 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Hard-to-Place Kidney Allocation: A Machine Learning Approach to Center Ranking
Oct 10, 2024Kidney transplantation is the preferred treatment for end-stage renal disease, yet the scarcity of donors and inefficiencies in allocation systems create major bottlenecks, resulting in prolonged wait times and alarming mortality rates. Despite their severe scarcity, timely and effective interventions to prevent non-utilization of life-saving organs remain inadequate. Expedited out-of-sequence placement of hard-to-place kidneys to centers with the highest likelihood of utilizing them has been recommended in the literature as an effective strategy to improve placement success. Nevertheless, current attempts towards this practice is non-standardized and heavily rely on the subjective judgment of the decision-makers. This paper proposes a novel data-driven, machine learning-based ranking system for allocating hard-to-place kidneys to centers with a higher likelihood of accepting and successfully transplanting them. Using the national deceased donor kidney offer and transplant datasets, we construct a unique dataset with donor-, center-, and patient-specific features. We propose a data-driven out-of-sequence placement policy that utilizes machine learning models to predict the acceptance probability of a given kidney by a set of transplant centers, ranking them accordingly based on their likelihood of acceptance. Our experiments demonstrate that the proposed policy can reduce the average number of centers considered before placement by fourfold for all kidneys and tenfold for hard-to-place kidneys. This significant reduction indicates that our method can improve the utilization of hard-to-place kidneys and accelerate their acceptance, ultimately reducing patient mortality and the risk of graft failure. Further, we utilize machine learning interpretability tools to provide insights into factors influencing the kidney allocation decisions.
A Deterministic Analysis of an Online Convex Mixture of Expert Algorithms
Sep 28, 2012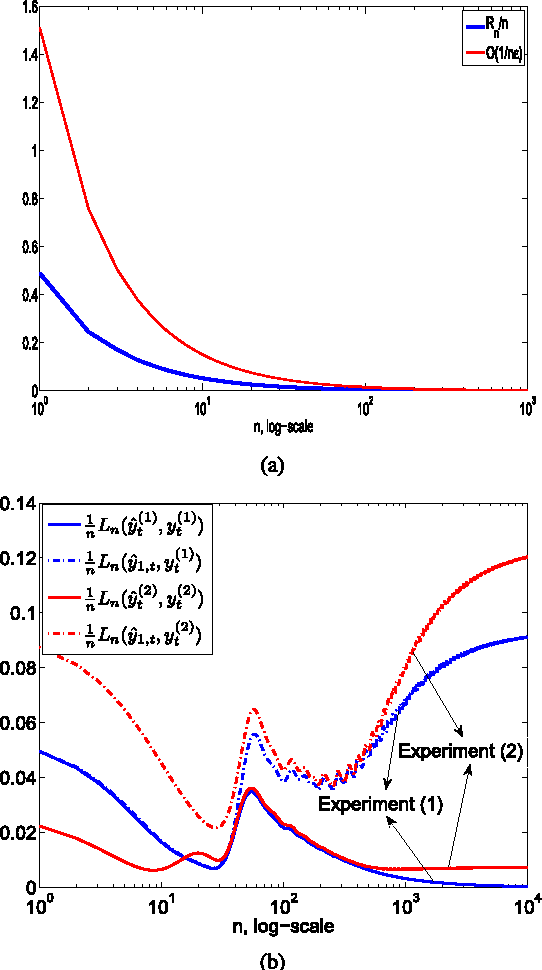

We analyze an online learning algorithm that adaptively combines outputs of two constituent algorithms (or the experts) running in parallel to model an unknown desired signal. This online learning algorithm is shown to achieve (and in some cases outperform) the mean-square error (MSE) performance of the best constituent algorithm in the mixture in the steady-state. However, the MSE analysis of this algorithm in the literature uses approximations and relies on statistical models on the underlying signals and systems. Hence, such an analysis may not be useful or valid for signals generated by various real life systems that show high degrees of nonstationarity, limit cycles and, in many cases, that are even chaotic. In this paper, we produce results in an individual sequence manner. In particular, we relate the time-accumulated squared estimation error of this online algorithm at any time over any interval to the time accumulated squared estimation error of the optimal convex mixture of the constituent algorithms directly tuned to the underlying signal in a deterministic sense without any statistical assumptions. In this sense, our analysis provides the transient, steady-state and tracking behavior of this algorithm in a strong sense without any approximations in the derivations or statistical assumptions on the underlying signals such that our results are guaranteed to hold. We illustrate the introduced results through examples.