 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEE-Grad: Exploration and Exploitation for Cost-Efficient Mini-Batch SGD
May 19, 2017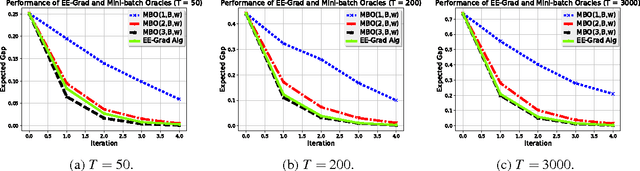
We present a generic framework for trading off fidelity and cost in computing stochastic gradients when the costs of acquiring stochastic gradients of different quality are not known a priori. We consider a mini-batch oracle that distributes a limited query budget over a number of stochastic gradients and aggregates them to estimate the true gradient. Since the optimal mini-batch size depends on the unknown cost-fidelity function, we propose an algorithm, {\it EE-Grad}, that sequentially explores the performance of mini-batch oracles and exploits the accumulated knowledge to estimate the one achieving the best performance in terms of cost-efficiency. We provide performance guarantees for EE-Grad with respect to the optimal mini-batch oracle, and illustrate these results in the case of strongly convex objectives. We also provide a simple numerical example that corroborates our theoretical findings.
A Deterministic Analysis of an Online Convex Mixture of Expert Algorithms
Sep 28, 2012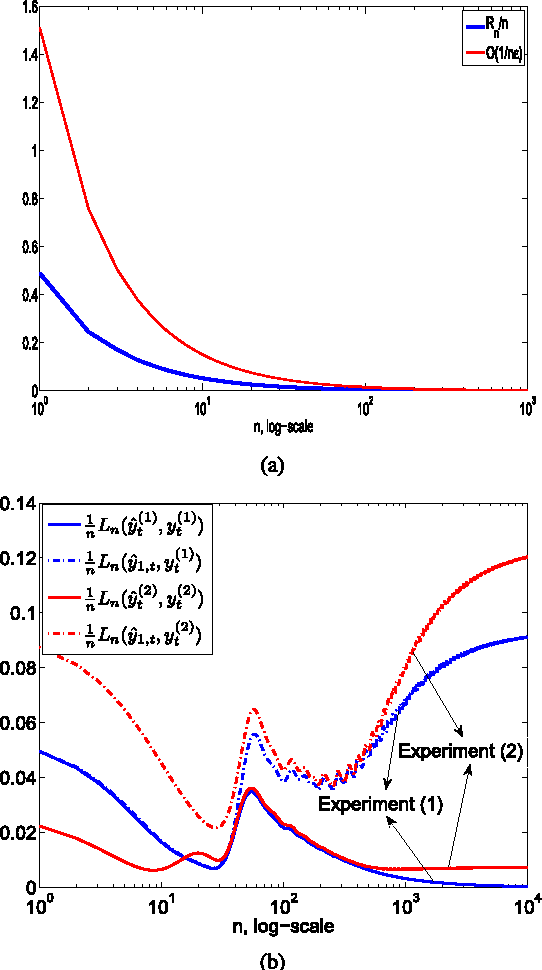

We analyze an online learning algorithm that adaptively combines outputs of two constituent algorithms (or the experts) running in parallel to model an unknown desired signal. This online learning algorithm is shown to achieve (and in some cases outperform) the mean-square error (MSE) performance of the best constituent algorithm in the mixture in the steady-state. However, the MSE analysis of this algorithm in the literature uses approximations and relies on statistical models on the underlying signals and systems. Hence, such an analysis may not be useful or valid for signals generated by various real life systems that show high degrees of nonstationarity, limit cycles and, in many cases, that are even chaotic. In this paper, we produce results in an individual sequence manner. In particular, we relate the time-accumulated squared estimation error of this online algorithm at any time over any interval to the time accumulated squared estimation error of the optimal convex mixture of the constituent algorithms directly tuned to the underlying signal in a deterministic sense without any statistical assumptions. In this sense, our analysis provides the transient, steady-state and tracking behavior of this algorithm in a strong sense without any approximations in the derivations or statistical assumptions on the underlying signals such that our results are guaranteed to hold. We illustrate the introduced results through examples.
Adaptive Mixture Methods Based on Bregman Divergences
Mar 20, 2012

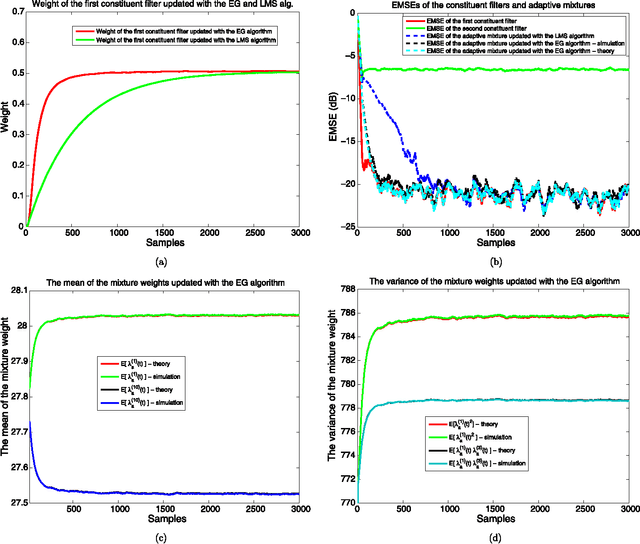
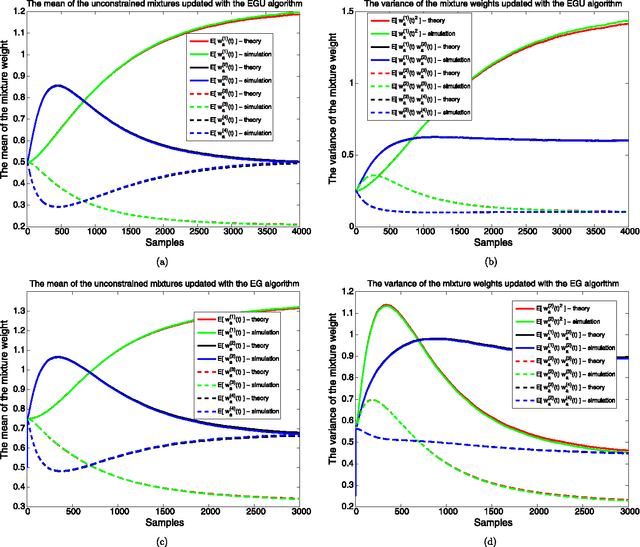
We investigate adaptive mixture methods that linearly combine outputs of $m$ constituent filters running in parallel to model a desired signal. We use "Bregman divergences" and obtain certain multiplicative updates to train the linear combination weights under an affine constraint or without any constraints. We use unnormalized relative entropy and relative entropy to define two different Bregman divergences that produce an unnormalized exponentiated gradient update and a normalized exponentiated gradient update on the mixture weights, respectively. We then carry out the mean and the mean-square transient analysis of these adaptive algorithms when they are used to combine outputs of $m$ constituent filters. We illustrate the accuracy of our results and demonstrate the effectiveness of these updates for sparse mixture systems.