 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDomain Specific Fine-tuning of Denoising Sequence-to-Sequence Models for Natural Language Summarization
Apr 06, 2022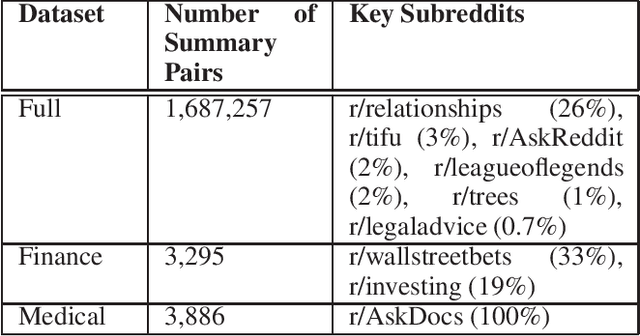
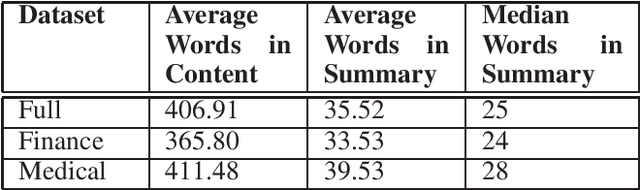
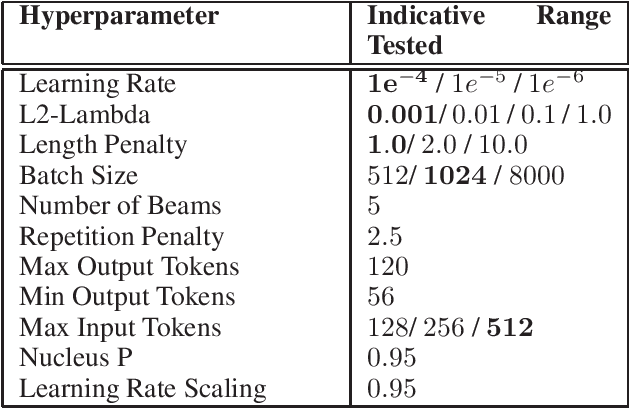

Summarization of long-form text data is a problem especially pertinent in knowledge economy jobs such as medicine and finance, that require continuously remaining informed on a sophisticated and evolving body of knowledge. As such, isolating and summarizing key content automatically using Natural Language Processing (NLP) techniques holds the potential for extensive time savings in these industries. We explore applications of a state-of-the-art NLP model (BART), and explore strategies for tuning it to optimal performance using data augmentation and various fine-tuning strategies. We show that our end-to-end fine-tuning approach can result in a 5-6\% absolute ROUGE-1 improvement over an out-of-the-box pre-trained BART summarizer when tested on domain specific data, and make available our end-to-end pipeline to achieve these results on finance, medical, or other user-specified domains.
Improving Tree-LSTM with Tree Attention
Jan 01, 2019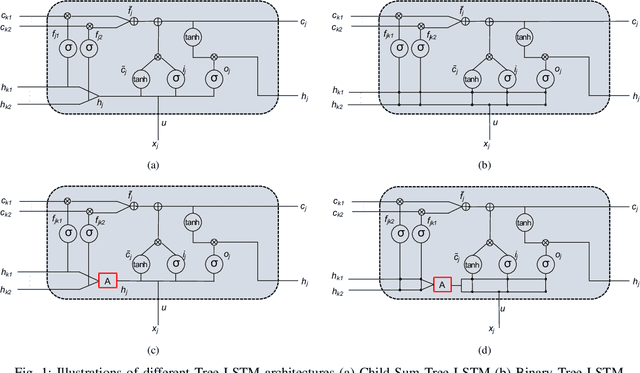
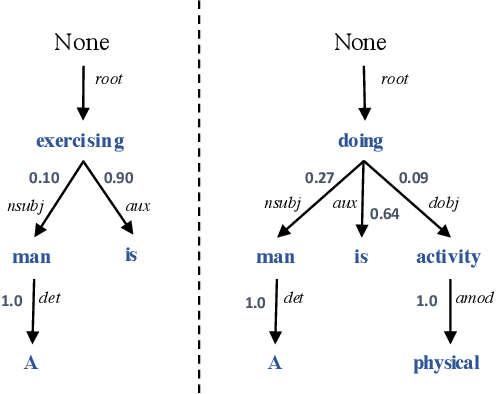
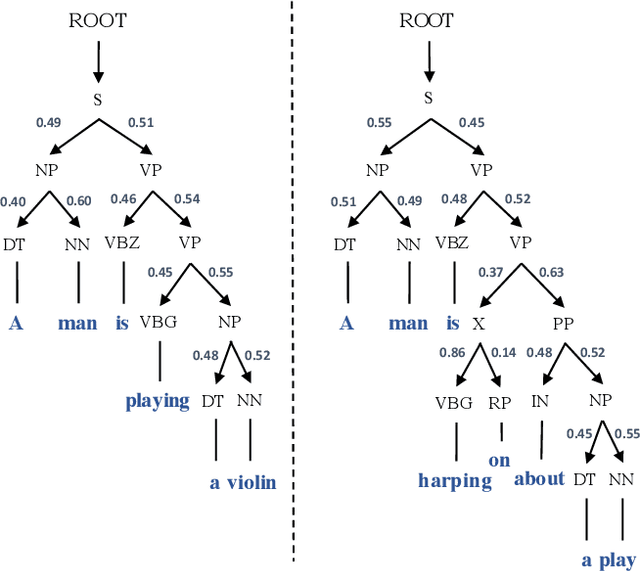
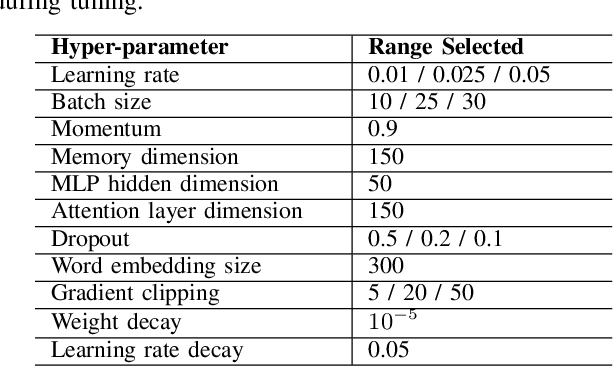
In Natural Language Processing (NLP), we often need to extract information from tree topology. Sentence structure can be represented via a dependency tree or a constituency tree structure. For this reason, a variant of LSTMs, named Tree-LSTM, was proposed to work on tree topology. In this paper, we design a generalized attention framework for both dependency and constituency trees by encoding variants of decomposable attention inside a Tree-LSTM cell. We evaluated our models on a semantic relatedness task and achieved notable results compared to Tree-LSTM based methods with no attention as well as other neural and non-neural methods and good results compared to Tree-LSTM based methods with attention.
A Novel Neural Sequence Model with Multiple Attentions for Word Sense Disambiguation
Sep 04, 2018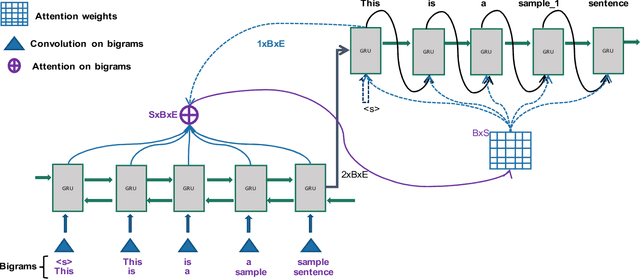
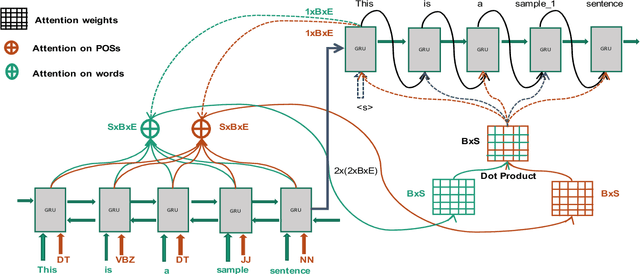
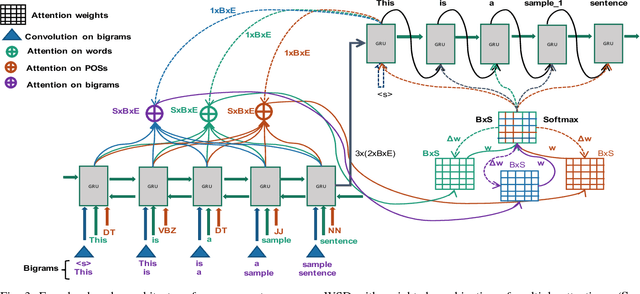
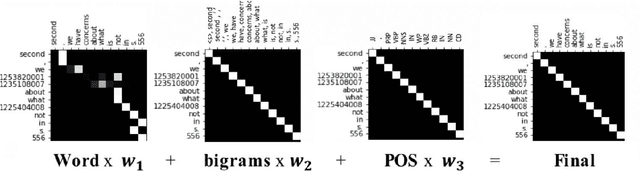
Word sense disambiguation (WSD) is a well researched problem in computational linguistics. Different research works have approached this problem in different ways. Some state of the art results that have been achieved for this problem are by supervised models in terms of accuracy, but they often fall behind flexible knowledge-based solutions which use engineered features as well as human annotators to disambiguate every target word. This work focuses on bridging this gap using neural sequence models incorporating the well-known attention mechanism. The main gist of our work is to combine multiple attentions on different linguistic features through weights and to provide a unified framework for doing this. This weighted attention allows the model to easily disambiguate the sense of an ambiguous word by attending over a suitable portion of a sentence. Our extensive experiments show that multiple attention enables a more versatile encoder-decoder model leading to state of the art results.
Identifying Protein-Protein Interaction using Tree LSTM and Structured Attention
Jul 27, 2018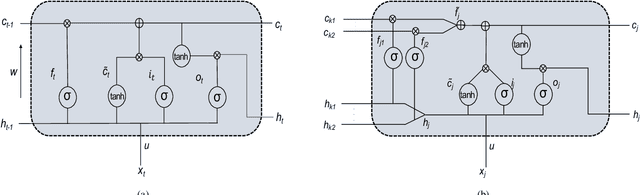
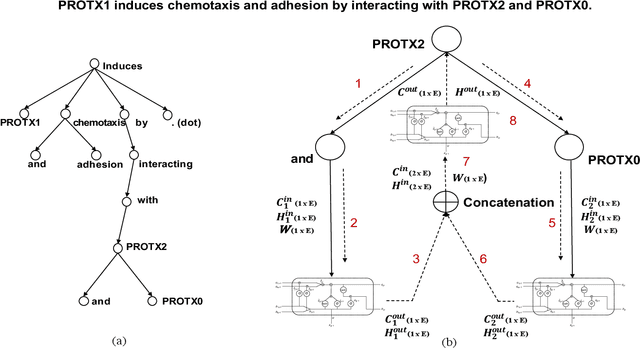
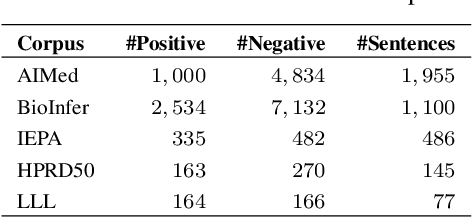
Identifying interactions between proteins is important to understand underlying biological processes. Extracting a protein-protein interaction (PPI) from the raw text is often very difficult. Previous supervised learning methods have used handcrafted features on human-annotated data sets. In this paper, we propose a novel tree recurrent neural network with structured attention architecture for doing PPI. Our architecture achieves state of the art results (precision, recall, and F1-score) on the AIMed and BioInfer benchmark data sets. Moreover, our models achieve a significant improvement over previous best models without any explicit feature extraction. Our experimental results show that traditional recurrent networks have inferior performance compared to tree recurrent networks for the supervised PPI problem.
Improving Neural Sequence Labelling using Additional Linguistic Information
Jul 27, 2018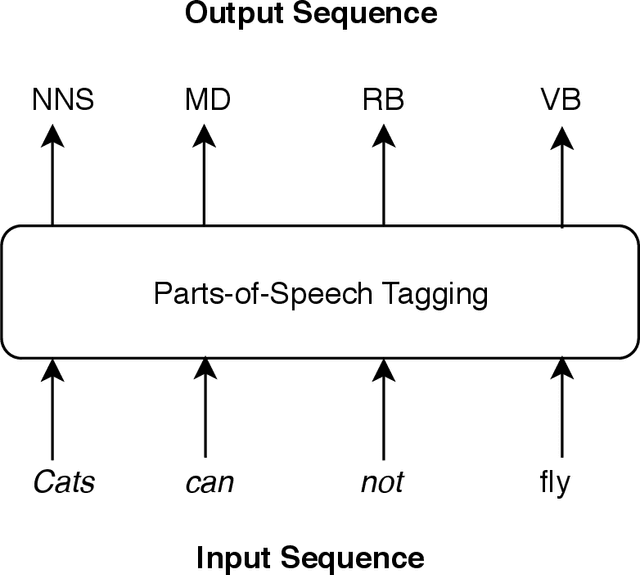
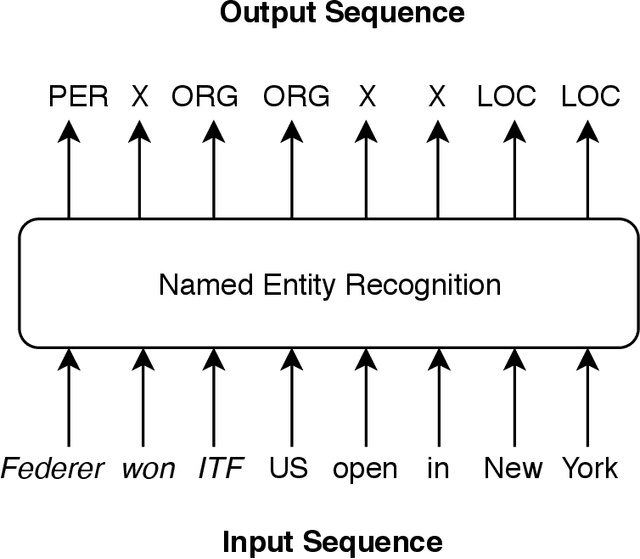
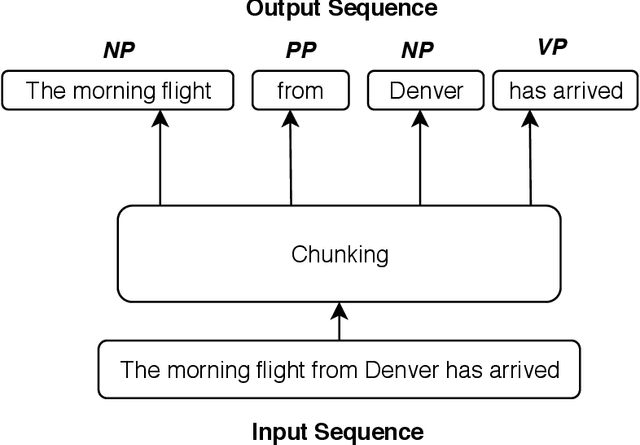
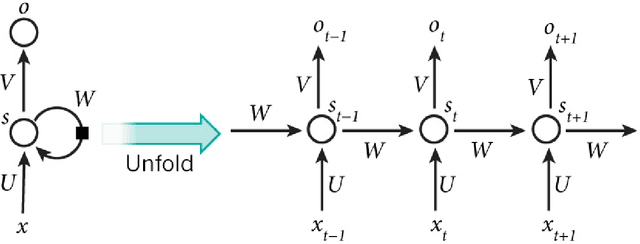
Sequence labelling is the task of assigning categorical labels to a data sequence. In Natural Language Processing, sequence labelling can be applied to various fundamental problems, such as Part of Speech (POS) tagging, Named Entity Recognition (NER), and Chunking. In this study, we propose a method to add various linguistic features to the neural sequence framework to improve sequence labelling. Besides word level knowledge, sense embeddings are added to provide semantic information. Additionally, selective readings of character embeddings are added to capture contextual as well as morphological features for each word in a sentence. Compared to previous methods, these added linguistic features allow us to design a more concise model and perform more efficient training. Our proposed architecture achieves state of the art results on the benchmark datasets of POS, NER, and chunking. Moreover, the convergence rate of our model is significantly better than the previous state of the art models.