 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning Transformer-based Encoder for Turkish Language Understanding Tasks
Jan 30, 2024Deep learning-based and lately Transformer-based language models have been dominating the studies of natural language processing in the last years. Thanks to their accurate and fast fine-tuning characteristics, they have outperformed traditional machine learning-based approaches and achieved state-of-the-art results for many challenging natural language understanding (NLU) problems. Recent studies showed that the Transformer-based models such as BERT, which is Bidirectional Encoder Representations from Transformers, have reached impressive achievements on many tasks. Moreover, thanks to their transfer learning capacity, these architectures allow us to transfer pre-built models and fine-tune them to specific NLU tasks such as question answering. In this study, we provide a Transformer-based model and a baseline benchmark for the Turkish Language. We successfully fine-tuned a Turkish BERT model, namely BERTurk that is trained with base settings, to many downstream tasks and evaluated with a the Turkish Benchmark dataset. We showed that our studies significantly outperformed other existing baseline approaches for Named-Entity Recognition, Sentiment Analysis, Question Answering and Text Classification in Turkish Language. We publicly released these four fine-tuned models and resources in reproducibility and with the view of supporting other Turkish researchers and applications.
Transfer learning for conflict and duplicate detection in software requirement pairs
Jan 09, 2023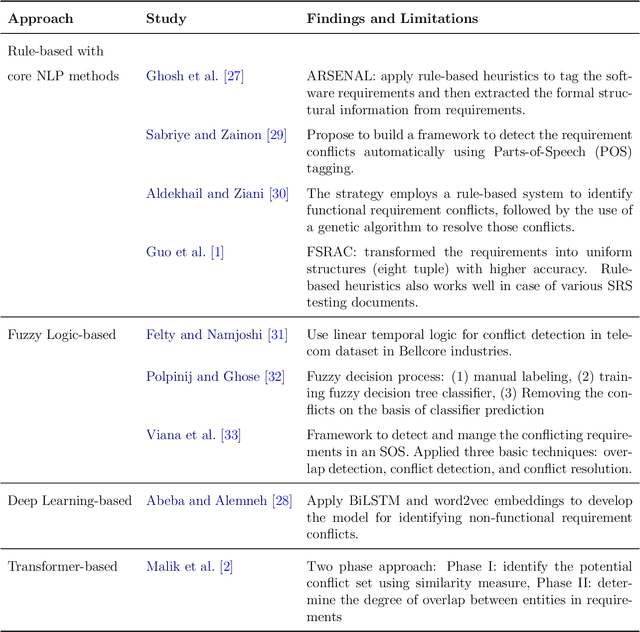
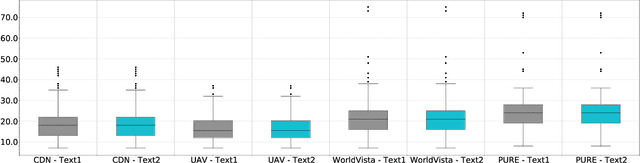
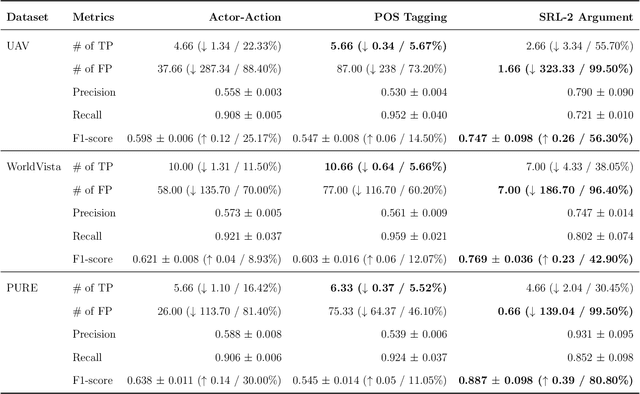
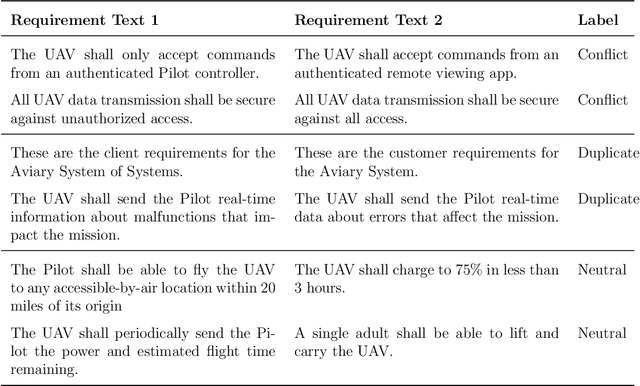
Consistent and holistic expression of software requirements is important for the success of software projects. In this study, we aim to enhance the efficiency of the software development processes by automatically identifying conflicting and duplicate software requirement specifications. We formulate the conflict and duplicate detection problem as a requirement pair classification task. We design a novel transformers-based architecture, SR-BERT, which incorporates Sentence-BERT and Bi-encoders for the conflict and duplicate identification task. Furthermore, we apply supervised multi-stage fine-tuning to the pre-trained transformer models. We test the performance of different transfer models using four different datasets. We find that sequentially trained and fine-tuned transformer models perform well across the datasets with SR-BERT achieving the best performance for larger datasets. We also explore the cross-domain performance of conflict detection models and adopt a rule-based filtering approach to validate the model classifications. Our analysis indicates that the sentence pair classification approach and the proposed transformer-based natural language processing strategies can contribute significantly to achieving automation in conflict and duplicate detection
Token Classification for Disambiguating Medical Abbreviations
Oct 05, 2022
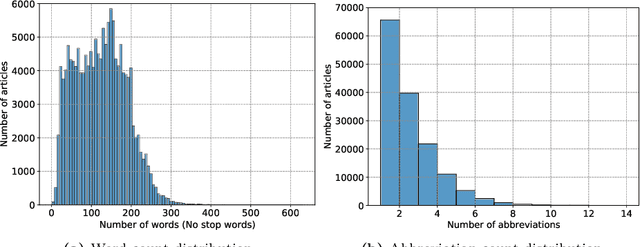
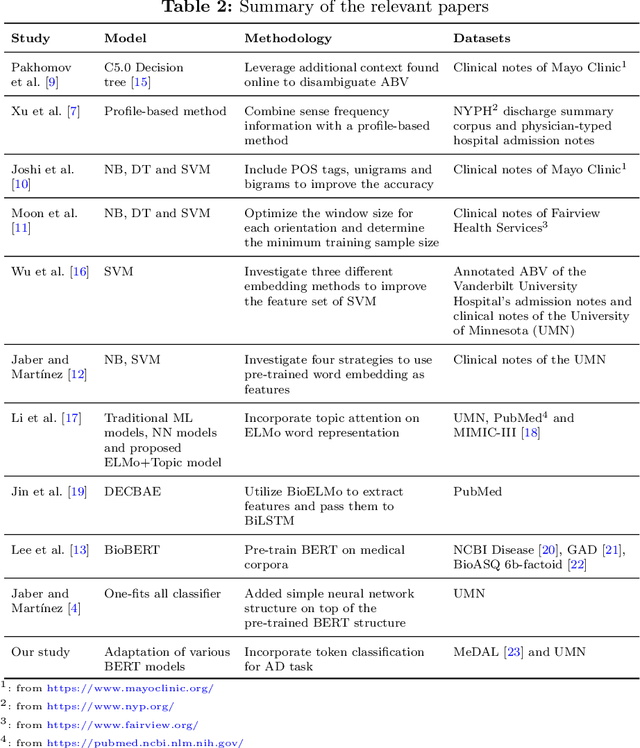
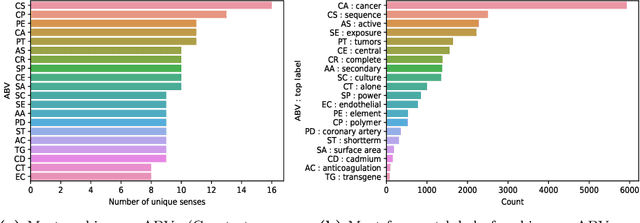
Abbreviations are unavoidable yet critical parts of the medical text. Using abbreviations, especially in clinical patient notes, can save time and space, protect sensitive information, and help avoid repetitions. However, most abbreviations might have multiple senses, and the lack of a standardized mapping system makes disambiguating abbreviations a difficult and time-consuming task. The main objective of this study is to examine the feasibility of token classification methods for medical abbreviation disambiguation. Specifically, we explore the capability of token classification methods to deal with multiple unique abbreviations in a single text. We use two public datasets to compare and contrast the performance of several transformer models pre-trained on different scientific and medical corpora. Our proposed token classification approach outperforms the more commonly used text classification models for the abbreviation disambiguation task. In particular, the SciBERT model shows a strong performance for both token and text classification tasks over the two considered datasets. Furthermore, we find that abbreviation disambiguation performance for the text classification models becomes comparable to that of token classification only when postprocessing is applied to their predictions, which involves filtering possible labels for an abbreviation based on the training data.