 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo GPT Language Models Suffer From Split Personality Disorder? The Advent Of Substrate-Free Psychometrics
Aug 15, 2024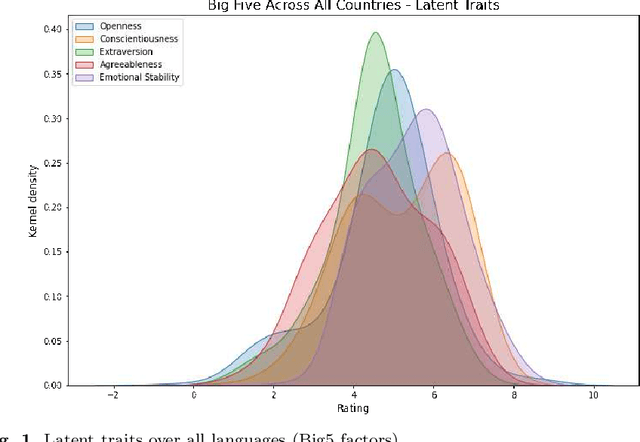

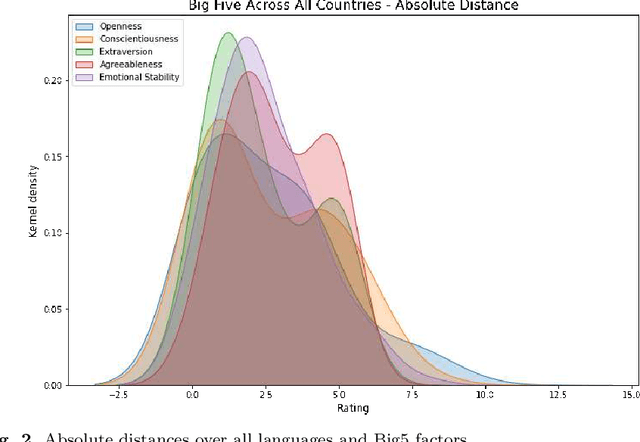

Previous research on emergence in large language models shows these display apparent human-like abilities and psychological latent traits. However, results are partly contradicting in expression and magnitude of these latent traits, yet agree on the worrisome tendencies to score high on the Dark Triad of narcissism, psychopathy, and Machiavellianism, which, together with a track record of derailments, demands more rigorous research on safety of these models. We provided a state of the art language model with the same personality questionnaire in nine languages, and performed Bayesian analysis of Gaussian Mixture Model, finding evidence for a deeper-rooted issue. Our results suggest both interlingual and intralingual instabilities, which indicate that current language models do not develop a consistent core personality. This can lead to unsafe behaviour of artificial intelligence systems that are based on these foundation models, and are increasingly integrated in human life. We subsequently discuss the shortcomings of modern psychometrics, abstract it, and provide a framework for its species-neutral, substrate-free formulation.
Safetywashing: Do AI Safety Benchmarks Actually Measure Safety Progress?
Jul 31, 2024As artificial intelligence systems grow more powerful, there has been increasing interest in "AI safety" research to address emerging and future risks. However, the field of AI safety remains poorly defined and inconsistently measured, leading to confusion about how researchers can contribute. This lack of clarity is compounded by the unclear relationship between AI safety benchmarks and upstream general capabilities (e.g., general knowledge and reasoning). To address these issues, we conduct a comprehensive meta-analysis of AI safety benchmarks, empirically analyzing their correlation with general capabilities across dozens of models and providing a survey of existing directions in AI safety. Our findings reveal that many safety benchmarks highly correlate with upstream model capabilities, potentially enabling "safetywashing" -- where capability improvements are misrepresented as safety advancements. Based on these findings, we propose an empirical foundation for developing more meaningful safety metrics and define AI safety in a machine learning research context as a set of clearly delineated research goals that are empirically separable from generic capabilities advancements. In doing so, we aim to provide a more rigorous framework for AI safety research, advancing the science of safety evaluations and clarifying the path towards measurable progress.
Hidden Holes: topological aspects of language models
Jun 09, 2024



We explore the topology of representation manifolds arising in autoregressive neural language models trained on raw text data. In order to study their properties, we introduce tools from computational algebraic topology, which we use as a basis for a measure of topological complexity, that we call perforation. Using this measure, we study the evolution of topological structure in GPT based large language models across depth and time during training. We then compare these to gated recurrent models, and show that the latter exhibit more topological complexity, with a distinct pattern of changes common to all natural languages but absent from synthetically generated data. The paper presents a detailed analysis of the representation manifolds derived by these models based on studying the shapes of vector clouds induced by them as they are conditioned on sentences from corpora of natural language text. The methods developed in this paper are novel in the field and based on mathematical apparatus that might be unfamiliar to the target audience. To help with that we introduce the minimum necessary theory, and provide additional visualizations in the appendices. The main contribution of the paper is a striking observation about the topological structure of the transformer as compared to LSTM based neural architectures. It suggests that further research into mathematical properties of these neural networks is necessary to understand the operation of large transformer language models. We hope this work inspires further explorations in this direction within the NLP community.
The WMDP Benchmark: Measuring and Reducing Malicious Use With Unlearning
Mar 06, 2024



The White House Executive Order on Artificial Intelligence highlights the risks of large language models (LLMs) empowering malicious actors in developing biological, cyber, and chemical weapons. To measure these risks of malicious use, government institutions and major AI labs are developing evaluations for hazardous capabilities in LLMs. However, current evaluations are private, preventing further research into mitigating risk. Furthermore, they focus on only a few, highly specific pathways for malicious use. To fill these gaps, we publicly release the Weapons of Mass Destruction Proxy (WMDP) benchmark, a dataset of 4,157 multiple-choice questions that serve as a proxy measurement of hazardous knowledge in biosecurity, cybersecurity, and chemical security. WMDP was developed by a consortium of academics and technical consultants, and was stringently filtered to eliminate sensitive information prior to public release. WMDP serves two roles: first, as an evaluation for hazardous knowledge in LLMs, and second, as a benchmark for unlearning methods to remove such hazardous knowledge. To guide progress on unlearning, we develop CUT, a state-of-the-art unlearning method based on controlling model representations. CUT reduces model performance on WMDP while maintaining general capabilities in areas such as biology and computer science, suggesting that unlearning may be a concrete path towards reducing malicious use from LLMs. We release our benchmark and code publicly at https://wmdp.ai
Do Large GPT Models Discover Moral Dimensions in Language Representations? A Topological Study Of Sentence Embeddings
Sep 17, 2023



As Large Language Models are deployed within Artificial Intelligence systems, that are increasingly integrated with human society, it becomes more important than ever to study their internal structures. Higher level abilities of LLMs such as GPT-3.5 emerge in large part due to informative language representations they induce from raw text data during pre-training on trillions of words. These embeddings exist in vector spaces of several thousand dimensions, and their processing involves mapping between multiple vector spaces, with total number of parameters on the order of trillions. Furthermore, these language representations are induced by gradient optimization, resulting in a black box system that is hard to interpret. In this paper, we take a look at the topological structure of neuronal activity in the "brain" of Chat-GPT's foundation language model, and analyze it with respect to a metric representing the notion of fairness. We develop a novel approach to visualize GPT's moral dimensions. We first compute a fairness metric, inspired by social psychology literature, to identify factors that typically influence fairness assessments in humans, such as legitimacy, need, and responsibility. Subsequently, we summarize the manifold's shape using a lower-dimensional simplicial complex, whose topology is derived from this metric. We color it with a heat map associated with this fairness metric, producing human-readable visualizations of the high-dimensional sentence manifold. Our results show that sentence embeddings based on GPT-3.5 can be decomposed into two submanifolds corresponding to fair and unfair moral judgments. This indicates that GPT-based language models develop a moral dimension within their representation spaces and induce an understanding of fairness during their training process.
Personality Traits in Large Language Models
Jul 01, 2023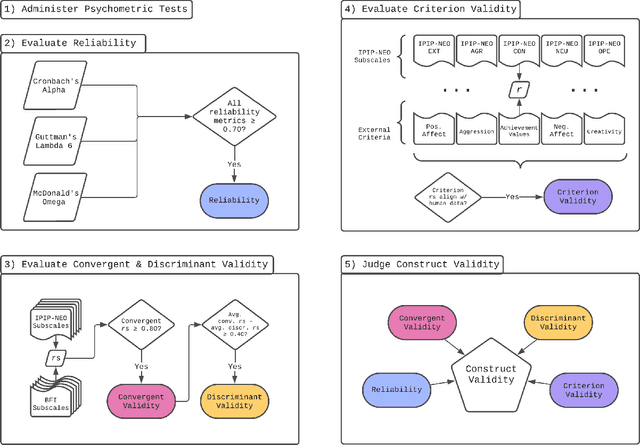

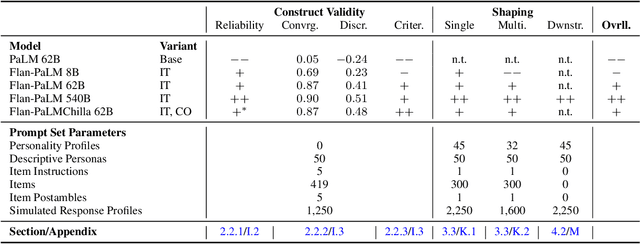
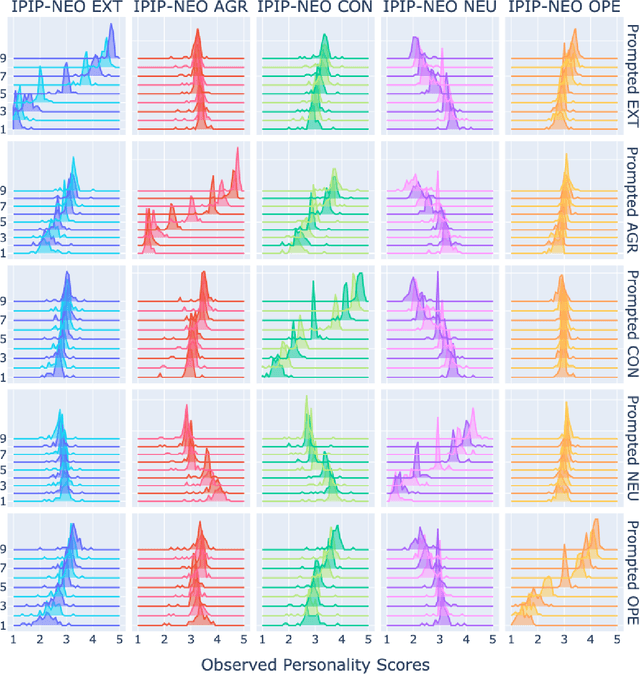
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.
Parameter-Efficient Neural Question Answering Models via Graph-Enriched Document Representations
Jun 01, 2021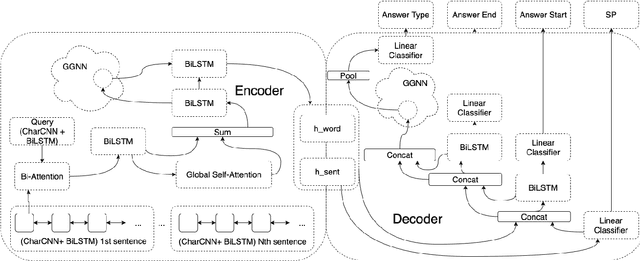
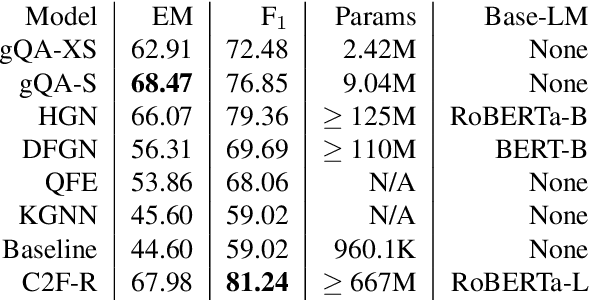
As the computational footprint of modern NLP systems grows, it becomes increasingly important to arrive at more efficient models. We show that by employing graph convolutional document representation, we can arrive at a question answering system that performs comparably to, and in some cases exceeds the SOTA solutions, while using less than 5\% of their resources in terms of trainable parameters. As it currently stands, a major issue in applying GCNs to NLP is document representation. In this paper, we show that a GCN enriched document representation greatly improves the results seen in HotPotQA, even when using a trivial topology. Our model (gQA), performs admirably when compared to the current SOTA, and requires little to no preprocessing. In Shao et al. 2020, the authors suggest that graph networks are not necessary for good performance in multi-hop QA. In this paper, we suggest that large language models are not necessary for good performance by showing a na\"{i}ve implementation of a GCN performs comparably to SoTA models based on pretrained language models.