 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDANLIP: Deep Autoregressive Networks for Locally Interpretable Probabilistic Forecasting
Jan 05, 2023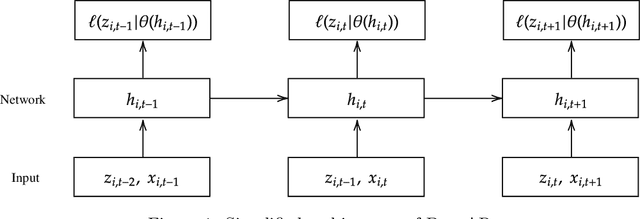
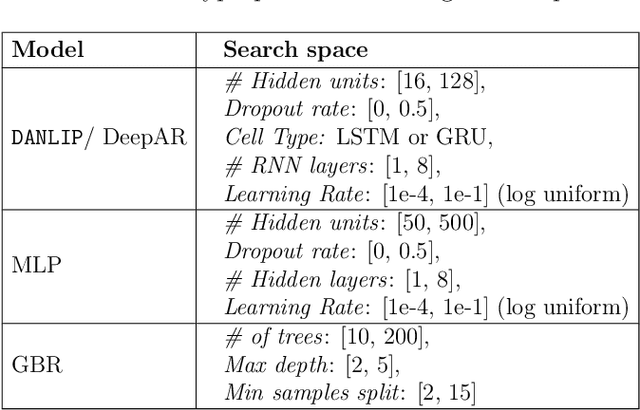
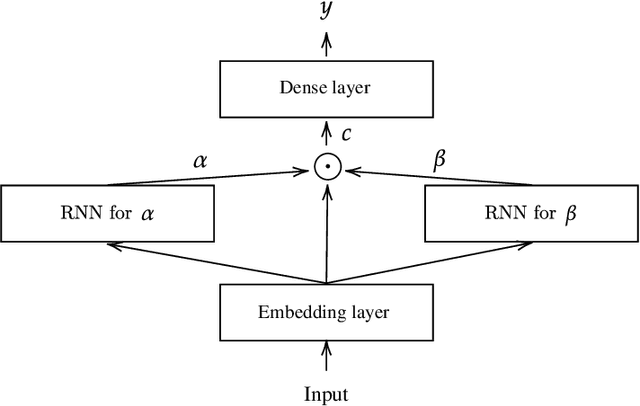
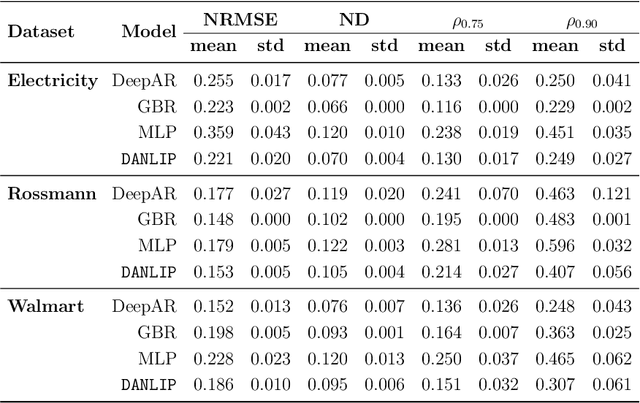
Despite the high performance of neural network-based time series forecasting methods, the inherent challenge in explaining their predictions has limited their applicability in certain application areas. Due to the difficulty in identifying causal relationships between the input and output of such black-box methods, they rarely have been adopted in domains such as legal and medical fields in which the reliability and interpretability of the results can be essential. In this paper, we propose \model, a novel deep learning-based probabilistic time series forecasting architecture that is intrinsically interpretable. We conduct experiments with multiple datasets and performance metrics and empirically show that our model is not only interpretable but also provides comparable performance to state-of-the-art probabilistic time series forecasting methods. Furthermore, we demonstrate that interpreting the parameters of the stochastic processes of interest can provide useful insights into several application areas.
A Deep Reinforcement Learning Framework For Column Generation
Jun 03, 2022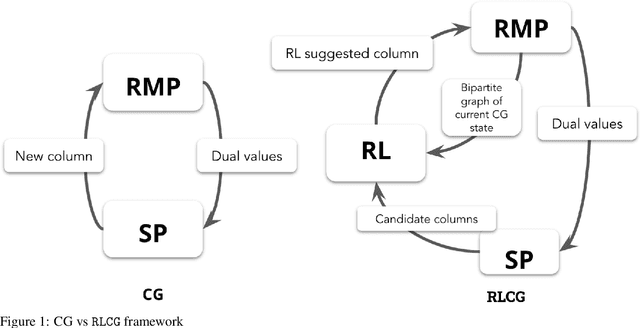
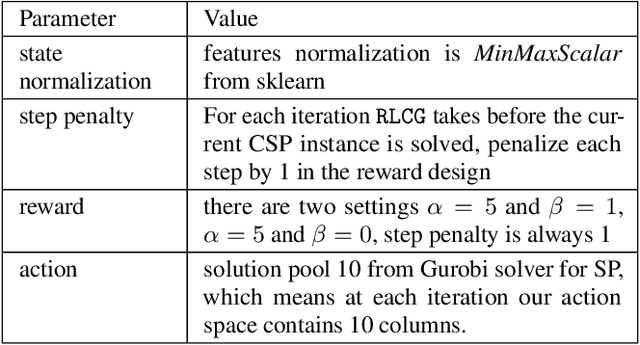
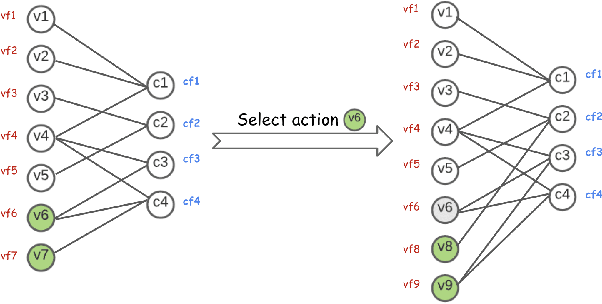
Column Generation (CG) is an iterative algorithm for solving linear programs (LPs) with an extremely large number of variables (columns). CG is the workhorse for tackling large-scale integer linear programs, which rely on CG to solve LP relaxations within a branch and bound algorithm. Two canonical applications are the Cutting Stock Problem (CSP) and Vehicle Routing Problem with Time Windows (VRPTW). In VRPTW, for example, each binary variable represents the decision to include or exclude a route, of which there are exponentially many; CG incrementally grows the subset of columns being used, ultimately converging to an optimal solution. We propose RLCG, the first Reinforcement Learning (RL) approach for CG. Unlike typical column selection rules which myopically select a column based on local information at each iteration, we treat CG as a sequential decision-making problem, as the column selected in an iteration affects subsequent iterations of the algorithm. This perspective lends itself to a Deep Reinforcement Learning approach that uses Graph Neural Networks (GNNs) to represent the variable-constraint structure in the LP of interest. We perform an extensive set of experiments using the publicly available BPPLIB benchmark for CSP and Solomon benchmark for VRPTW. RLCG converges faster and reduces the number of CG iterations by 22.4% for CSP and 40.9% for VRPTW on average compared to a commonly used greedy policy.