 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgenTreeClus: a Tree-based Sequence Encoder for Clustering Categorical Series
Paper and Code
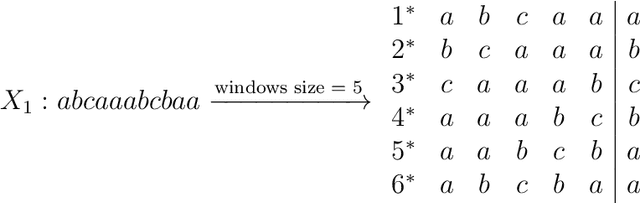
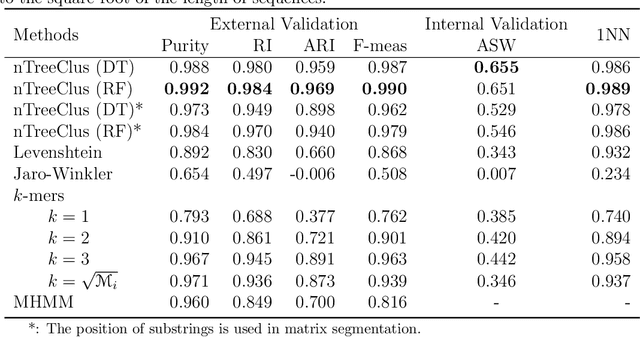
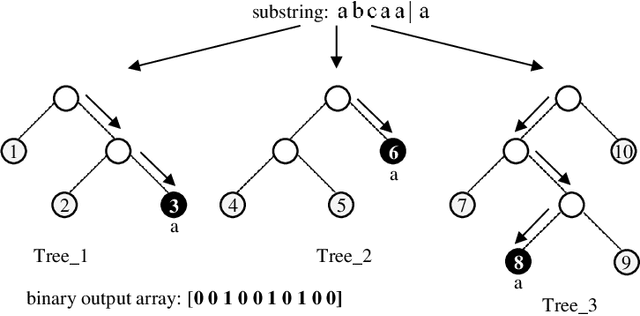

The overwhelming presence of categorical/sequential data in diverse domains emphasizes the importance of sequence mining. The challenging nature of sequences proves the need for continuing research to find a more accurate and faster approach providing a better understanding of their (dis)similarities. This paper proposes a new Model-based approach for clustering sequence data, namely nTreeClus. The proposed method deploys Tree-based Learners, k-mers, and autoregressive models for categorical time series, culminating with a novel numerical representation of the categorical sequences. Adopting this new representation, we cluster sequences, considering the inherent patterns in categorical time series. Accordingly, the model showed robustness to its parameter. Under different simulated scenarios, nTreeClus improved the baseline methods for various internal and external cluster validation metrics for up to 10.7% and 2.7%, respectively. The empirical evaluation using synthetic and real datasets, protein sequences, and categorical time series showed that nTreeClus is competitive or superior to most state-of-the-art algorithms.