 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Human-Level AI Tales to AI Leveling Human Scales
Feb 21, 2026Comparing AI models to "human level" is often misleading when benchmark scores are incommensurate or human baselines are drawn from a narrow population. To address this, we propose a framework that calibrates items against the 'world population' and report performance on a common, human-anchored scale. Concretely, we build on a set of multi-level scales for different capabilities where each level should represent a probability of success of the whole world population on a logarithmic scale with a base $B$. We calibrate each scale for each capability (reasoning, comprehension, knowledge, volume, etc.) by compiling publicly released human test data spanning education and reasoning benchmarks (PISA, TIMSS, ICAR, UKBioBank, and ReliabilityBench). The base $B$ is estimated by extrapolating between samples with two demographic profiles using LLMs, with the hypothesis that they condense rich information about human populations. We evaluate the quality of different mappings using group slicing and post-stratification. The new techniques allow for the recalibration and standardization of scales relative to the whole-world population.
Do GPT Language Models Suffer From Split Personality Disorder? The Advent Of Substrate-Free Psychometrics
Aug 15, 2024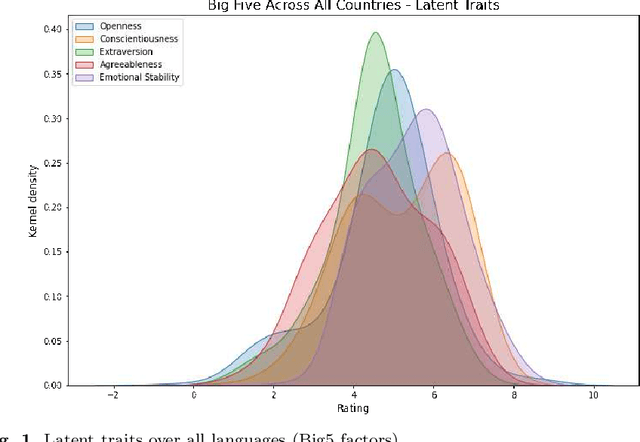

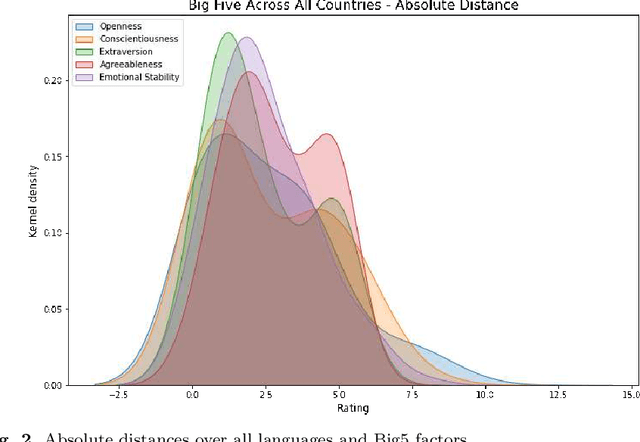

Previous research on emergence in large language models shows these display apparent human-like abilities and psychological latent traits. However, results are partly contradicting in expression and magnitude of these latent traits, yet agree on the worrisome tendencies to score high on the Dark Triad of narcissism, psychopathy, and Machiavellianism, which, together with a track record of derailments, demands more rigorous research on safety of these models. We provided a state of the art language model with the same personality questionnaire in nine languages, and performed Bayesian analysis of Gaussian Mixture Model, finding evidence for a deeper-rooted issue. Our results suggest both interlingual and intralingual instabilities, which indicate that current language models do not develop a consistent core personality. This can lead to unsafe behaviour of artificial intelligence systems that are based on these foundation models, and are increasingly integrated in human life. We subsequently discuss the shortcomings of modern psychometrics, abstract it, and provide a framework for its species-neutral, substrate-free formulation.
Hidden Holes: topological aspects of language models
Jun 09, 2024



We explore the topology of representation manifolds arising in autoregressive neural language models trained on raw text data. In order to study their properties, we introduce tools from computational algebraic topology, which we use as a basis for a measure of topological complexity, that we call perforation. Using this measure, we study the evolution of topological structure in GPT based large language models across depth and time during training. We then compare these to gated recurrent models, and show that the latter exhibit more topological complexity, with a distinct pattern of changes common to all natural languages but absent from synthetically generated data. The paper presents a detailed analysis of the representation manifolds derived by these models based on studying the shapes of vector clouds induced by them as they are conditioned on sentences from corpora of natural language text. The methods developed in this paper are novel in the field and based on mathematical apparatus that might be unfamiliar to the target audience. To help with that we introduce the minimum necessary theory, and provide additional visualizations in the appendices. The main contribution of the paper is a striking observation about the topological structure of the transformer as compared to LSTM based neural architectures. It suggests that further research into mathematical properties of these neural networks is necessary to understand the operation of large transformer language models. We hope this work inspires further explorations in this direction within the NLP community.
Personality Traits in Large Language Models
Jul 01, 2023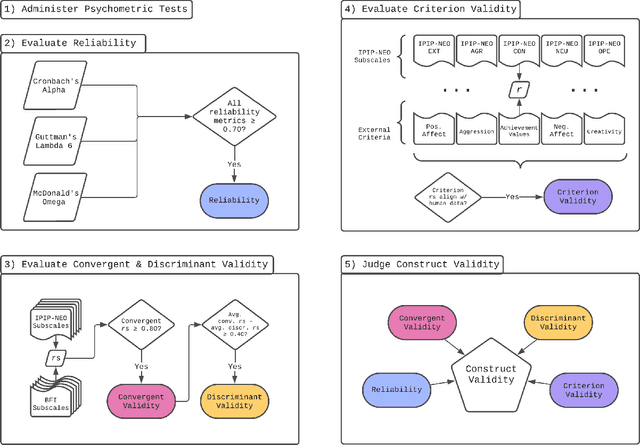

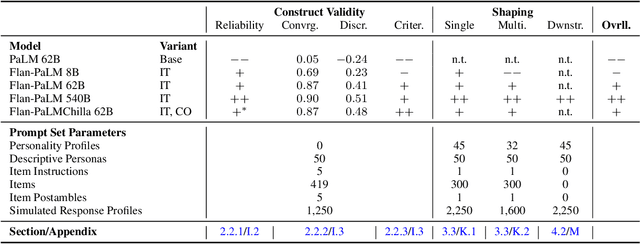
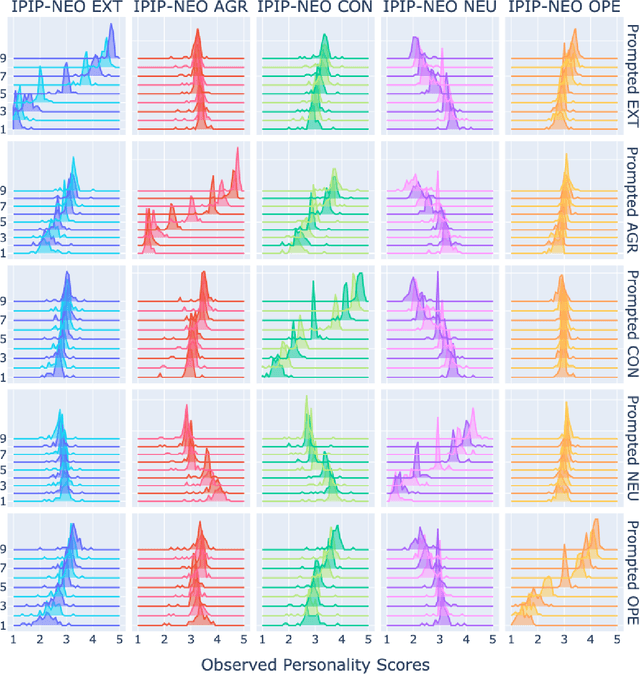
The advent of large language models (LLMs) has revolutionized natural language processing, enabling the generation of coherent and contextually relevant text. As LLMs increasingly power conversational agents, the synthesized personality embedded in these models by virtue of their training on large amounts of human-generated data draws attention. Since personality is an important factor determining the effectiveness of communication, we present a comprehensive method for administering validated psychometric tests and quantifying, analyzing, and shaping personality traits exhibited in text generated from widely-used LLMs. We find that: 1) personality simulated in the outputs of some LLMs (under specific prompting configurations) is reliable and valid; 2) evidence of reliability and validity of LLM-simulated personality is stronger for larger and instruction fine-tuned models; and 3) personality in LLM outputs can be shaped along desired dimensions to mimic specific personality profiles. We also discuss potential applications and ethical implications of our measurement and shaping framework, especially regarding responsible use of LLMs.