 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTransfer learning for conflict and duplicate detection in software requirement pairs
Jan 09, 2023
Consistent and holistic expression of software requirements is important for the success of software projects. In this study, we aim to enhance the efficiency of the software development processes by automatically identifying conflicting and duplicate software requirement specifications. We formulate the conflict and duplicate detection problem as a requirement pair classification task. We design a novel transformers-based architecture, SR-BERT, which incorporates Sentence-BERT and Bi-encoders for the conflict and duplicate identification task. Furthermore, we apply supervised multi-stage fine-tuning to the pre-trained transformer models. We test the performance of different transfer models using four different datasets. We find that sequentially trained and fine-tuned transformer models perform well across the datasets with SR-BERT achieving the best performance for larger datasets. We also explore the cross-domain performance of conflict detection models and adopt a rule-based filtering approach to validate the model classifications. Our analysis indicates that the sentence pair classification approach and the proposed transformer-based natural language processing strategies can contribute significantly to achieving automation in conflict and duplicate detection
Deep Super Learner: A Deep Ensemble for Classification Problems
Mar 06, 2018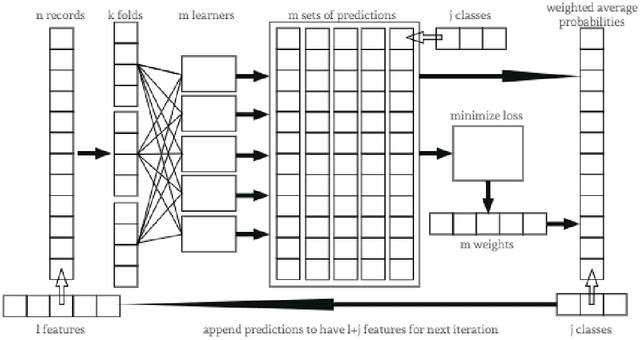


Deep learning has become very popular for tasks such as predictive modeling and pattern recognition in handling big data. Deep learning is a powerful machine learning method that extracts lower level features and feeds them forward for the next layer to identify higher level features that improve performance. However, deep neural networks have drawbacks, which include many hyper-parameters and infinite architectures, opaqueness into results, and relatively slower convergence on smaller datasets. While traditional machine learning algorithms can address these drawbacks, they are not typically capable of the performance levels achieved by deep neural networks. To improve performance, ensemble methods are used to combine multiple base learners. Super learning is an ensemble that finds the optimal combination of diverse learning algorithms. This paper proposes deep super learning as an approach which achieves log loss and accuracy results competitive to deep neural networks while employing traditional machine learning algorithms in a hierarchical structure. The deep super learner is flexible, adaptable, and easy to train with good performance across different tasks using identical hyper-parameter values. Using traditional machine learning requires fewer hyper-parameters, allows transparency into results, and has relatively fast convergence on smaller datasets. Experimental results show that the deep super learner has superior performance compared to the individual base learners, single-layer ensembles, and in some cases deep neural networks. Performance of the deep super learner may further be improved with task-specific tuning.