 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePrediction of the 2023 Turkish Presidential Election Results Using Social Media Data
May 28, 2023Social media platforms influence the way political campaigns are run and therefore they have become an increasingly important tool for politicians to directly interact with citizens. Previous elections in various countries have shown that social media data may significantly impact election results. In this study, we aim to predict the vote shares of parties participating in the 2023 elections in Turkey by combining social media data from various platforms together with traditional polling data. Our approach is a volume-based approach that considers the number of social media interactions rather than content. We compare several prediction models across varying time windows. Our results show that for all time windows, the ARIMAX model outperforms the other algorithms.
Time Series Clustering for Grouping Products Based on Price and Sales Patterns
Apr 18, 2022
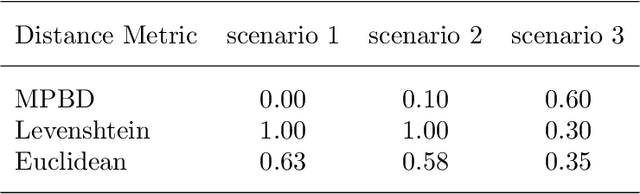
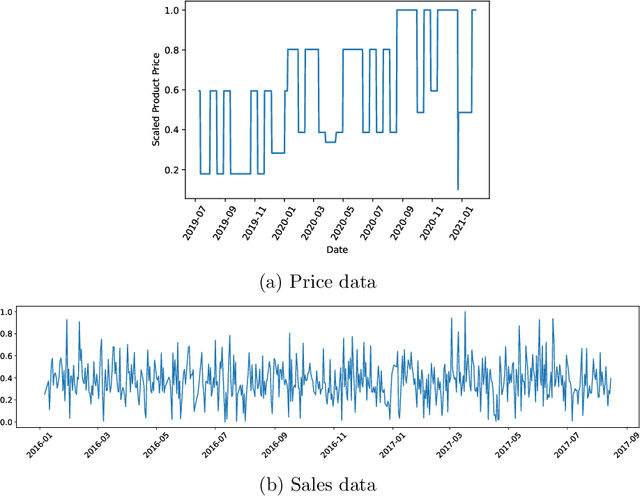
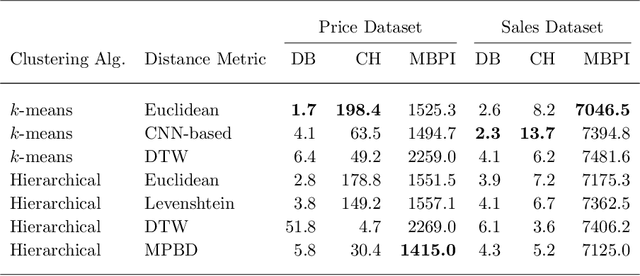
Developing technology and changing lifestyles have made online grocery delivery applications an indispensable part of urban life. Since the beginning of the COVID-19 pandemic, the demand for such applications has dramatically increased, creating new competitors that disrupt the market. An increasing level of competition might prompt companies to frequently restructure their marketing and product pricing strategies. Therefore, identifying the change patterns in product prices and sales volumes would provide a competitive advantage for the companies in the marketplace. In this paper, we investigate alternative clustering methodologies to group the products based on the price patterns and sales volumes. We propose a novel distance metric that takes into account how product prices and sales move together rather than calculating the distance using numerical values. We compare our approach with traditional clustering algorithms, which typically rely on generic distance metrics such as Euclidean distance, and image clustering approaches that aim to group data by capturing its visual patterns. We evaluate the performances of different clustering algorithms using our custom evaluation metric as well as Calinski Harabasz and Davies Bouldin indices, which are commonly used internal validity metrics. We conduct our numerical study using a propriety price dataset from an online food and grocery delivery company, and the publicly available Favorita sales dataset. We find that our proposed clustering approach and image clustering both perform well for finding the products with similar price and sales patterns within large datasets.
A Deep Reinforcement Learning Approach for the Meal Delivery Problem
Apr 24, 2021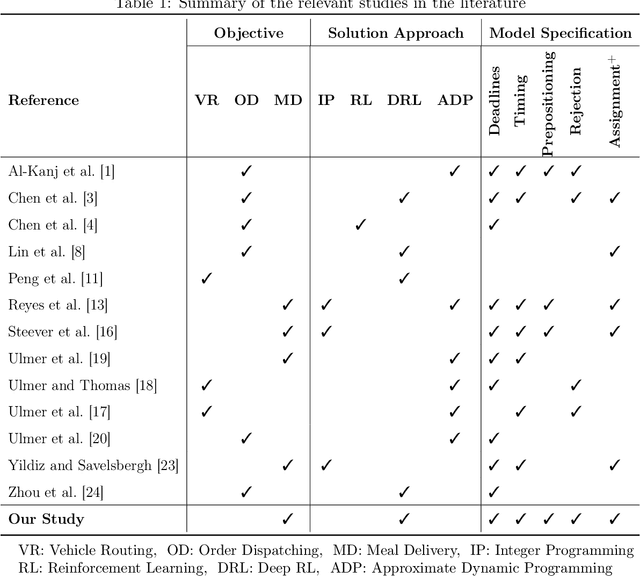
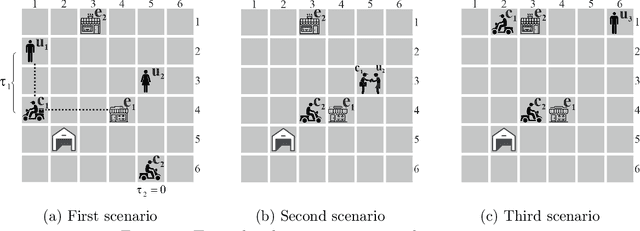

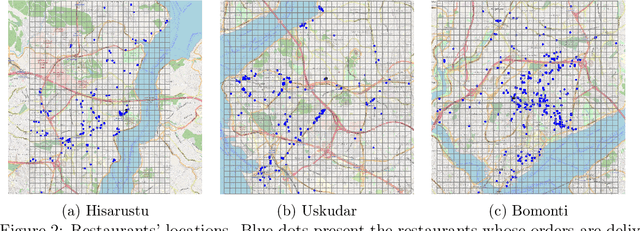
We consider a meal delivery service fulfilling dynamic customer requests given a set of couriers over the course of a day. A courier's duty is to pick-up an order from a restaurant and deliver it to a customer. We model this service as a Markov decision process and use deep reinforcement learning as the solution approach. We experiment with the resulting policies on synthetic and real-world datasets and compare those with the baseline policies. We also examine the courier utilization for different numbers of couriers. In our analysis, we specifically focus on the impact of the limited available resources in the meal delivery problem. Furthermore, we investigate the effect of intelligent order rejection and re-positioning of the couriers. Our numerical experiments show that, by incorporating the geographical locations of the restaurants, customers, and the depot, our model significantly improves the overall service quality as characterized by the expected total reward and the delivery times. Our results present valuable insights on both the courier assignment process and the optimal number of couriers for different order frequencies on a given day. The proposed model also shows a robust performance under a variety of scenarios for real-world implementation.