 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUsing Spectral Submanifolds for Nonlinear Periodic Control
Sep 14, 2022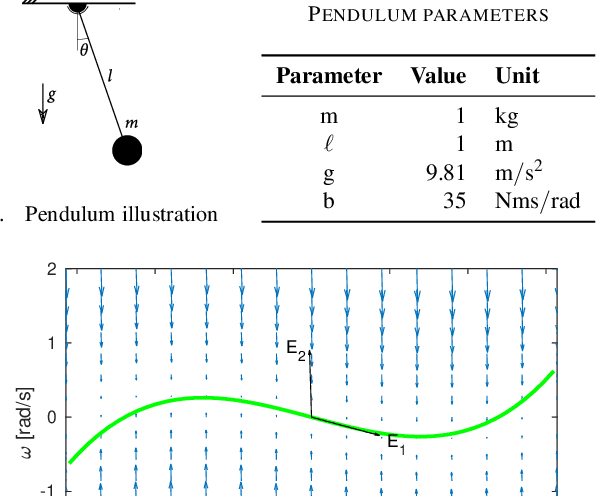
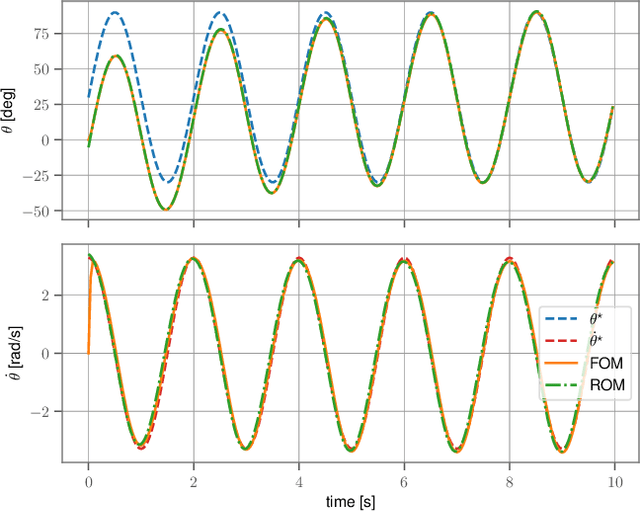
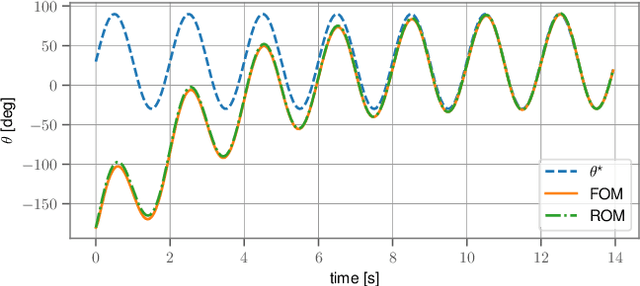
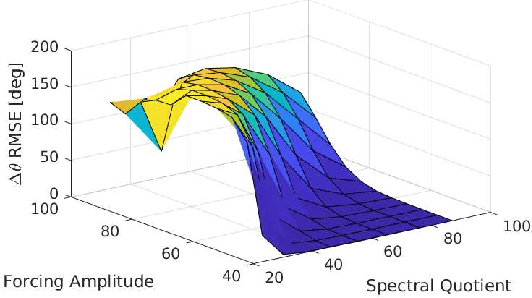
Very high dimensional nonlinear systems arise in many engineering problems due to semi-discretization of the governing partial differential equations, e.g. through finite element methods. The complexity of these systems present computational challenges for direct application to automatic control. While model reduction has seen ubiquitous applications in control, the use of nonlinear model reduction methods in this setting remains difficult. The problem lies in preserving the structure of the nonlinear dynamics in the reduced order model for high-fidelity control. In this work, we leverage recent advances in Spectral Submanifold (SSM) theory to enable model reduction under well-defined assumptions for the purpose of efficiently synthesizing feedback controllers.
An Experimental Evaluation of Transformer-based Language Models in the Biomedical Domain
Dec 31, 2020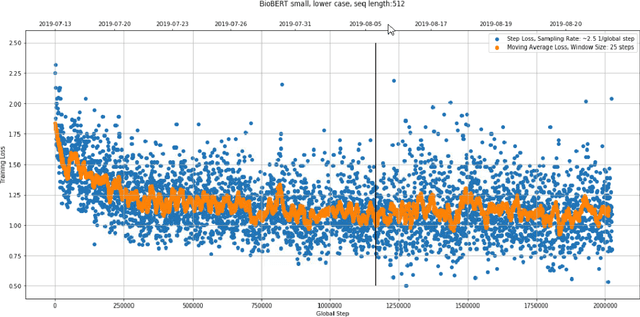
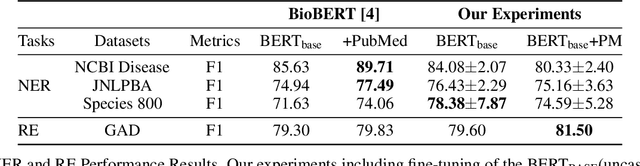
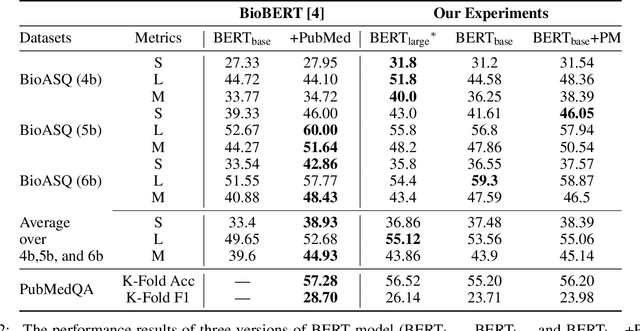

With the growing amount of text in health data, there have been rapid advances in large pre-trained models that can be applied to a wide variety of biomedical tasks with minimal task-specific modifications. Emphasizing the cost of these models, which renders technical replication challenging, this paper summarizes experiments conducted in replicating BioBERT and further pre-training and careful fine-tuning in the biomedical domain. We also investigate the effectiveness of domain-specific and domain-agnostic pre-trained models across downstream biomedical NLP tasks. Our finding confirms that pre-trained models can be impactful in some downstream NLP tasks (QA and NER) in the biomedical domain; however, this improvement may not justify the high cost of domain-specific pre-training.
Multi Sense Embeddings from Topic Models
Sep 17, 2019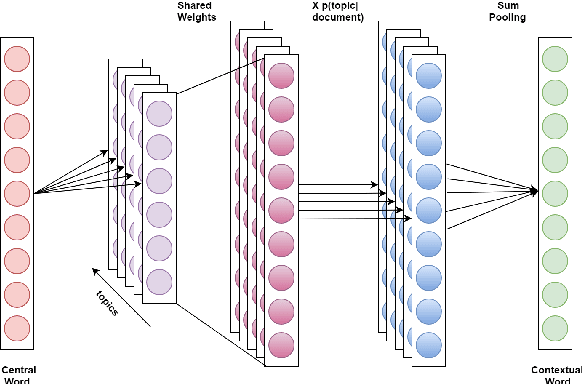
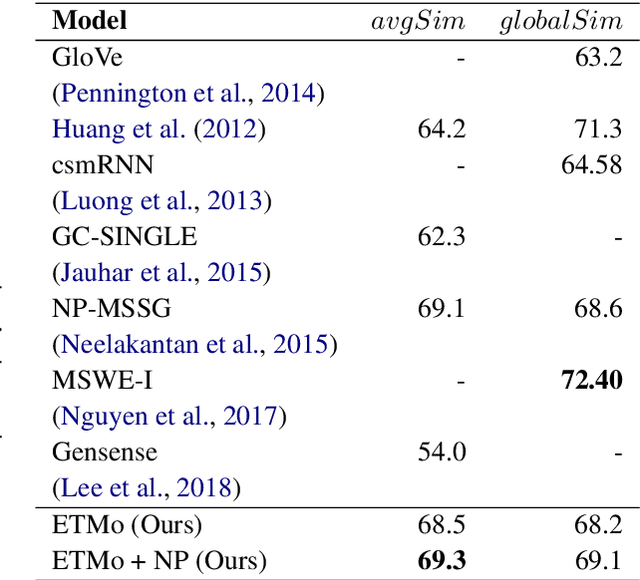
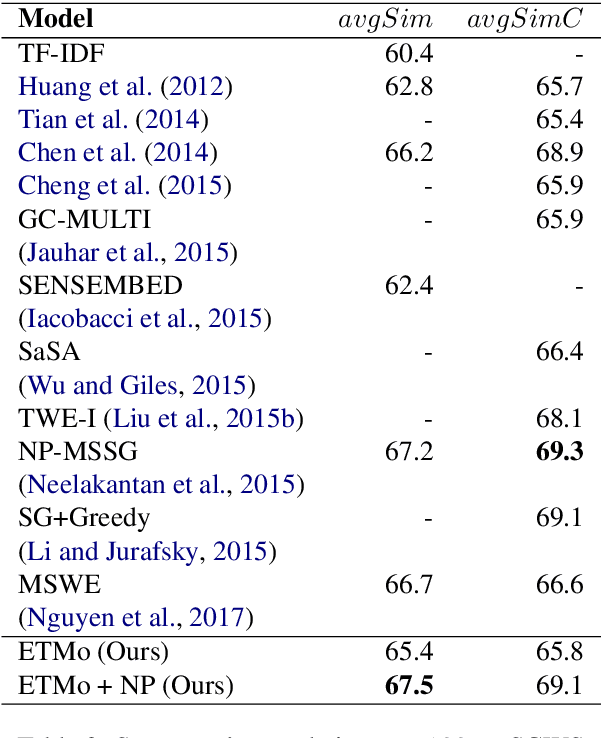

Distributed word embeddings have yielded state-of-the-art performance in many NLP tasks, mainly due to their success in capturing useful semantic information. These representations assign only a single vector to each word whereas a large number of words are polysemous (i.e., have multiple meanings). In this work, we approach this critical problem in lexical semantics, namely that of representing various senses of polysemous words in vector spaces. We propose a topic modeling based skip-gram approach for learning multi-prototype word embeddings. We also introduce a method to prune the embeddings determined by the probabilistic representation of the word in each topic. We use our embeddings to show that they can capture the context and word similarity strongly and outperform various state-of-the-art implementations.
* 8 pages, 1 figure, 7 tables