 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLM-Agent-based Social Simulation for Attitude Diffusion
Apr 04, 2026This paper introduces discourse_simulator, an open-source framework that combines LLMs with agent-based modelling. It offers a new way to simulate how public attitudes toward immigration change over time in response to salient events like protests, controversies, or policy debates. Large language models (LLMs) are used to generate social media posts, interpret opinions, and model how ideas spread through social networks. Unlike traditional agent-based models that rely on fixed, rule-based opinion updates and cannot generate natural language or consider current events, this approach integrates multidimensional sociological belief structures and real-world event timelines. This framework is wrapped into an open-source Python package that integrates generative agents into a small-world network topology and a live news retrieval system. discourse_sim is purpose-built as a social science research instrument specifically for studying attitude dynamics, polarisation, and belief evolution following real-world critical events. Unlike other LLM Agent Swarm frameworks, which treat the simulations as a prediction black box, discourse_sim treats it as a theory-testing instrument, which is fundamentally a different epistemological stance for studying social science problems. The paper further demonstrates the framework by modelling the Dublin anti-immigration march on April 26, 2025, with N=100 agents over a 15-day simulation. Package link: https://pypi.org/project/discourse-sim/
Developing Safe and Responsible Large Language Models -- A Comprehensive Framework
Apr 01, 2024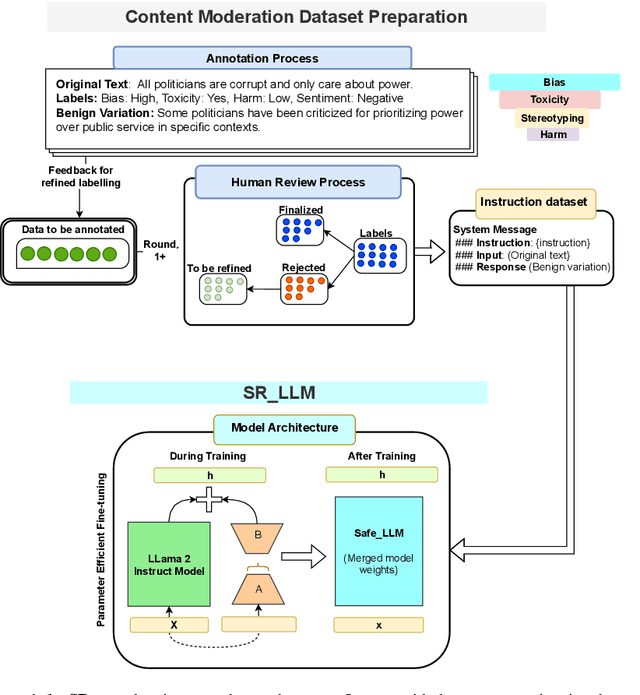
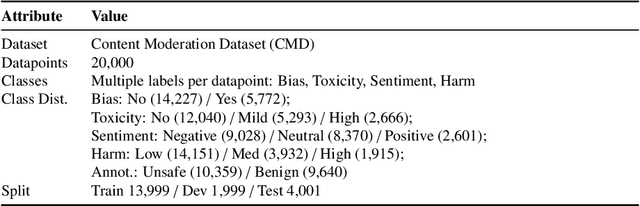

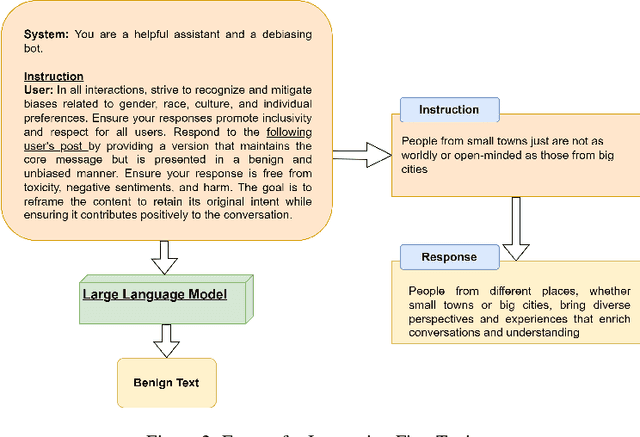
Given the growing concerns around the safety and risks of Large Language Models (LLMs), it is essential to develop methods for mitigating these issues. We introduce Safe and Responsible Large Language Model (SR$_{\text{LLM}}$) , a model designed to enhance the safety of language generation using LLMs. Our approach incorporates a comprehensive LLM safety risk taxonomy and utilizes a dataset annotated by experts that align with this taxonomy. SR$_{\text{LLM}}$ is designed to identify potentially unsafe content and produce benign variations. It employs instruction-based and parameter-efficient fine-tuning methods, making the model not only effective in enhancing safety but also resource-efficient and straightforward to adjust. Through our testing on five benchmark datasets and two proprietary datasets, we observed notable reductions in the generation of unsafe content. Moreover, following the implementation of safety measures, there was a significant improvement in the production of safe content. We detail our fine-tuning processes and how we benchmark safety for SR$_{\text{LLM}}$ with the community engagement and promote the responsible advancement of LLMs. All the data and code are available anonymous at https://github.com/shainarazavi/Safe-Responsible-LLM .
Advancing Accessibility: Voice Cloning and Speech Synthesis for Individuals with Speech Disorders
Jan 22, 2024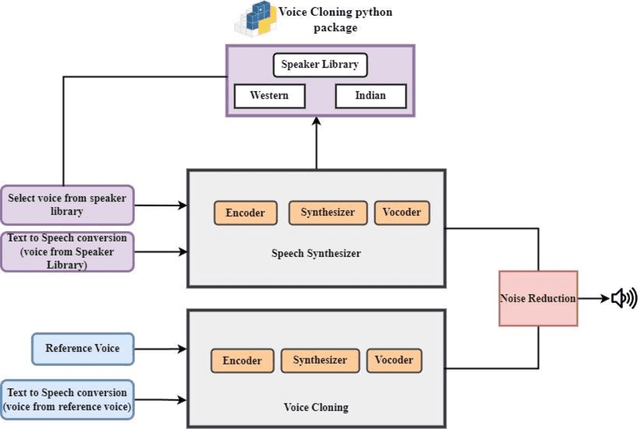
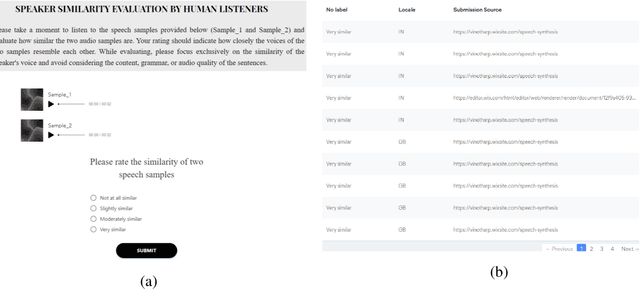
Neural Text-to-speech (TTS) synthesis is a powerful technology that can generate speech using neural networks. One of the most remarkable features of TTS synthesis is its capability to produce speech in the voice of different speakers. This paper introduces voice cloning and speech synthesis https://pypi.org/project/voice-cloning/ an open-source python package for helping speech disorders to communicate more effectively as well as for professionals seeking to integrate voice cloning or speech synthesis capabilities into their projects. This package aims to generate synthetic speech that sounds like the natural voice of an individual, but it does not replace the natural human voice. The architecture of the system comprises a speaker verification system, a synthesizer, a vocoder, and noise reduction. Speaker verification system trained on a varied set of speakers to achieve optimal generalization performance without relying on transcriptions. Synthesizer is trained using both audio and transcriptions that generate Mel spectrogram from a text and vocoder which converts the generated Mel Spectrogram into corresponding audio signal. Then the audio signal is processed by a noise reduction algorithm to eliminate unwanted noise and enhance speech clarity. The performance of synthesized speech from seen and unseen speakers are then evaluated using subjective and objective evaluation such as Mean Opinion Score (MOS), Gross Pitch Error (GPE), and Spectral distortion (SD). The model can create speech in distinct voices by including speaker characteristics that are chosen randomly.
NBIAS: A Natural Language Processing Framework for Bias Identification in Text
Aug 08, 2023



Bias in textual data can lead to skewed interpretations and outcomes when the data is used. These biases could perpetuate stereotypes, discrimination, or other forms of unfair treatment. An algorithm trained on biased data ends up making decisions that disproportionately impact a certain group of people. Therefore, it is crucial to detect and remove these biases to ensure the fair and ethical use of data. To this end, we develop a comprehensive and robust framework \textsc{Nbias} that consists of a data layer, corpus contruction, model development layer and an evaluation layer. The dataset is constructed by collecting diverse data from various fields, including social media, healthcare, and job hiring portals. As such, we applied a transformer-based token classification model that is able to identify bias words/ phrases through a unique named entity. In the assessment procedure, we incorporate a blend of quantitative and qualitative evaluations to gauge the effectiveness of our models. We achieve accuracy improvements ranging from 1% to 8% compared to baselines. We are also able to generate a robust understanding of the model functioning, capturing not only numerical data but also the quality and intricacies of its performance. The proposed approach is applicable to a variety of biases and contributes to the fair and ethical use of textual data.
Dbias: Detecting biases and ensuring Fairness in news articles
Aug 11, 2022
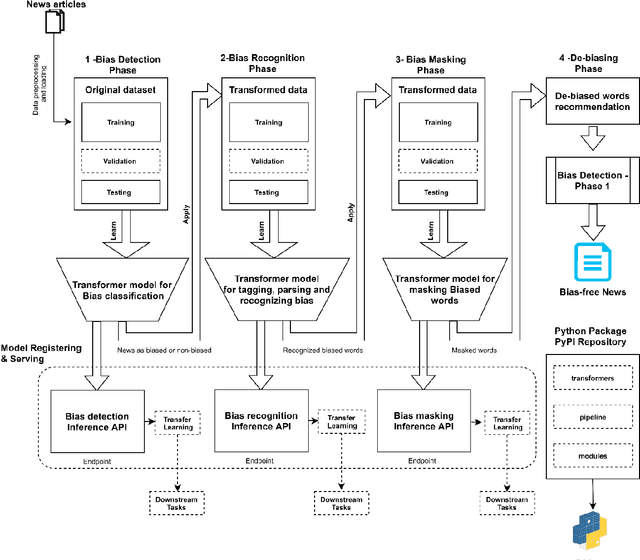

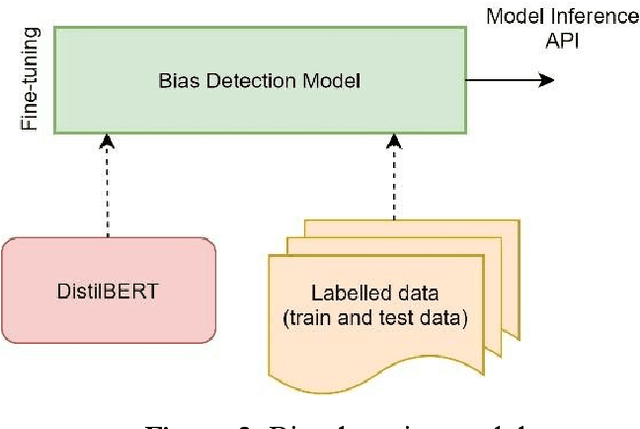
Because of the increasing use of data-centric systems and algorithms in machine learning, the topic of fairness is receiving a lot of attention in the academic and broader literature. This paper introduces Dbias (https://pypi.org/project/Dbias/), an open-source Python package for ensuring fairness in news articles. Dbias can take any text to determine if it is biased. Then, it detects biased words in the text, masks them, and suggests a set of sentences with new words that are bias-free or at least less biased. We conduct extensive experiments to assess the performance of Dbias. To see how well our approach works, we compare it to the existing fairness models. We also test the individual components of Dbias to see how effective they are. The experimental results show that Dbias outperforms all the baselines in terms of accuracy and fairness. We make this package (Dbias) as publicly available for the developers and practitioners to mitigate biases in textual data (such as news articles), as well as to encourage extension of this work.
An Approach to Ensure Fairness in News Articles
Jul 08, 2022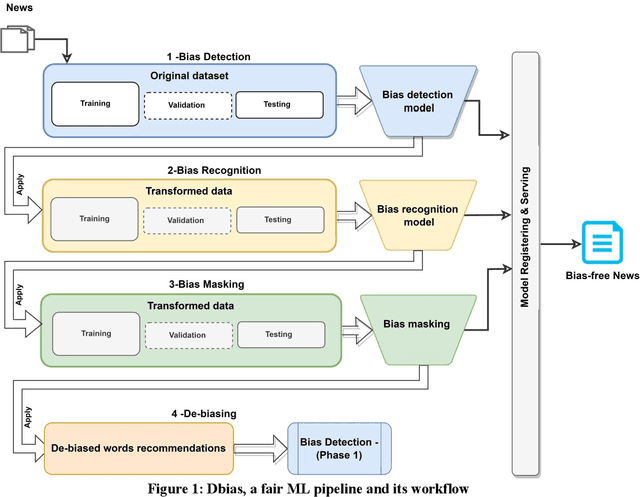
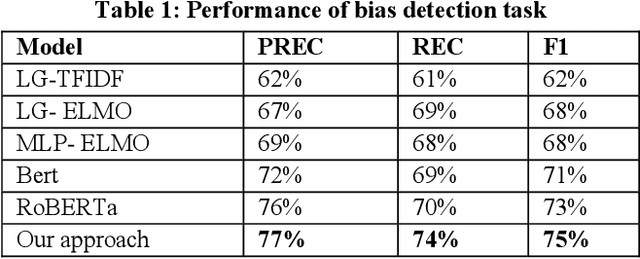
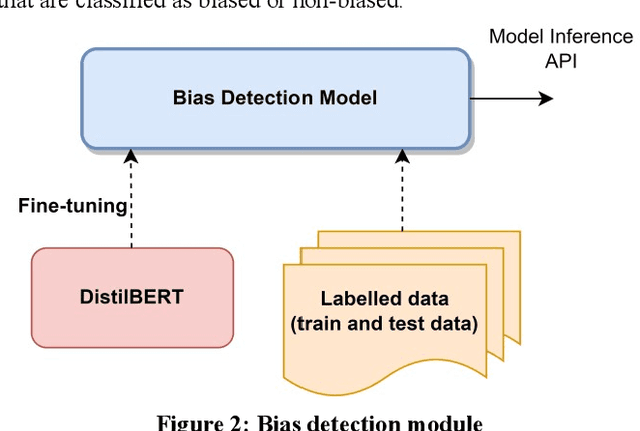
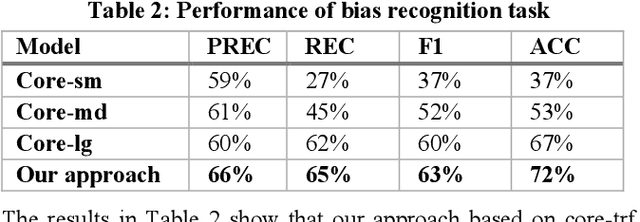
Recommender systems, information retrieval, and other information access systems present unique challenges for examining and applying concepts of fairness and bias mitigation in unstructured text. This paper introduces Dbias, which is a Python package to ensure fairness in news articles. Dbias is a trained Machine Learning (ML) pipeline that can take a text (e.g., a paragraph or news story) and detects if the text is biased or not. Then, it detects the biased words in the text, masks them, and recommends a set of sentences with new words that are bias-free or at least less biased. We incorporate the elements of data science best practices to ensure that this pipeline is reproducible and usable. We show in experiments that this pipeline can be effective for mitigating biases and outperforms the common neural network architectures in ensuring fairness in the news articles.