 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePredicting lexical skills from oral reading with acoustic measures
Dec 01, 2021



Literacy assessment is an important activity for education administrators across the globe. Typically achieved in a school setting by testing a child's oral reading, it is intensive in human resources. While automatic speech recognition (ASR) is a potential solution to the problem, it tends to be computationally expensive for hand-held devices apart from needing language and accent-specific speech for training. In this work, we propose a system to predict the word-decoding skills of a student based on simple acoustic features derived from the recording. We first identify a meaningful categorization of word-decoding skills by analyzing a manually transcribed data set of children's oral reading recordings. Next the automatic prediction of the category is attempted with the proposed acoustic features. Pause statistics, syllable rate and spectral and intensity dynamics are found to be reliable indicators of specific types of oral reading deficits, providing useful feedback by discriminating the different characteristics of beginning readers. This computationally simple and language-agnostic approach is found to provide a performance close to that obtained using a language dependent ASR that required considerable tuning of its parameters.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021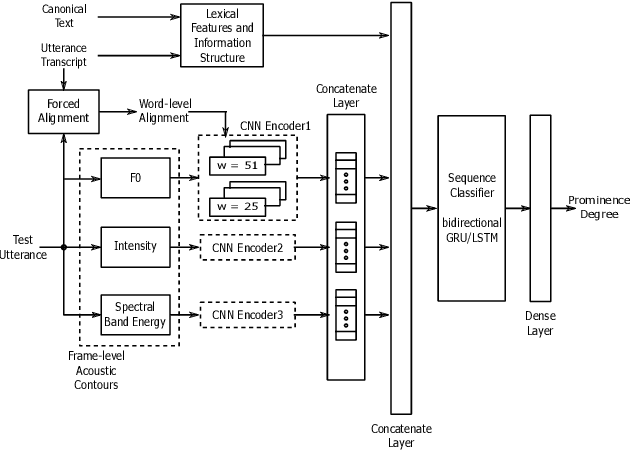
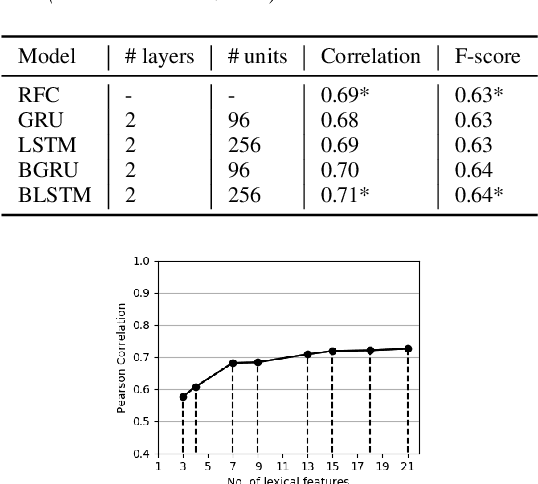
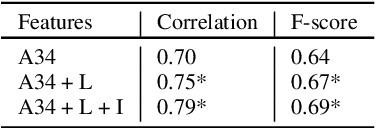
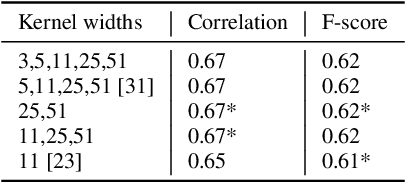
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.
An Optimized Signal Processing Pipeline for Syllable Detection and Speech Rate Estimation
Mar 07, 2021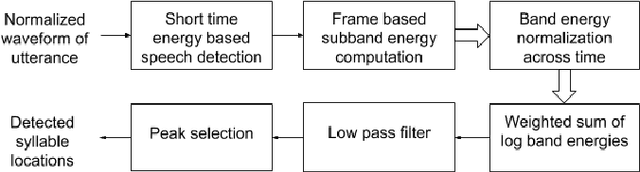
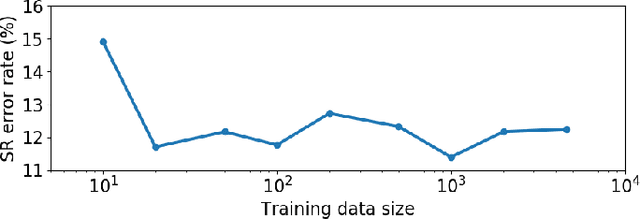
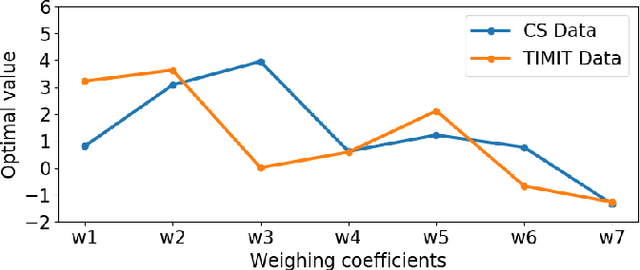

Syllable detection is an important speech analysis task with applications in speech rate estimation, word segmentation, and automatic prosody detection. Based on the well understood acoustic correlates of speech articulation, it has been realized by local peak picking on a frequency-weighted energy contour that represents vowel sonority. While several of the analysis parameters are set based on known speech signal properties, the selection of the frequency-weighting coefficients and peak-picking threshold typically involves heuristics, raising the possibility of data-based optimisation. In this work, we consider the optimization of the parameters based on the direct minimization of naturally arising task-specific objective functions. The resulting non-convex cost function is minimized using a population-based search algorithm to achieve a performance that exceeds previously published performance results on the same corpus using a relatively low amount of labeled data. Further, the optimisation of system parameters on a different corpus is shown to result in an explainable change in the optimal values.