 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOnline Federation For Mixtures of Proprietary Agents with Black-Box Encoders
Apr 30, 2025



Most industry-standard generative AIs and feature encoders are proprietary, offering only black-box access: their outputs are observable, but their internal parameters and architectures remain hidden from the end-user. This black-box access is especially limiting when constructing mixture-of-expert type ensemble models since the user cannot optimize each proprietary AI's internal parameters. Our problem naturally lends itself to a non-competitive game-theoretic lens where each proprietary AI (agent) is inherently competing against the other AI agents, with this competition arising naturally due to their obliviousness of the AI's to their internal structure. In contrast, the user acts as a central planner trying to synchronize the ensemble of competing AIs. We show the existence of the unique Nash equilibrium in the online setting, which we even compute in closed-form by eliciting a feedback mechanism between any given time series and the sequence generated by each (proprietary) AI agent. Our solution is implemented as a decentralized, federated-learning algorithm in which each agent optimizes their structure locally on their machine without ever releasing any internal structure to the others. We obtain refined expressions for pre-trained models such as transformers, random feature models, and echo-state networks. Our ``proprietary federated learning'' algorithm is implemented on a range of real-world and synthetic time-series benchmarks. It achieves orders-of-magnitude improvements in predictive accuracy over natural benchmarks, of which there are surprisingly few due to this natural problem still being largely unexplored.
Neural Operators Can Play Dynamic Stackelberg Games
Nov 14, 2024


Dynamic Stackelberg games are a broad class of two-player games in which the leader acts first, and the follower chooses a response strategy to the leader's strategy. Unfortunately, only stylized Stackelberg games are explicitly solvable since the follower's best-response operator (as a function of the control of the leader) is typically analytically intractable. This paper addresses this issue by showing that the \textit{follower's best-response operator} can be approximately implemented by an \textit{attention-based neural operator}, uniformly on compact subsets of adapted open-loop controls for the leader. We further show that the value of the Stackelberg game where the follower uses the approximate best-response operator approximates the value of the original Stackelberg game. Our main result is obtained using our universal approximation theorem for attention-based neural operators between spaces of square-integrable adapted stochastic processes, as well as stability results for a general class of Stackelberg games.
Reality Only Happens Once: Single-Path Generalization Bounds for Transformers
May 26, 2024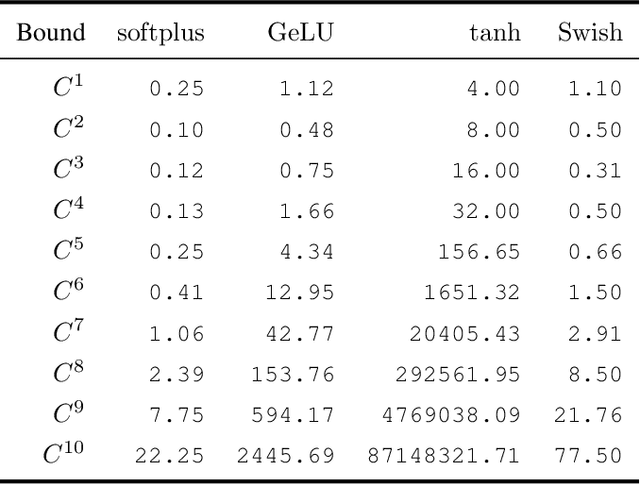
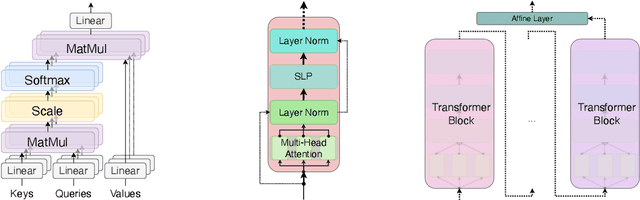

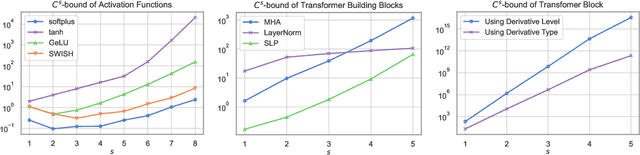
One of the inherent challenges in deploying transformers on time series is that \emph{reality only happens once}; namely, one typically only has access to a single trajectory of the data-generating process comprised of non-i.i.d. observations. We derive non-asymptotic statistical guarantees in this setting through bounds on the \textit{generalization} of a transformer network at a future-time $t$, given that it has been trained using $N\le t$ observations from a single perturbed trajectory of a Markov process. Under the assumption that the Markov process satisfies a log-Sobolev inequality, we obtain a generalization bound which effectively converges at the rate of ${O}(1/\sqrt{N})$. Our bound depends explicitly on the activation function ($\operatorname{Swish}$, $\operatorname{GeLU}$, or $\tanh$ are considered), the number of self-attention heads, depth, width, and norm-bounds defining the transformer architecture. Our bound consists of three components: (I) The first quantifies the gap between the stationary distribution of the data-generating Markov process and its distribution at time $t$, this term converges exponentially to $0$. (II) The next term encodes the complexity of the transformer model and, given enough time, eventually converges to $0$ at the rate ${O}(\log(N)^r/\sqrt{N})$ for any $r>0$. (III) The third term guarantees that the bound holds with probability at least $1$-$\delta$, and converges at a rate of ${O}(\sqrt{\log(1/\delta)}/\sqrt{N})$.
Deep Kalman Filters Can Filter
Oct 30, 2023Deep Kalman filters (DKFs) are a class of neural network models that generate Gaussian probability measures from sequential data. Though DKFs are inspired by the Kalman filter, they lack concrete theoretical ties to the stochastic filtering problem, thus limiting their applicability to areas where traditional model-based filters have been used, e.g.\ model calibration for bond and option prices in mathematical finance. We address this issue in the mathematical foundations of deep learning by exhibiting a class of continuous-time DKFs which can approximately implement the conditional law of a broad class of non-Markovian and conditionally Gaussian signal processes given noisy continuous-times measurements. Our approximation results hold uniformly over sufficiently regular compact subsets of paths, where the approximation error is quantified by the worst-case 2-Wasserstein distance computed uniformly over the given compact set of paths.
Regret-Optimal Federated Transfer Learning for Kernel Regression with Applications in American Option Pricing
Sep 08, 2023



We propose an optimal iterative scheme for federated transfer learning, where a central planner has access to datasets ${\cal D}_1,\dots,{\cal D}_N$ for the same learning model $f_{\theta}$. Our objective is to minimize the cumulative deviation of the generated parameters $\{\theta_i(t)\}_{t=0}^T$ across all $T$ iterations from the specialized parameters $\theta^\star_{1},\ldots,\theta^\star_N$ obtained for each dataset, while respecting the loss function for the model $f_{\theta(T)}$ produced by the algorithm upon halting. We only allow for continual communication between each of the specialized models (nodes/agents) and the central planner (server), at each iteration (round). For the case where the model $f_{\theta}$ is a finite-rank kernel regression, we derive explicit updates for the regret-optimal algorithm. By leveraging symmetries within the regret-optimal algorithm, we further develop a nearly regret-optimal heuristic that runs with $\mathcal{O}(Np^2)$ fewer elementary operations, where $p$ is the dimension of the parameter space. Additionally, we investigate the adversarial robustness of the regret-optimal algorithm showing that an adversary which perturbs $q$ training pairs by at-most $\varepsilon>0$, across all training sets, cannot reduce the regret-optimal algorithm's regret by more than $\mathcal{O}(\varepsilon q \bar{N}^{1/2})$, where $\bar{N}$ is the aggregate number of training pairs. To validate our theoretical findings, we conduct numerical experiments in the context of American option pricing, utilizing a randomly generated finite-rank kernel.