 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOolong: Investigating What Makes Crosslingual Transfer Hard with Controlled Studies
Paper and Code
Feb 24, 2022

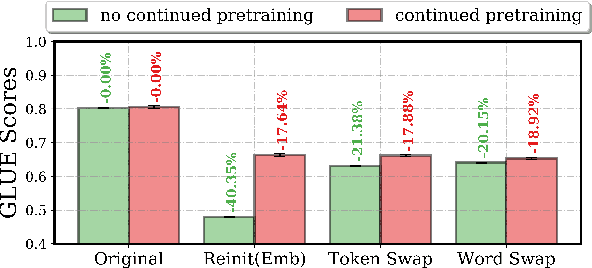
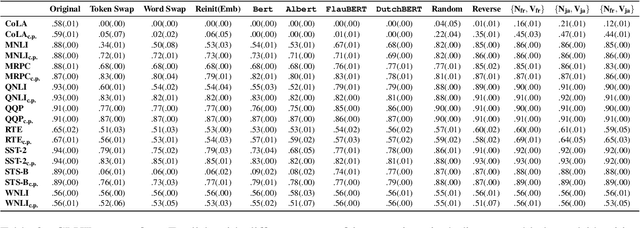
Little is known about what makes cross-lingual transfer hard, since factors like tokenization, morphology, and syntax all change at once between languages. To disentangle the impact of these factors, we propose a set of controlled transfer studies: we systematically transform GLUE tasks to alter different factors one at a time, then measure the resulting drops in a pretrained model's downstream performance. In contrast to prior work suggesting little effect from syntax on knowledge transfer, we find significant impacts from syntactic shifts (3-6% drop), though models quickly adapt with continued pretraining on a small dataset. However, we find that by far the most impactful factor for crosslingual transfer is the challenge of aligning the new embeddings with the existing transformer layers (18% drop), with little additional effect from switching tokenizers (<2% drop) or word morphologies (<2% drop). Moreover, continued pretraining with a small dataset is not very effective at closing this gap - suggesting that new directions are needed for solving this problem.