 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProjecting Assumptions: The Duality Between Sparse Autoencoders and Concept Geometry
Paper and Code
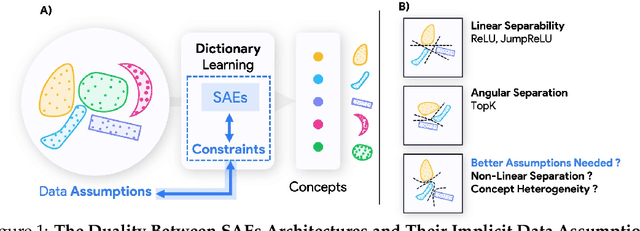
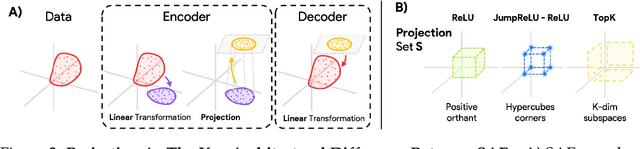
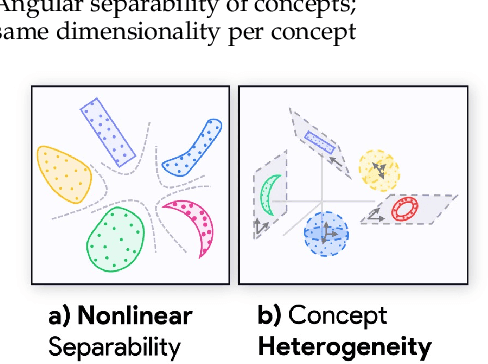

Sparse Autoencoders (SAEs) are widely used to interpret neural networks by identifying meaningful concepts from their representations. However, do SAEs truly uncover all concepts a model relies on, or are they inherently biased toward certain kinds of concepts? We introduce a unified framework that recasts SAEs as solutions to a bilevel optimization problem, revealing a fundamental challenge: each SAE imposes structural assumptions about how concepts are encoded in model representations, which in turn shapes what it can and cannot detect. This means different SAEs are not interchangeable -- switching architectures can expose entirely new concepts or obscure existing ones. To systematically probe this effect, we evaluate SAEs across a spectrum of settings: from controlled toy models that isolate key variables, to semi-synthetic experiments on real model activations and finally to large-scale, naturalistic datasets. Across this progression, we examine two fundamental properties that real-world concepts often exhibit: heterogeneity in intrinsic dimensionality (some concepts are inherently low-dimensional, others are not) and nonlinear separability. We show that SAEs fail to recover concepts when these properties are ignored, and we design a new SAE that explicitly incorporates both, enabling the discovery of previously hidden concepts and reinforcing our theoretical insights. Our findings challenge the idea of a universal SAE and underscores the need for architecture-specific choices in model interpretability. Overall, we argue an SAE does not just reveal concepts -- it determines what can be seen at all.