 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Safe and Responsible Large Language Models -- A Comprehensive Framework
Paper and Code
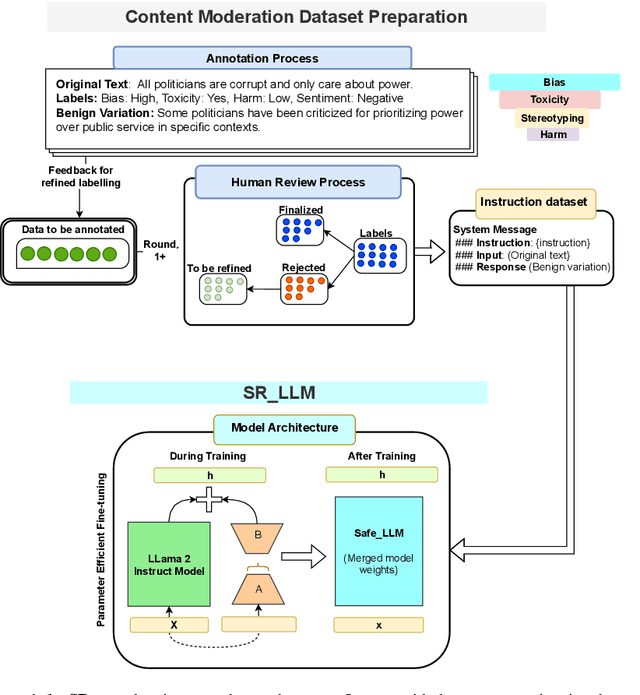
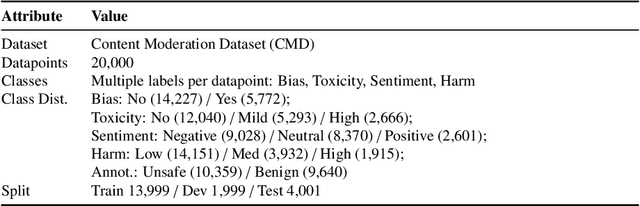

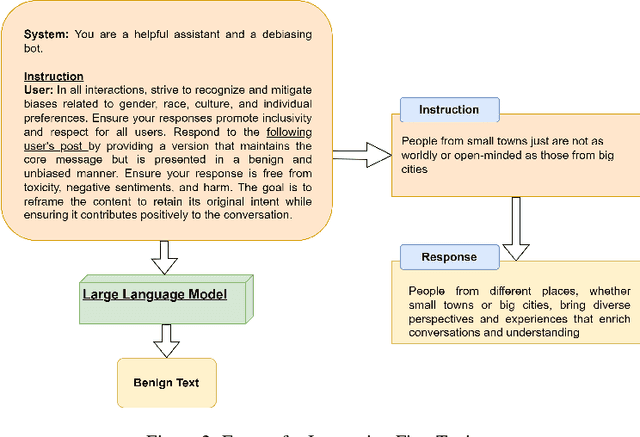
Given the growing concerns around the safety and risks of Large Language Models (LLMs), it is essential to develop methods for mitigating these issues. We introduce Safe and Responsible Large Language Model (SR$_{\text{LLM}}$) , a model designed to enhance the safety of language generation using LLMs. Our approach incorporates a comprehensive LLM safety risk taxonomy and utilizes a dataset annotated by experts that align with this taxonomy. SR$_{\text{LLM}}$ is designed to identify potentially unsafe content and produce benign variations. It employs instruction-based and parameter-efficient fine-tuning methods, making the model not only effective in enhancing safety but also resource-efficient and straightforward to adjust. Through our testing on five benchmark datasets and two proprietary datasets, we observed notable reductions in the generation of unsafe content. Moreover, following the implementation of safety measures, there was a significant improvement in the production of safe content. We detail our fine-tuning processes and how we benchmark safety for SR$_{\text{LLM}}$ with the community engagement and promote the responsible advancement of LLMs. All the data and code are available anonymous at https://github.com/shainarazavi/Safe-Responsible-LLM .