 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes chronology matter in JIT defect prediction? A Partial Replication Study
Mar 05, 2021
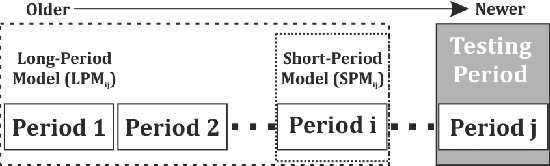
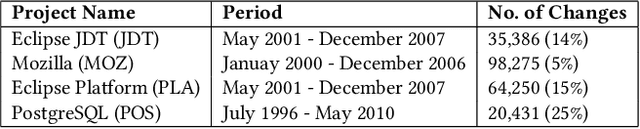
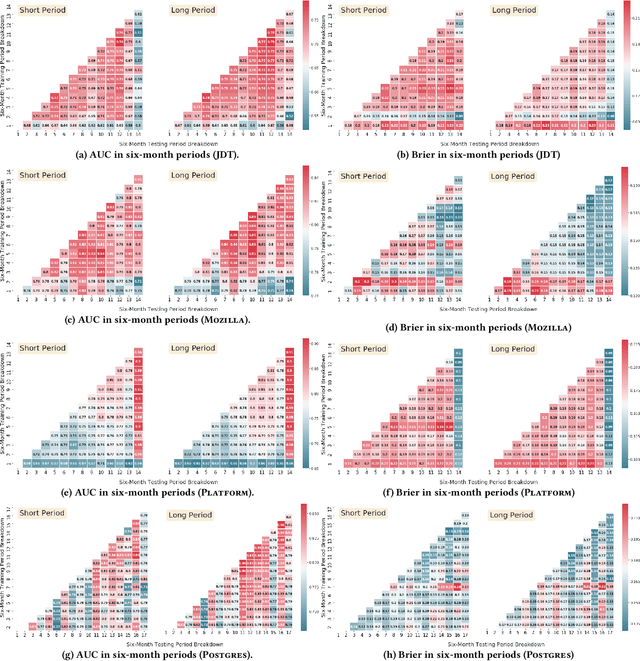
Just-In-Time (JIT) models detect the fix-inducing changes (or defect-inducing changes). These models are designed based on the assumption that past code change properties are similar to future ones. However, as the system evolves, the expertise of developers and/or the complexity of the system also changes. In this work, we aim to investigate the effect of code change properties on JIT models over time. We also study the impact of using recent data as well as all available data on the performance of JIT models. Further, we analyze the effect of weighted sampling on the performance of fix-inducing properties of JIT models. For this purpose, we used datasets from Eclipse JDT, Mozilla, Eclipse Platform, and PostgreSQL. We used five families of change-code properties such as size, diffusion, history, experience, and purpose. We used Random Forest to train and test the JIT model and Brier Score and the area under the ROC curve for performance measurement. Our paper suggests that the predictive power of JIT models does not change over time. Furthermore, we observed that the chronology of data in JIT defect prediction models can be discarded by considering all the available data. On the other hand, the importance score of families of code change properties is found to oscillate over time. To mitigate the impact of the evolution of code change properties, it is recommended to use a weighted sampling approach in which more emphasis is placed upon the changes occurring closer to the current time. Moreover, since properties such as "Expertise of the Developer" and "Size" evolve with time, the models obtained from old data may exhibit different characteristics compared to those employing the newer dataset. Hence, practitioners should constantly retrain JIT models to include fresh data.