 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExpressive Timing in Hindustani Vocal Music
Mar 27, 2025Temporal dynamics are among the cues to expres siveness in music performance in different cultures. In the case of Hindustani music, it is well known that expert vocalists often take liberties with the beat, intentionally not aligning their singing precisely with the relatively steady beat provided by the accompanying tabla. This becomes evident when comparing performances of the same composition such as a bandish. We present a methodology for the quantitative study of differences across performed pieces using computational techniques. This is applied to small study of two performances of a popular bandish in raga Yaman, to demonstrate how we can effectively capture the nuances of timing variations that bring out stylistic constraints along with the individual signature of a performer. This work articulates an important step towards the broader goals of music analysis and generative modelling for Indian classical music performance.
Deep Learning for Assessment of Oral Reading Fluency
Jun 01, 2024Reading fluency assessment is a critical component of literacy programmes, serving to guide and monitor early education interventions. Given the resource intensive nature of the exercise when conducted by teachers, the development of automatic tools that can operate on audio recordings of oral reading is attractive as an objective and highly scalable solution. Multiple complex aspects such as accuracy, rate and expressiveness underlie human judgements of reading fluency. In this work, we investigate end-to-end modeling on a training dataset of children's audio recordings of story texts labeled by human experts. The pre-trained wav2vec2.0 model is adopted due its potential to alleviate the challenges from the limited amount of labeled data. We report the performance of a number of system variations on the relevant measures, and also probe the learned embeddings for lexical and acoustic-prosodic features known to be important to the perception of reading fluency.
Musical Information Extraction from the Singing Voice
Apr 07, 2022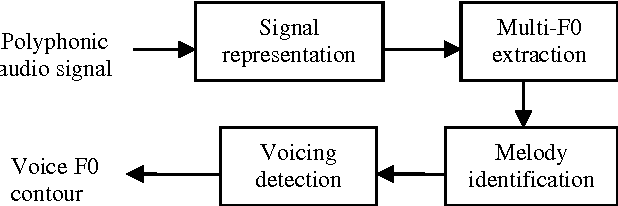

Music information retrieval is currently an active research area that addresses the extraction of musically important information from audio signals, and the applications of such information. The extracted information can be used for search and retrieval of music in recommendation systems, or to aid musicological studies or even in music learning. Sophisticated signal processing techniques are applied to convert low-level acoustic signal properties to musical attributes which are further embedded in a rule-based or statistical classification framework to link with high-level descriptions such as melody, genre, mood and artist type. Vocal music comprises a large and interesting category of music where the lead instrument is the singing voice. The singing voice is more versatile than many musical instruments and therefore poses interesting challenges to information retrieval systems. In this paper, we provide a brief overview of research in vocal music processing followed by a description of related work at IIT Bombay leading to the development of an interface for melody detection of singing voice in polyphony.
Predicting lexical skills from oral reading with acoustic measures
Dec 01, 2021



Literacy assessment is an important activity for education administrators across the globe. Typically achieved in a school setting by testing a child's oral reading, it is intensive in human resources. While automatic speech recognition (ASR) is a potential solution to the problem, it tends to be computationally expensive for hand-held devices apart from needing language and accent-specific speech for training. In this work, we propose a system to predict the word-decoding skills of a student based on simple acoustic features derived from the recording. We first identify a meaningful categorization of word-decoding skills by analyzing a manually transcribed data set of children's oral reading recordings. Next the automatic prediction of the category is attempted with the proposed acoustic features. Pause statistics, syllable rate and spectral and intensity dynamics are found to be reliable indicators of specific types of oral reading deficits, providing useful feedback by discriminating the different characteristics of beginning readers. This computationally simple and language-agnostic approach is found to provide a performance close to that obtained using a language dependent ASR that required considerable tuning of its parameters.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021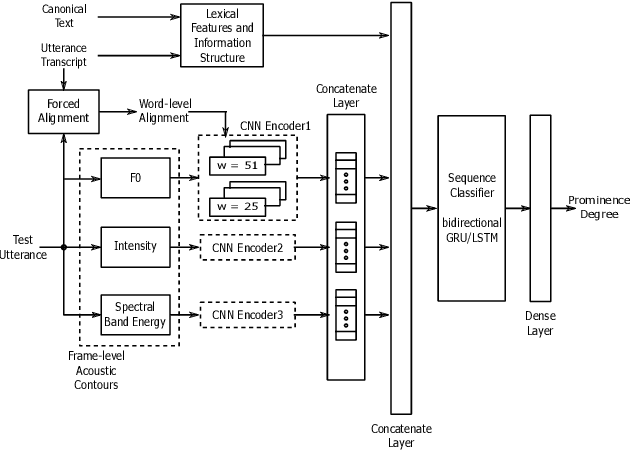
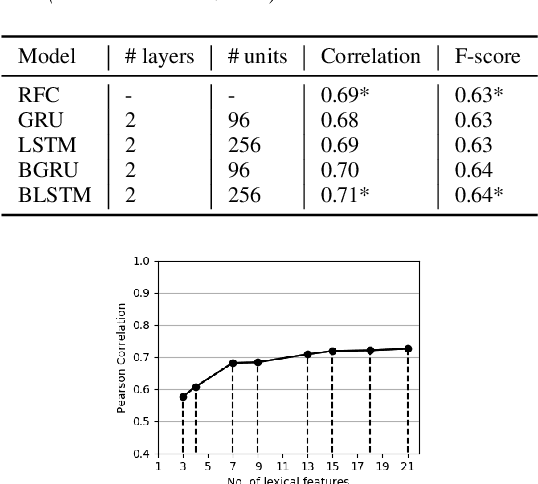
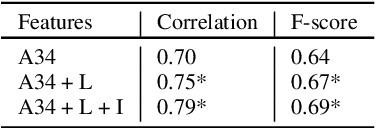
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.
Automatic Stroke Classification of Tabla Accompaniment in Hindustani Vocal Concert Audio
Apr 19, 2021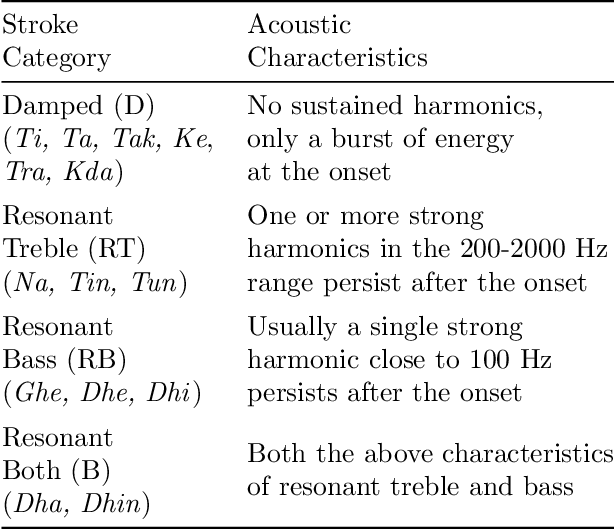
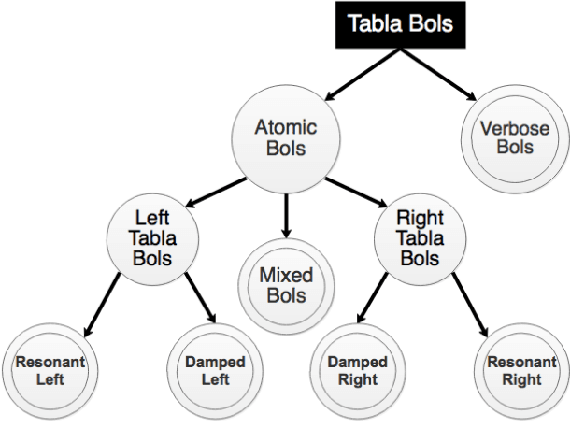
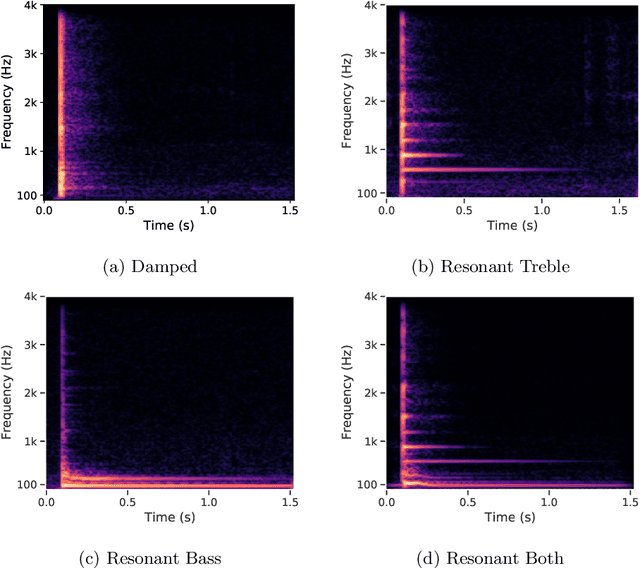

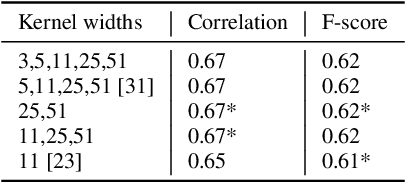
The tabla is a unique percussion instrument due to the combined harmonic and percussive nature of its timbre, and the contrasting harmonic frequency ranges of its two drums. This allows a tabla player to uniquely emphasize parts of the rhythmic cycle (theka) in order to mark the salient positions. An analysis of the loudness dynamics and timing deviations at various cycle positions is an important part of musicological studies on the expressivity in tabla accompaniment. To achieve this at a corpus-level, and not restrict it to the few recordings that manual annotation can afford, it is helpful to have access to an automatic tabla transcription system. Although a few systems have been built by training models on labeled tabla strokes, the achieved accuracy does not necessarily carry over to unseen instruments. In this article, we report our work towards building an instrument-independent stroke classification system for accompaniment tabla based on the more easily available tabla solo audio tracks. We present acoustic features that capture the distinctive characteristics of tabla strokes and build an automatic system to predict the label as one of a reduced, but musicologically motivated, target set of four stroke categories. To address the lack of sufficient labeled training data, we turn to common data augmentation methods and find the use of pitch-shifting based augmentation to be most promising. We then analyse the important features and highlight the problem of their instrument-dependence while motivating the use of more task-specific data augmentation strategies to improve the diversity of training data.
An Optimized Signal Processing Pipeline for Syllable Detection and Speech Rate Estimation
Mar 07, 2021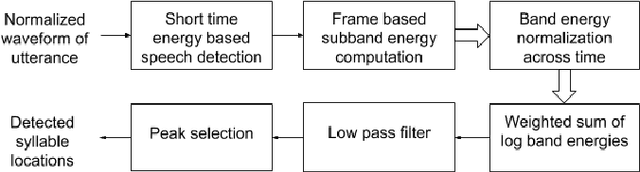
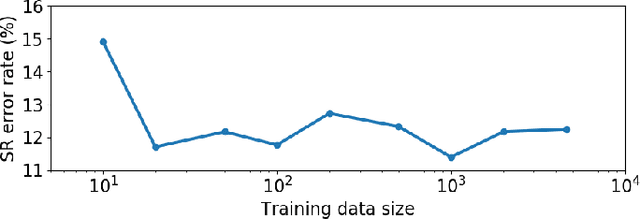
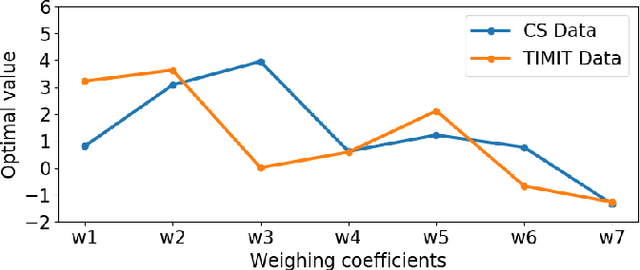

Syllable detection is an important speech analysis task with applications in speech rate estimation, word segmentation, and automatic prosody detection. Based on the well understood acoustic correlates of speech articulation, it has been realized by local peak picking on a frequency-weighted energy contour that represents vowel sonority. While several of the analysis parameters are set based on known speech signal properties, the selection of the frequency-weighting coefficients and peak-picking threshold typically involves heuristics, raising the possibility of data-based optimisation. In this work, we consider the optimization of the parameters based on the direct minimization of naturally arising task-specific objective functions. The resulting non-convex cost function is minimized using a population-based search algorithm to achieve a performance that exceeds previously published performance results on the same corpus using a relatively low amount of labeled data. Further, the optimisation of system parameters on a different corpus is shown to result in an explainable change in the optimal values.
HpRNet : Incorporating Residual Noise Modeling for Violin in a Variational Parametric Synthesizer
Aug 19, 2020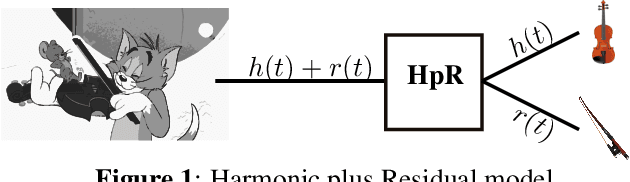



Generative Models for Audio Synthesis have been gaining momentum in the last few years. More recently, parametric representations of the audio signal have been incorporated to facilitate better musical control of the synthesized output. In this work, we investigate a parametric model for violin tones, in particular the generative modeling of the residual bow noise to make for more natural tone quality. To aid in our analysis, we introduce a dataset of Carnatic Violin Recordings where bow noise is an integral part of the playing style of higher pitched notes in specific gestural contexts. We obtain insights about each of the harmonic and residual components of the signal, as well as their interdependence, via observations on the latent space derived in the course of variational encoding of the spectral envelopes of the sustained sounds.
Structure and Automatic Segmentation of Dhrupad Vocal Bandish Audio
Aug 03, 2020

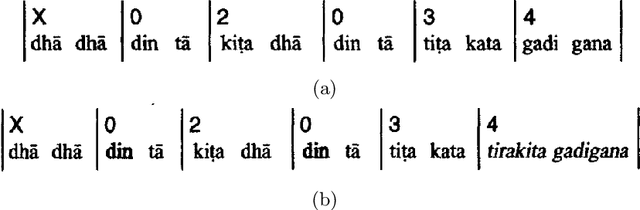

A Dhrupad vocal concert comprises a composition section that is interspersed with improvised episodes of increased rhythmic activity involving the interaction between the vocals and the percussion. Tracking the changing rhythmic density, in relation to the underlying metric tempo of the piece, thus facilitates the detection and labeling of the improvised sections in the concert structure. This work concerns the automatic detection of the musically relevant rhythmic densities as they change in time across the bandish (composition) performance. An annotated dataset of Dhrupad bandish concert sections is presented. We investigate a CNN-based system, trained to detect local tempo relationships, and follow it with temporal smoothing. We also employ audio source separation as a pre-processing step to the detection of the individual surface densities of the vocals and the percussion. This helps us obtain the complete musical description of the concert sections in terms of capturing the changing rhythmic interaction of the two performers.
VaPar Synth -- A Variational Parametric Model for Audio Synthesis
Mar 30, 2020

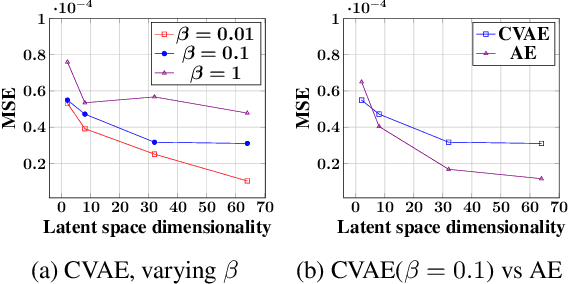
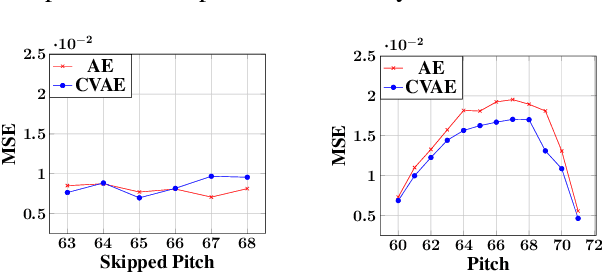
With the advent of data-driven statistical modeling and abundant computing power, researchers are turning increasingly to deep learning for audio synthesis. These methods try to model audio signals directly in the time or frequency domain. In the interest of more flexible control over the generated sound, it could be more useful to work with a parametric representation of the signal which corresponds more directly to the musical attributes such as pitch, dynamics and timbre. We present VaPar Synth - a Variational Parametric Synthesizer which utilizes a conditional variational autoencoder (CVAE) trained on a suitable parametric representation. We demonstrate our proposed model's capabilities via the reconstruction and generation of instrumental tones with flexible control over their pitch.