 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParameter-Efficient Neural Question Answering Models via Graph-Enriched Document Representations
Jun 01, 2021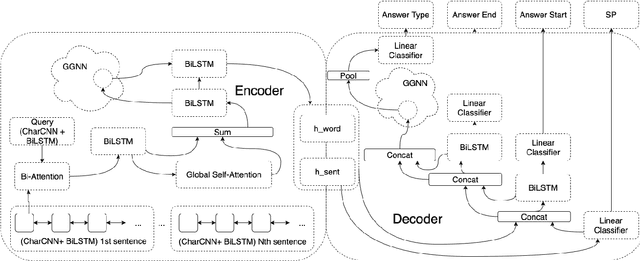
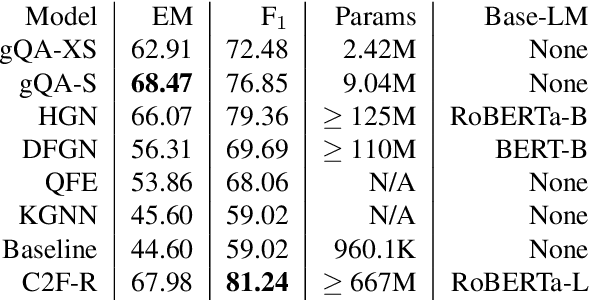
As the computational footprint of modern NLP systems grows, it becomes increasingly important to arrive at more efficient models. We show that by employing graph convolutional document representation, we can arrive at a question answering system that performs comparably to, and in some cases exceeds the SOTA solutions, while using less than 5\% of their resources in terms of trainable parameters. As it currently stands, a major issue in applying GCNs to NLP is document representation. In this paper, we show that a GCN enriched document representation greatly improves the results seen in HotPotQA, even when using a trivial topology. Our model (gQA), performs admirably when compared to the current SOTA, and requires little to no preprocessing. In Shao et al. 2020, the authors suggest that graph networks are not necessary for good performance in multi-hop QA. In this paper, we suggest that large language models are not necessary for good performance by showing a na\"{i}ve implementation of a GCN performs comparably to SoTA models based on pretrained language models.
End-to-end Named Entity Recognition and Relation Extraction using Pre-trained Language Models
Dec 20, 2019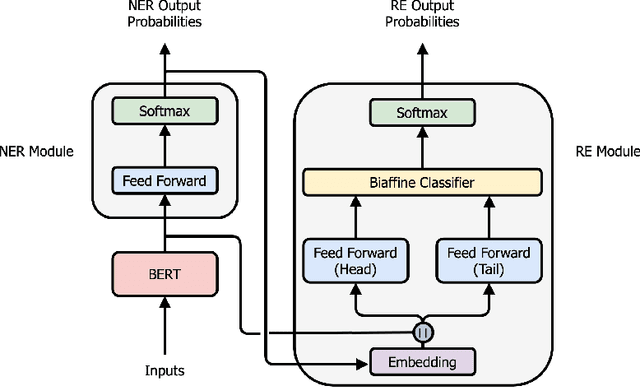
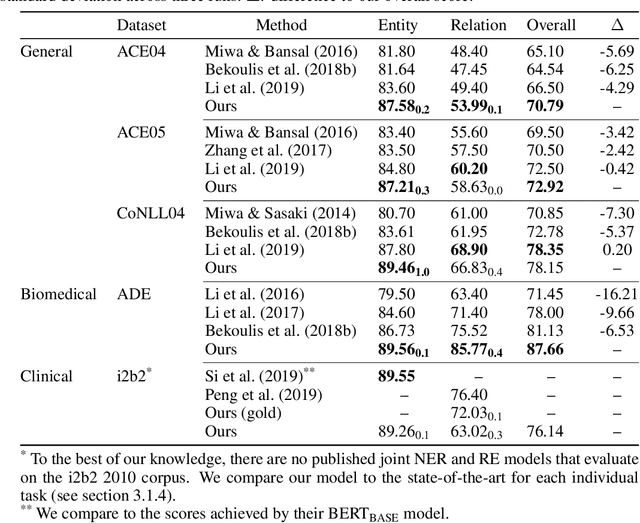
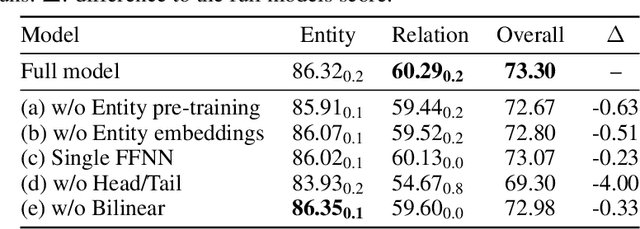
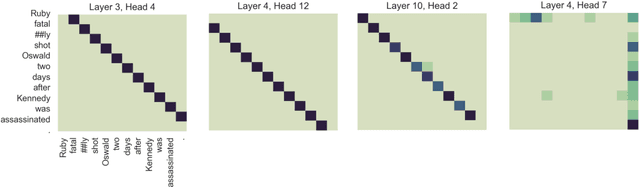
Named entity recognition (NER) and relation extraction (RE) are two important tasks in information extraction and retrieval (IE \& IR). Recent work has demonstrated that it is beneficial to learn these tasks jointly, which avoids the propagation of error inherent in pipeline-based systems and improves performance. However, state-of-the-art joint models typically rely on external natural language processing (NLP) tools, such as dependency parsers, limiting their usefulness to domains (e.g. news) where those tools perform well. The few neural, end-to-end models that have been proposed are trained almost completely from scratch. In this paper, we propose a neural, end-to-end model for jointly extracting entities and their relations which does not rely on external NLP tools and which integrates a large, pre-trained language model. Because the bulk of our model's parameters are pre-trained and we eschew recurrence for self-attention, our model is fast to train. On 5 datasets across 3 domains, our model matches or exceeds state-of-the-art performance, sometimes by a large margin.