 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Neural Sequence Labelling using Additional Linguistic Information
Paper and Code
Jul 27, 2018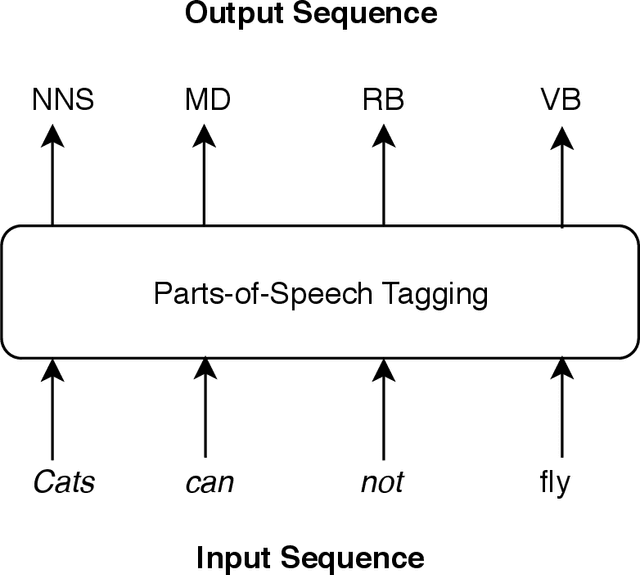
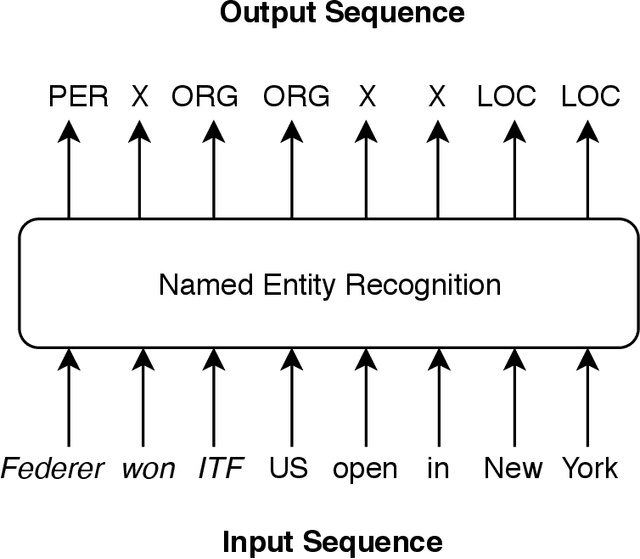
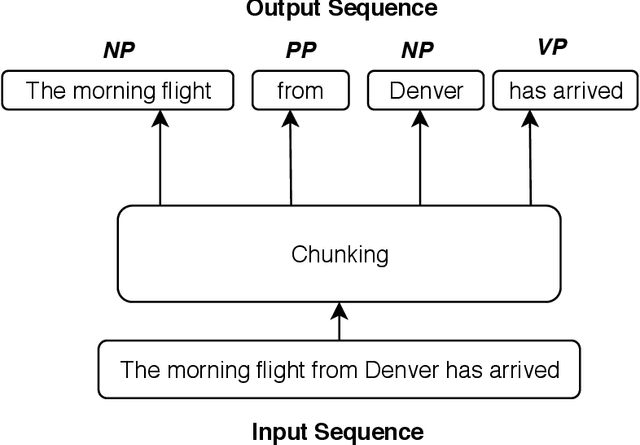
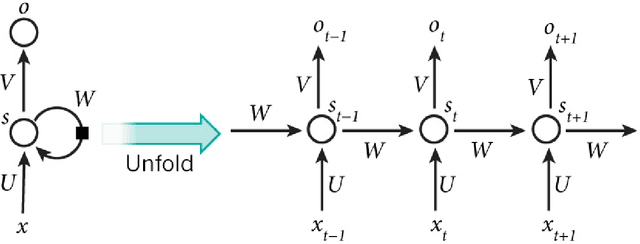
Sequence labelling is the task of assigning categorical labels to a data sequence. In Natural Language Processing, sequence labelling can be applied to various fundamental problems, such as Part of Speech (POS) tagging, Named Entity Recognition (NER), and Chunking. In this study, we propose a method to add various linguistic features to the neural sequence framework to improve sequence labelling. Besides word level knowledge, sense embeddings are added to provide semantic information. Additionally, selective readings of character embeddings are added to capture contextual as well as morphological features for each word in a sentence. Compared to previous methods, these added linguistic features allow us to design a more concise model and perform more efficient training. Our proposed architecture achieves state of the art results on the benchmark datasets of POS, NER, and chunking. Moreover, the convergence rate of our model is significantly better than the previous state of the art models.