 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeveloping Safe and Responsible Large Language Models -- A Comprehensive Framework
Apr 01, 2024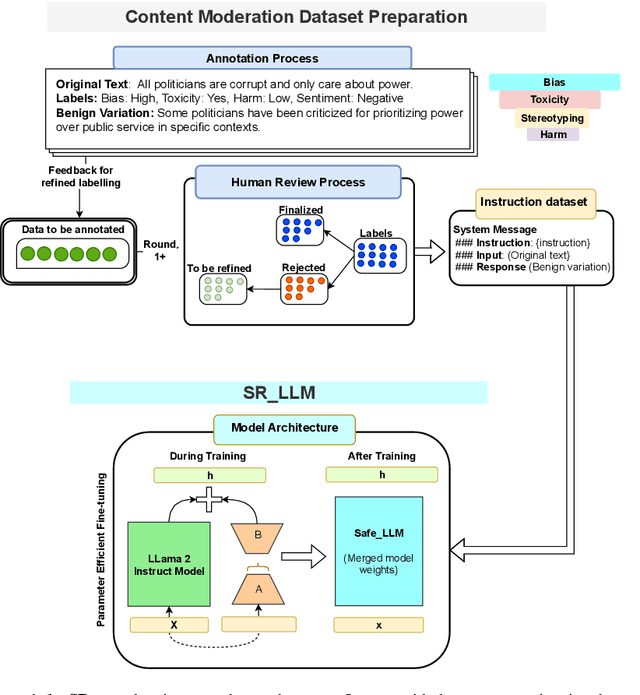
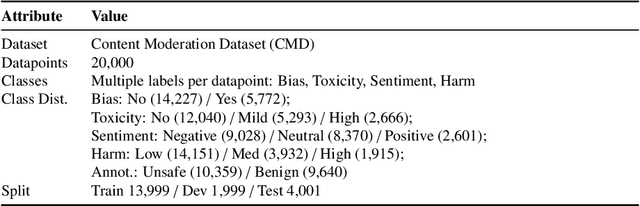

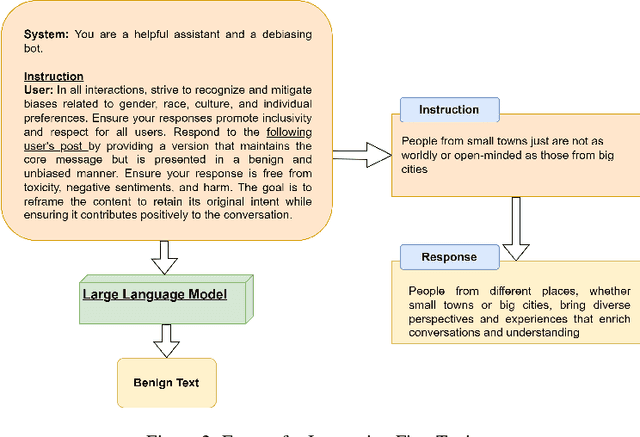
Given the growing concerns around the safety and risks of Large Language Models (LLMs), it is essential to develop methods for mitigating these issues. We introduce Safe and Responsible Large Language Model (SR$_{\text{LLM}}$) , a model designed to enhance the safety of language generation using LLMs. Our approach incorporates a comprehensive LLM safety risk taxonomy and utilizes a dataset annotated by experts that align with this taxonomy. SR$_{\text{LLM}}$ is designed to identify potentially unsafe content and produce benign variations. It employs instruction-based and parameter-efficient fine-tuning methods, making the model not only effective in enhancing safety but also resource-efficient and straightforward to adjust. Through our testing on five benchmark datasets and two proprietary datasets, we observed notable reductions in the generation of unsafe content. Moreover, following the implementation of safety measures, there was a significant improvement in the production of safe content. We detail our fine-tuning processes and how we benchmark safety for SR$_{\text{LLM}}$ with the community engagement and promote the responsible advancement of LLMs. All the data and code are available anonymous at https://github.com/shainarazavi/Safe-Responsible-LLM .
FAIR Enough: How Can We Develop and Assess a FAIR-Compliant Dataset for Large Language Models' Training?
Jan 23, 2024The rapid evolution of Large Language Models (LLMs) underscores the critical importance of ethical considerations and data integrity in AI development, emphasizing the role of FAIR (Findable, Accessible, Interoperable, Reusable) data principles. While these principles have long been a cornerstone of ethical data stewardship, their application in LLM training data is less prevalent, an issue our research aims to address. Our study begins with a review of existing literature, highlighting the significance of FAIR principles in data management for model training. Building on this foundation, we introduce a novel framework that incorporates FAIR principles into the LLM training process. A key aspect of this approach is a comprehensive checklist, designed to assist researchers and developers in consistently applying FAIR data principles throughout the model development lifecycle. The practicality and effectiveness of our framework are demonstrated through a case study that involves creating a FAIR-compliant dataset to detect and reduce biases. This case study not only validates the usefulness of our framework but also establishes new benchmarks for more equitable, transparent, and ethical practices in LLM training. We offer this framework to the community as a means to promote technologically advanced, ethically sound, and socially responsible AI models.
Unlocking Bias Detection: Leveraging Transformer-Based Models for Content Analysis
Oct 14, 2023



Bias detection in text is imperative due to its role in reinforcing negative stereotypes, disseminating misinformation, and influencing decisions. Current language models often fall short in generalizing beyond their training sets. In response, we introduce the Contextualized Bi-Directional Dual Transformer (CBDT) Classifier. This novel architecture utilizes two synergistic transformer networks: the Context Transformer and the Entity Transformer, aiming for enhanced bias detection. Our dataset preparation follows the FAIR principles, ensuring ethical data usage. Through rigorous testing on various datasets, CBDT showcases its ability in distinguishing biased from neutral statements, while also pinpointing exact biased lexemes. Our approach outperforms existing methods, achieving a 2-4\% increase over benchmark performances. This opens avenues for adapting the CBDT model across diverse linguistic and cultural landscapes.