 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Concurrent CNN-RNN Approach for Multi-Step Wind Power Forecasting
Jan 02, 2023Wind power forecasting helps with the planning for the power systems by contributing to having a higher level of certainty in decision-making. Due to the randomness inherent to meteorological events (e.g., wind speeds), making highly accurate long-term predictions for wind power can be extremely difficult. One approach to remedy this challenge is to utilize weather information from multiple points across a geographical grid to obtain a holistic view of the wind patterns, along with temporal information from the previous power outputs of the wind farms. Our proposed CNN-RNN architecture combines convolutional neural networks (CNNs) and recurrent neural networks (RNNs) to extract spatial and temporal information from multi-dimensional input data to make day-ahead predictions. In this regard, our method incorporates an ultra-wide learning view, combining data from multiple numerical weather prediction models, wind farms, and geographical locations. Additionally, we experiment with global forecasting approaches to understand the impact of training the same model over the datasets obtained from multiple different wind farms, and we employ a method where spatial information extracted from convolutional layers is passed to a tree ensemble (e.g., Light Gradient Boosting Machine (LGBM)) instead of fully connected layers. The results show that our proposed CNN-RNN architecture outperforms other models such as LGBM, Extra Tree regressor and linear regression when trained globally, but fails to replicate such performance when trained individually on each farm. We also observe that passing the spatial information from CNN to LGBM improves its performance, providing further evidence of CNN's spatial feature extraction capabilities.
nTreeClus: a Tree-based Sequence Encoder for Clustering Categorical Series
Feb 20, 2021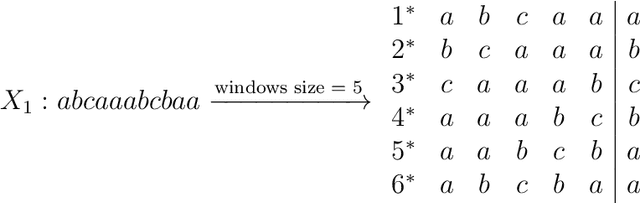
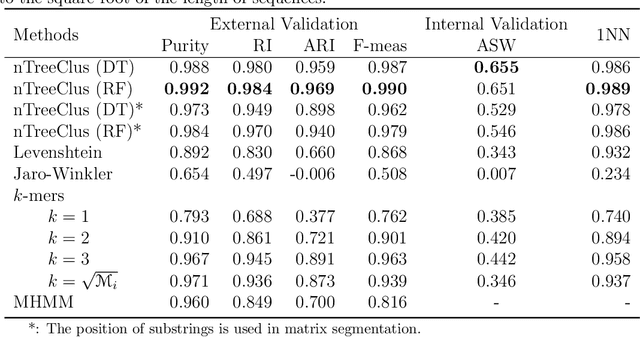
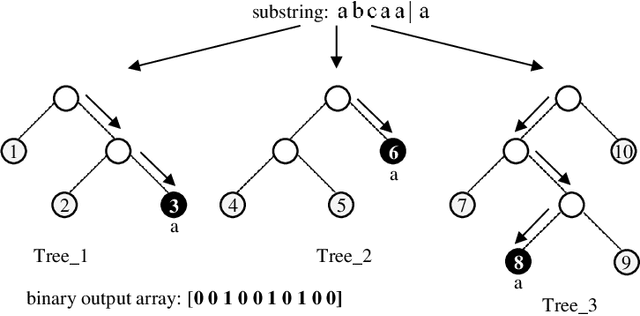

The overwhelming presence of categorical/sequential data in diverse domains emphasizes the importance of sequence mining. The challenging nature of sequences proves the need for continuing research to find a more accurate and faster approach providing a better understanding of their (dis)similarities. This paper proposes a new Model-based approach for clustering sequence data, namely nTreeClus. The proposed method deploys Tree-based Learners, k-mers, and autoregressive models for categorical time series, culminating with a novel numerical representation of the categorical sequences. Adopting this new representation, we cluster sequences, considering the inherent patterns in categorical time series. Accordingly, the model showed robustness to its parameter. Under different simulated scenarios, nTreeClus improved the baseline methods for various internal and external cluster validation metrics for up to 10.7% and 2.7%, respectively. The empirical evaluation using synthetic and real datasets, protein sequences, and categorical time series showed that nTreeClus is competitive or superior to most state-of-the-art algorithms.
Explainable boosted linear regression for time series forecasting
Sep 18, 2020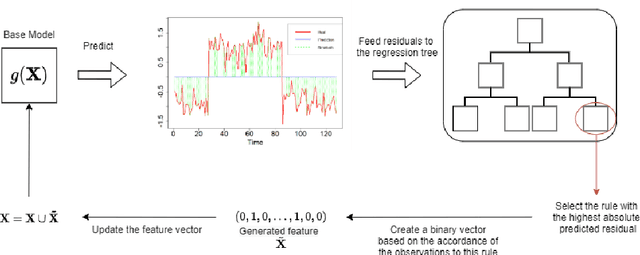
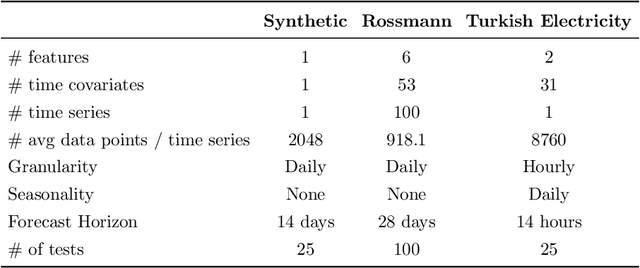
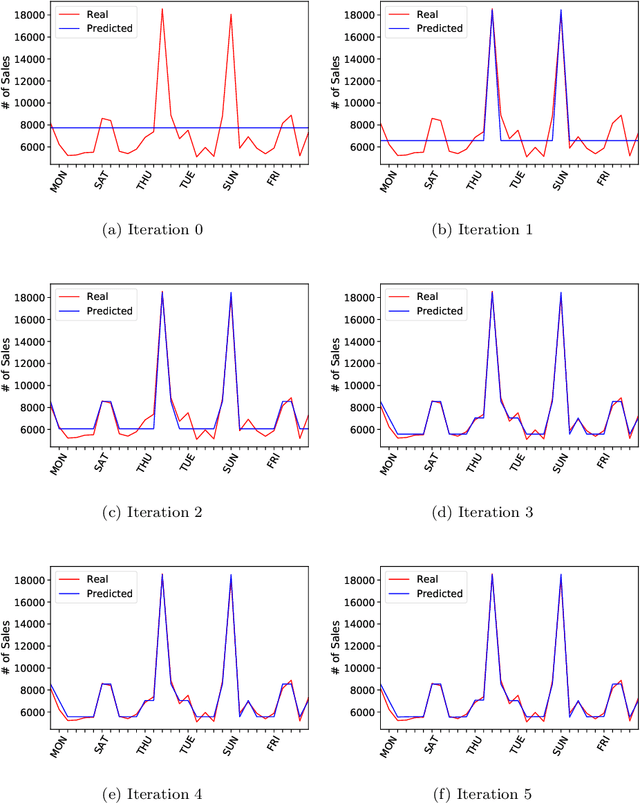

Time series forecasting involves collecting and analyzing past observations to develop a model to extrapolate such observations into the future. Forecasting of future events is important in many fields to support decision making as it contributes to reducing the future uncertainty. We propose explainable boosted linear regression (EBLR) algorithm for time series forecasting, which is an iterative method that starts with a base model, and explains the model's errors through regression trees. At each iteration, the path leading to highest error is added as a new variable to the base model. In this regard, our approach can be considered as an improvement over general time series models since it enables incorporating nonlinear features by residuals explanation. More importantly, use of the single rule that contributes to the error most allows for interpretable results. The proposed approach extends to probabilistic forecasting through generating prediction intervals based on the empirical error distribution. We conduct a detailed numerical study with EBLR and compare against various other approaches. We observe that EBLR substantially improves the base model performance through extracted features, and provide a comparable performance to other well established approaches. The interpretability of the model predictions and high predictive accuracy of EBLR makes it a promising method for time series forecasting.
Learning Maximally Predictive Prototypes in Multiple Instance Learning
Oct 02, 2019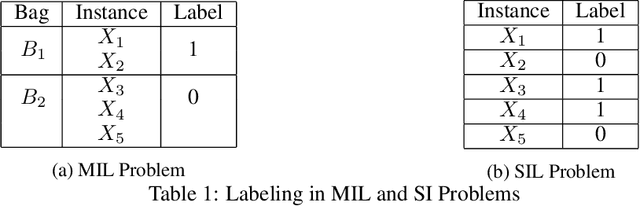
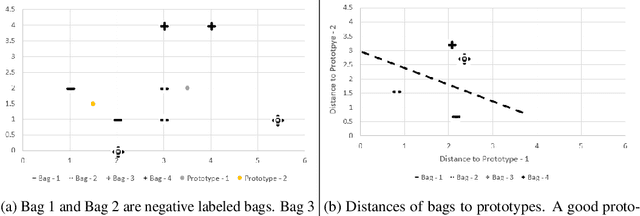
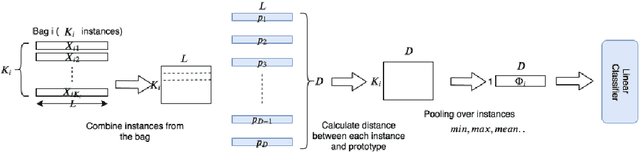

In this work, we propose a simple model that provides permutation invariant maximally predictive prototype generator from a given dataset, which leads to interpretability of the solution and concrete insights to the nature and the solution of a problem. Our aim is to find out prototypes in the feature space to map the collection of instances (i.e. bags) to a distance feature space and simultaneously learn a linear classifier for multiple instance learning (MIL). Our experiments on classical MIL benchmark datasets demonstrate that proposed framework is an accurate and efficient classifier compared to the existing approaches.