 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Feedback to Checklists: Grounded Evaluation of AI-Generated Clinical Notes
Jul 23, 2025



AI-generated clinical notes are increasingly used in healthcare, but evaluating their quality remains a challenge due to high subjectivity and limited scalability of expert review. Existing automated metrics often fail to align with real-world physician preferences. To address this, we propose a pipeline that systematically distills real user feedback into structured checklists for note evaluation. These checklists are designed to be interpretable, grounded in human feedback, and enforceable by LLM-based evaluators. Using deidentified data from over 21,000 clinical encounters, prepared in accordance with the HIPAA safe harbor standard, from a deployed AI medical scribe system, we show that our feedback-derived checklist outperforms baseline approaches in our offline evaluations in coverage, diversity, and predictive power for human ratings. Extensive experiments confirm the checklist's robustness to quality-degrading perturbations, significant alignment with clinician preferences, and practical value as an evaluation methodology. In offline research settings, the checklist can help identify notes likely to fall below our chosen quality thresholds.
TOPICAL: TOPIC Pages AutomagicaLly
May 03, 2024



Topic pages aggregate useful information about an entity or concept into a single succinct and accessible article. Automated creation of topic pages would enable their rapid curation as information resources, providing an alternative to traditional web search. While most prior work has focused on generating topic pages about biographical entities, in this work, we develop a completely automated process to generate high-quality topic pages for scientific entities, with a focus on biomedical concepts. We release TOPICAL, a web app and associated open-source code, comprising a model pipeline combining retrieval, clustering, and prompting, that makes it easy for anyone to generate topic pages for a wide variety of biomedical entities on demand. In a human evaluation of 150 diverse topic pages generated using TOPICAL, we find that the vast majority were considered relevant, accurate, and coherent, with correct supporting citations. We make all code publicly available and host a free-to-use web app at: https://s2-topical.apps.allenai.org
Large Language Models are Fixated by Red Herrings: Exploring Creative Problem Solving and Einstellung Effect using the Only Connect Wall Dataset
Jun 19, 2023



The quest for human imitative AI has been an enduring topic in AI research since its inception. The technical evolution and emerging capabilities of the latest cohort of large language models (LLMs) have reinvigorated the subject beyond academia to the cultural zeitgeist. While recent NLP evaluation benchmark tasks test some aspects of human-imitative behaviour (e.g., BIG-bench's 'human-like behavior' tasks), few, if not none, examine creative problem solving abilities. Creative problem solving in humans is a well-studied topic in cognitive neuroscience with standardized tests that predominantly use the ability to associate (heterogeneous) connections among clue words as a metric for creativity. Exposure to misleading stimuli - distractors dubbed red herrings - impede human performance in such tasks via the fixation effect and Einstellung paradigm. In cognitive neuroscience studies, such fixations are experimentally induced by pre-exposing participants to orthographically similar incorrect words to subsequent word-fragments or clues. The popular British quiz show Only Connect's Connecting Wall segment essentially mimics Mednick's Remote Associates Test (RAT) formulation with built-in, deliberate red herrings, which makes it an ideal proxy dataset to explore and study fixation effect and Einstellung paradigm from cognitive neuroscience in LLMs. In addition to presenting the novel Only Connect Wall (OCW) dataset, we also report results from our evaluation of selected pre-trained language models and LLMs (including OpenAI's GPT series) on creative problem solving tasks like grouping clue words by heterogeneous connections, and identifying correct open knowledge domain connections in respective groups. The code and link to the dataset are available at https://github.com/TaatiTeam/OCW.
Clinical Note Generation from Doctor-Patient Conversations using Large Language Models: Insights from MEDIQA-Chat
May 03, 2023



This paper describes our submission to the MEDIQA-Chat 2023 shared task for automatic clinical note generation from doctor-patient conversations. We report results for two approaches: the first fine-tunes a pre-trained language model (PLM) on the shared task data, and the second uses few-shot in-context learning (ICL) with a large language model (LLM). Both achieve high performance as measured by automatic metrics (e.g. ROUGE, BERTScore) and ranked second and first, respectively, of all submissions to the shared task. Expert human scrutiny indicates that notes generated via the ICL-based approach with GPT-4 are preferred about as often as human-written notes, making it a promising path toward automated note generation from doctor-patient conversations.
Exploring the Challenges of Open Domain Multi-Document Summarization
Dec 20, 2022Multi-document summarization (MDS) has traditionally been studied assuming a set of ground-truth topic-related input documents is provided. In practice, the input document set is unlikely to be available a priori and would need to be retrieved based on an information need, a setting we call open-domain MDS. We experiment with current state-of-the-art retrieval and summarization models on several popular MDS datasets extended to the open-domain setting. We find that existing summarizers suffer large reductions in performance when applied as-is to this more realistic task, though training summarizers with retrieved inputs can reduce their sensitivity retrieval errors. To further probe these findings, we conduct perturbation experiments on summarizer inputs to study the impact of different types of document retrieval errors. Based on our results, we provide practical guidelines to help facilitate a shift to open-domain MDS. We release our code and experimental results alongside all data or model artifacts created during our investigation.
BLOOM: A 176B-Parameter Open-Access Multilingual Language Model
Nov 09, 2022Large language models (LLMs) have been shown to be able to perform new tasks based on a few demonstrations or natural language instructions. While these capabilities have led to widespread adoption, most LLMs are developed by resource-rich organizations and are frequently kept from the public. As a step towards democratizing this powerful technology, we present BLOOM, a 176B-parameter open-access language model designed and built thanks to a collaboration of hundreds of researchers. BLOOM is a decoder-only Transformer language model that was trained on the ROOTS corpus, a dataset comprising hundreds of sources in 46 natural and 13 programming languages (59 in total). We find that BLOOM achieves competitive performance on a wide variety of benchmarks, with stronger results after undergoing multitask prompted finetuning. To facilitate future research and applications using LLMs, we publicly release our models and code under the Responsible AI License.
A sequence-to-sequence approach for document-level relation extraction
Apr 10, 2022
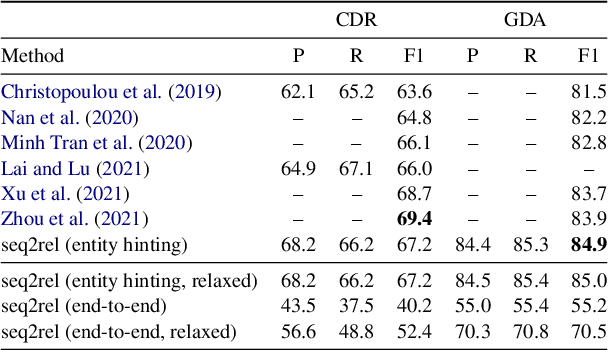
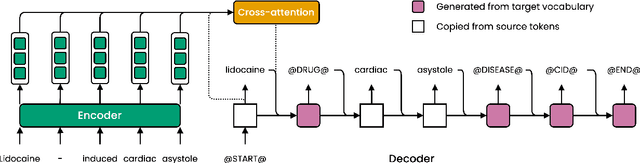
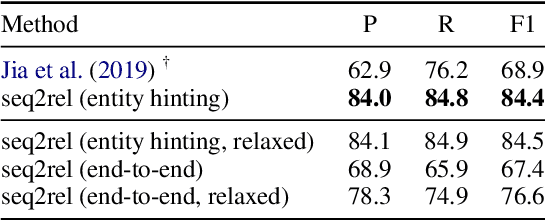
Motivated by the fact that many relations cross the sentence boundary, there has been increasing interest in document-level relation extraction (DocRE). DocRE requires integrating information within and across sentences, capturing complex interactions between mentions of entities. Most existing methods are pipeline-based, requiring entities as input. However, jointly learning to extract entities and relations can improve performance and be more efficient due to shared parameters and training steps. In this paper, we develop a sequence-to-sequence approach, seq2rel, that can learn the subtasks of DocRE (entity extraction, coreference resolution and relation extraction) end-to-end, replacing a pipeline of task-specific components. Using a simple strategy we call entity hinting, we compare our approach to existing pipeline-based methods on several popular biomedical datasets, in some cases exceeding their performance. We also report the first end-to-end results on these datasets for future comparison. Finally, we demonstrate that, under our model, an end-to-end approach outperforms a pipeline-based approach. Our code, data and trained models are available at {\url{https://github.com/johngiorgi/seq2rel}}. An online demo is available at {\url{https://share.streamlit.io/johngiorgi/seq2rel/main/demo.py}}.
End-to-end Named Entity Recognition and Relation Extraction using Pre-trained Language Models
Dec 20, 2019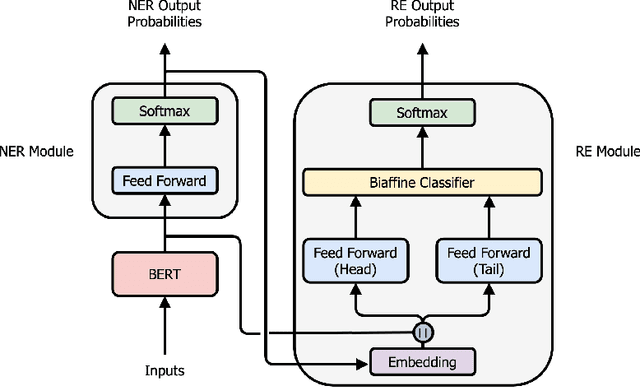
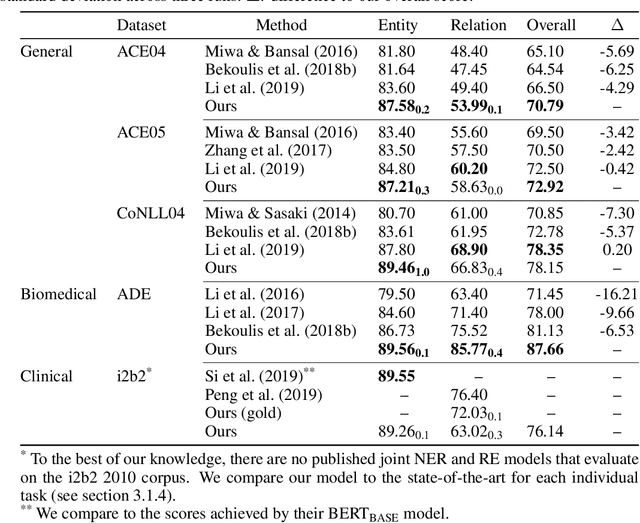
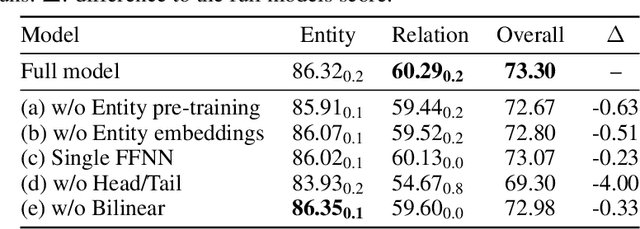
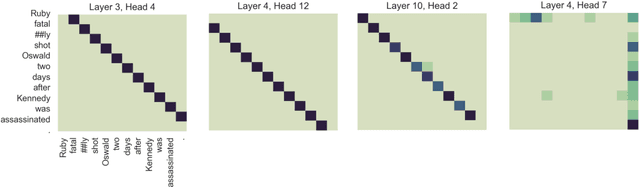
Named entity recognition (NER) and relation extraction (RE) are two important tasks in information extraction and retrieval (IE \& IR). Recent work has demonstrated that it is beneficial to learn these tasks jointly, which avoids the propagation of error inherent in pipeline-based systems and improves performance. However, state-of-the-art joint models typically rely on external natural language processing (NLP) tools, such as dependency parsers, limiting their usefulness to domains (e.g. news) where those tools perform well. The few neural, end-to-end models that have been proposed are trained almost completely from scratch. In this paper, we propose a neural, end-to-end model for jointly extracting entities and their relations which does not rely on external NLP tools and which integrates a large, pre-trained language model. Because the bulk of our model's parameters are pre-trained and we eschew recurrence for self-attention, our model is fast to train. On 5 datasets across 3 domains, our model matches or exceeds state-of-the-art performance, sometimes by a large margin.