 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWhat Teaches Robots to Walk, Teaches Them to Trade too -- Regime Adaptive Execution using Informed Data and LLMs
Paper and Code
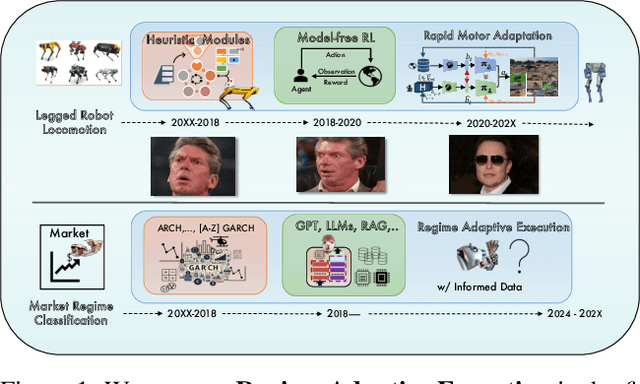
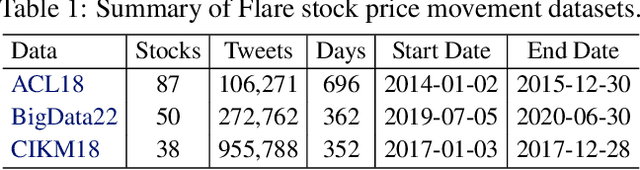
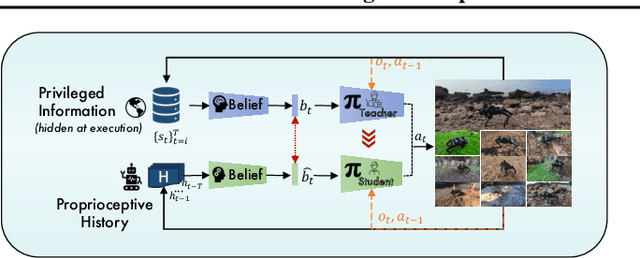
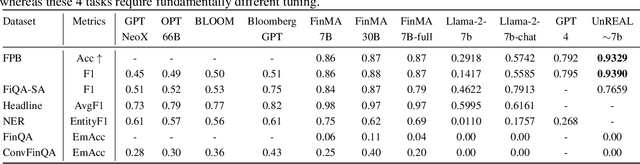
Machine learning techniques applied to the problem of financial market forecasting struggle with dynamic regime switching, or underlying correlation and covariance shifts in true (hidden) market variables. Drawing inspiration from the success of reinforcement learning in robotics, particularly in agile locomotion adaptation of quadruped robots to unseen terrains, we introduce an innovative approach that leverages world knowledge of pretrained LLMs (aka. 'privileged information' in robotics) and dynamically adapts them using intrinsic, natural market rewards using LLM alignment technique we dub as "Reinforcement Learning from Market Feedback" (**RLMF**). Strong empirical results demonstrate the efficacy of our method in adapting to regime shifts in financial markets, a challenge that has long plagued predictive models in this domain. The proposed algorithmic framework outperforms best-performing SOTA LLM models on the existing (FLARE) benchmark stock-movement (SM) tasks by more than 15\% improved accuracy. On the recently proposed NIFTY SM task, our adaptive policy outperforms the SOTA best performing trillion parameter models like GPT-4. The paper details the dual-phase, teacher-student architecture and implementation of our model, the empirical results obtained, and an analysis of the role of language embeddings in terms of Information Gain.