm due to its sensitivity to the parameter selection. In general, our analysis gives a deep insight into why and how to perform transfer learning from one domain to another, and in particular, provides a set of guidelines to help researchers and practitioners to disseminate knowledge to the defect prediction domain.