 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversal Time Series Generation with Neural Controlled Differential Equations
May 27, 2026Recent work on the sequence universality of State Space Models (SSMs) has introduced efficient, maximally expressive continuous-time approaches for time-series modelling. While these works focus on discriminative settings, we extend this perspective to generative time-series modelling by proving that maximally expressive Structured Linear Controlled Differential Equations (SLiCEs) are universal time-series generators, in the sense that they can approximate the induced path laws of continuous causal pushforwards on compact latent sets in $W_\infty$. Building on these theoretical results, we propose Generative SLiCEs (G-SLiCEs), a maximally expressive continuous-time model for flow matching on path-space. Empirically, we show that expressivity improves performance in probabilistic forecasting and downstream tasks, while retaining the advantages of continuous-time models such as generalising to arbitrary observation grids. This is particularly beneficial for irregular grids, where fixed-grid models often struggle.
Seeking SOTA: Time-Series Forecasting Must Adopt Taxonomy-Specific Evaluation to Dispel Illusory Gains
Mar 16, 2026We argue that the current practice of evaluating AI/ML time-series forecasting models, predominantly on benchmarks characterized by strong, persistent periodicities and seasonalities, obscures real progress by overlooking the performance of efficient classical methods. We demonstrate that these "standard" datasets often exhibit dominant autocorrelation patterns and seasonal cycles that can be effectively captured by simpler linear or statistical models, rendering complex deep learning architectures frequently no more performant than their classical counterparts for these specific data characteristics, and raising questions as to whether any marginal improvements justify the significant increase in computational overhead and model complexity. We call on the community to (I) retire or substantially augment current benchmarks with datasets exhibiting a wider spectrum of non-stationarities, such as structural breaks, time-varying volatility, and concept drift, and less predictable dynamics drawn from diverse real-world domains, and (II) require every deep learning submission to include robust classical and simple baselines, appropriately chosen for the specific characteristics of the downstream tasks' time series. By doing so, we will help ensure that reported gains reflect genuine scientific methodological advances rather than artifacts of benchmark selection favoring models adept at learning repetitive patterns.
Contrastive Similarity Learning for Market Forecasting: The ContraSim Framework
Feb 22, 2025



We introduce the Contrastive Similarity Space Embedding Algorithm (ContraSim), a novel framework for uncovering the global semantic relationships between daily financial headlines and market movements. ContraSim operates in two key stages: (I) Weighted Headline Augmentation, which generates augmented financial headlines along with a semantic fine-grained similarity score, and (II) Weighted Self-Supervised Contrastive Learning (WSSCL), an extended version of classical self-supervised contrastive learning that uses the similarity metric to create a refined weighted embedding space. This embedding space clusters semantically similar headlines together, facilitating deeper market insights. Empirical results demonstrate that integrating ContraSim features into financial forecasting tasks improves classification accuracy from WSJ headlines by 7%. Moreover, leveraging an information density analysis, we find that the similarity spaces constructed by ContraSim intrinsically cluster days with homogeneous market movement directions, indicating that ContraSim captures market dynamics independent of ground truth labels. Additionally, ContraSim enables the identification of historical news days that closely resemble the headlines of the current day, providing analysts with actionable insights to predict market trends by referencing analogous past events.
What Teaches Robots to Walk, Teaches Them to Trade too -- Regime Adaptive Execution using Informed Data and LLMs
Jun 20, 2024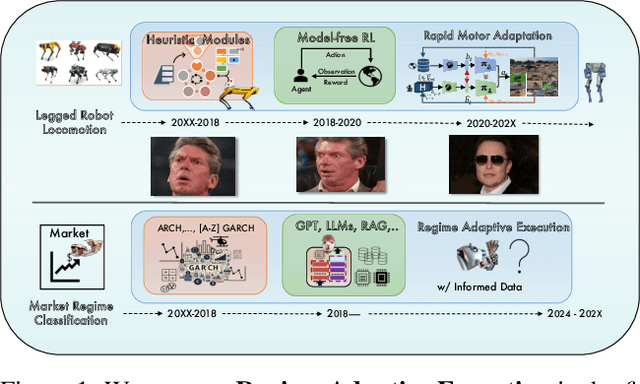
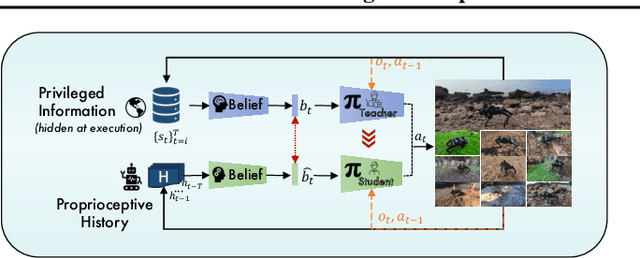
Machine learning techniques applied to the problem of financial market forecasting struggle with dynamic regime switching, or underlying correlation and covariance shifts in true (hidden) market variables. Drawing inspiration from the success of reinforcement learning in robotics, particularly in agile locomotion adaptation of quadruped robots to unseen terrains, we introduce an innovative approach that leverages world knowledge of pretrained LLMs (aka. 'privileged information' in robotics) and dynamically adapts them using intrinsic, natural market rewards using LLM alignment technique we dub as "Reinforcement Learning from Market Feedback" (**RLMF**). Strong empirical results demonstrate the efficacy of our method in adapting to regime shifts in financial markets, a challenge that has long plagued predictive models in this domain. The proposed algorithmic framework outperforms best-performing SOTA LLM models on the existing (FLARE) benchmark stock-movement (SM) tasks by more than 15\% improved accuracy. On the recently proposed NIFTY SM task, our adaptive policy outperforms the SOTA best performing trillion parameter models like GPT-4. The paper details the dual-phase, teacher-student architecture and implementation of our model, the empirical results obtained, and an analysis of the role of language embeddings in terms of Information Gain.
Filtered not Mixed: Stochastic Filtering-Based Online Gating for Mixture of Large Language Models
Jun 05, 2024
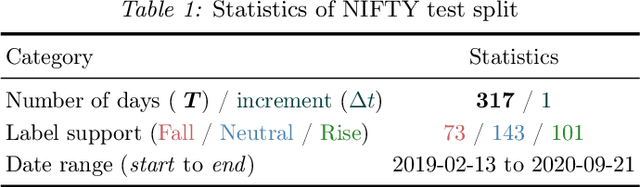
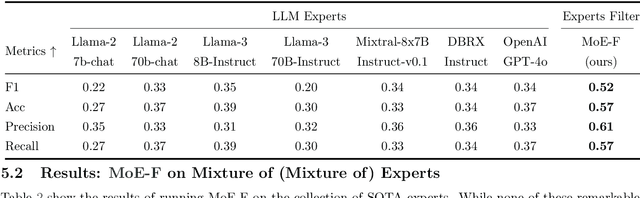
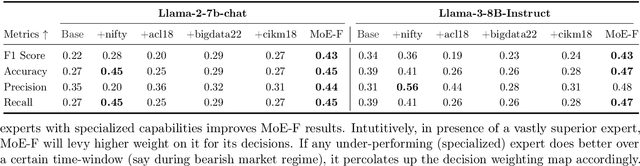
We propose MoE-F -- a formalised mechanism for combining $N$ pre-trained expert Large Language Models (LLMs) in online time-series prediction tasks by adaptively forecasting the best weighting of LLM predictions at every time step. Our mechanism leverages the conditional information in each expert's running performance to forecast the best combination of LLMs for predicting the time series in its next step. Diverging from static (learned) Mixture of Experts (MoE) methods, MoE-F employs time-adaptive stochastic filtering techniques to combine experts. By framing the expert selection problem as a finite state-space, continuous-time Hidden Markov model (HMM), we can leverage the Wohman-Shiryaev filter. Our approach first constructs $N$ parallel filters corresponding to each of the $N$ individual LLMs. Each filter proposes its best combination of LLMs, given the information that they have access to. Subsequently, the $N$ filter outputs are aggregated to optimize a lower bound for the loss of the aggregated LLMs, which can be optimized in closed-form, thus generating our ensemble predictor. Our contributions here are: (I) the MoE-F algorithm -- deployable as a plug-and-play filtering harness, (II) theoretical optimality guarantees of the proposed filtering-based gating algorithm, and (III) empirical evaluation and ablative results using state of the art foundational and MoE LLMs on a real-world Financial Market Movement task where MoE-F attains a remarkable 17% absolute and 48.5% relative F1 measure improvement over the next best performing individual LLM expert.
Reality Only Happens Once: Single-Path Generalization Bounds for Transformers
May 26, 2024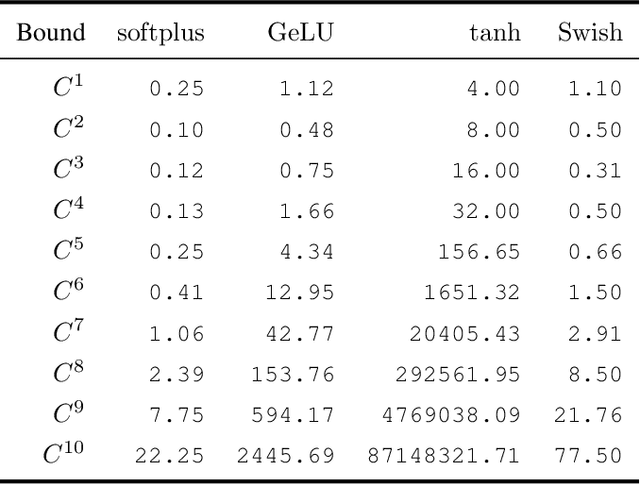
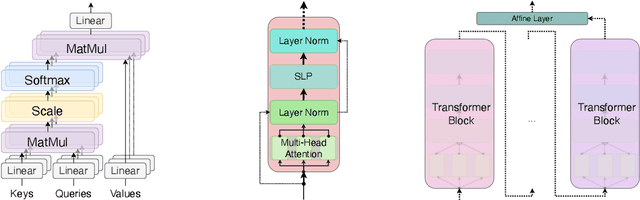

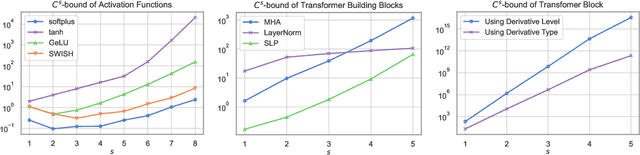
One of the inherent challenges in deploying transformers on time series is that \emph{reality only happens once}; namely, one typically only has access to a single trajectory of the data-generating process comprised of non-i.i.d. observations. We derive non-asymptotic statistical guarantees in this setting through bounds on the \textit{generalization} of a transformer network at a future-time $t$, given that it has been trained using $N\le t$ observations from a single perturbed trajectory of a Markov process. Under the assumption that the Markov process satisfies a log-Sobolev inequality, we obtain a generalization bound which effectively converges at the rate of ${O}(1/\sqrt{N})$. Our bound depends explicitly on the activation function ($\operatorname{Swish}$, $\operatorname{GeLU}$, or $\tanh$ are considered), the number of self-attention heads, depth, width, and norm-bounds defining the transformer architecture. Our bound consists of three components: (I) The first quantifies the gap between the stationary distribution of the data-generating Markov process and its distribution at time $t$, this term converges exponentially to $0$. (II) The next term encodes the complexity of the transformer model and, given enough time, eventually converges to $0$ at the rate ${O}(\log(N)^r/\sqrt{N})$ for any $r>0$. (III) The third term guarantees that the bound holds with probability at least $1$-$\delta$, and converges at a rate of ${O}(\sqrt{\log(1/\delta)}/\sqrt{N})$.
NIFTY Financial News Headlines Dataset
May 16, 2024We introduce and make publicly available the NIFTY Financial News Headlines dataset, designed to facilitate and advance research in financial market forecasting using large language models (LLMs). This dataset comprises two distinct versions tailored for different modeling approaches: (i) NIFTY-LM, which targets supervised fine-tuning (SFT) of LLMs with an auto-regressive, causal language-modeling objective, and (ii) NIFTY-RL, formatted specifically for alignment methods (like reinforcement learning from human feedback (RLHF)) to align LLMs via rejection sampling and reward modeling. Each dataset version provides curated, high-quality data incorporating comprehensive metadata, market indices, and deduplicated financial news headlines systematically filtered and ranked to suit modern LLM frameworks. We also include experiments demonstrating some applications of the dataset in tasks like stock price movement and the role of LLM embeddings in information acquisition/richness. The NIFTY dataset along with utilities (like truncating prompt's context length systematically) are available on Hugging Face at https://huggingface.co/datasets/raeidsaqur/NIFTY.
L(u)PIN: LLM-based Political Ideology Nowcasting
May 12, 2024The quantitative analysis of political ideological positions is a difficult task. In the past, various literature focused on parliamentary voting data of politicians, party manifestos and parliamentary speech to estimate political disagreement and polarization in various political systems. However previous methods of quantitative political analysis suffered from a common challenge which was the amount of data available for analysis. Also previous methods frequently focused on a more general analysis of politics such as overall polarization of the parliament or party-wide political ideological positions. In this paper, we present a method to analyze ideological positions of individual parliamentary representatives by leveraging the latent knowledge of LLMs. The method allows us to evaluate the stance of politicians on an axis of our choice allowing us to flexibly measure the stance of politicians in regards to a topic/controversy of our choice. We achieve this by using a fine-tuned BERT classifier to extract the opinion-based sentences from the speeches of representatives and projecting the average BERT embeddings for each representative on a pair of reference seeds. These reference seeds are either manually chosen representatives known to have opposing views on a particular topic or they are generated sentences which where created using the GPT-4 model of OpenAI. We created the sentences by prompting the GPT-4 model to generate a speech that would come from a politician defending a particular position.
Large Language Models are Fixated by Red Herrings: Exploring Creative Problem Solving and Einstellung Effect using the Only Connect Wall Dataset
Jun 19, 2023



The quest for human imitative AI has been an enduring topic in AI research since its inception. The technical evolution and emerging capabilities of the latest cohort of large language models (LLMs) have reinvigorated the subject beyond academia to the cultural zeitgeist. While recent NLP evaluation benchmark tasks test some aspects of human-imitative behaviour (e.g., BIG-bench's 'human-like behavior' tasks), few, if not none, examine creative problem solving abilities. Creative problem solving in humans is a well-studied topic in cognitive neuroscience with standardized tests that predominantly use the ability to associate (heterogeneous) connections among clue words as a metric for creativity. Exposure to misleading stimuli - distractors dubbed red herrings - impede human performance in such tasks via the fixation effect and Einstellung paradigm. In cognitive neuroscience studies, such fixations are experimentally induced by pre-exposing participants to orthographically similar incorrect words to subsequent word-fragments or clues. The popular British quiz show Only Connect's Connecting Wall segment essentially mimics Mednick's Remote Associates Test (RAT) formulation with built-in, deliberate red herrings, which makes it an ideal proxy dataset to explore and study fixation effect and Einstellung paradigm from cognitive neuroscience in LLMs. In addition to presenting the novel Only Connect Wall (OCW) dataset, we also report results from our evaluation of selected pre-trained language models and LLMs (including OpenAI's GPT series) on creative problem solving tasks like grouping clue words by heterogeneous connections, and identifying correct open knowledge domain connections in respective groups. The code and link to the dataset are available at https://github.com/TaatiTeam/OCW.
Reward Learning using Structural Motifs in Inverse Reinforcement Learning
Sep 25, 2022



The Inverse Reinforcement Learning (\textit{IRL}) problem has seen rapid evolution in the past few years, with important applications in domains like robotics, cognition, and health. In this work, we explore the inefficacy of current IRL methods in learning an agent's reward function from expert trajectories depicting long-horizon, complex sequential tasks. We hypothesize that imbuing IRL models with structural motifs capturing underlying tasks can enable and enhance their performance. Subsequently, we propose a novel IRL method, SMIRL, that first learns the (approximate) structure of a task as a finite-state-automaton (FSA), then uses the structural motif to solve the IRL problem. We test our model on both discrete grid world and high-dimensional continuous domain environments. We empirically show that our proposed approach successfully learns all four complex tasks, where two foundational IRL baselines fail. Our model also outperforms the baselines in sample efficiency on a simpler toy task. We further show promising test results in a modified continuous domain on tasks with compositional reward functions.