 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRobust Estimation Under Heterogeneous Corruption Rates
Aug 20, 2025We study the problem of robust estimation under heterogeneous corruption rates, where each sample may be independently corrupted with a known but non-identical probability. This setting arises naturally in distributed and federated learning, crowdsourcing, and sensor networks, yet existing robust estimators typically assume uniform or worst-case corruption, ignoring structural heterogeneity. For mean estimation for multivariate bounded distributions and univariate gaussian distributions, we give tight minimax rates for all heterogeneous corruption patterns. For multivariate gaussian mean estimation and linear regression, we establish the minimax rate for squared error up to a factor of $\sqrt{d}$, where $d$ is the dimension. Roughly, our findings suggest that samples beyond a certain corruption threshold may be discarded by the optimal estimators -- this threshold is determined by the empirical distribution of the corruption rates given.
Enhancing Feature-Specific Data Protection via Bayesian Coordinate Differential Privacy
Oct 24, 2024


Local Differential Privacy (LDP) offers strong privacy guarantees without requiring users to trust external parties. However, LDP applies uniform protection to all data features, including less sensitive ones, which degrades performance of downstream tasks. To overcome this limitation, we propose a Bayesian framework, Bayesian Coordinate Differential Privacy (BCDP), that enables feature-specific privacy quantification. This more nuanced approach complements LDP by adjusting privacy protection according to the sensitivity of each feature, enabling improved performance of downstream tasks without compromising privacy. We characterize the properties of BCDP and articulate its connections with standard non-Bayesian privacy frameworks. We further apply our BCDP framework to the problems of private mean estimation and ordinary least-squares regression. The BCDP-based approach obtains improved accuracy compared to a purely LDP-based approach, without compromising on privacy.
Empirical Mean and Frequency Estimation Under Heterogeneous Privacy: A Worst-Case Analysis
Jul 15, 2024Differential Privacy (DP) is the current gold-standard for measuring privacy. Estimation problems under DP constraints appearing in the literature have largely focused on providing equal privacy to all users. We consider the problems of empirical mean estimation for univariate data and frequency estimation for categorical data, two pillars of data analysis in the industry, subject to heterogeneous privacy constraints. Each user, contributing a sample to the dataset, is allowed to have a different privacy demand. The dataset itself is assumed to be worst-case and we study both the problems in two different formulations -- the correlated and the uncorrelated setting. In the former setting, the privacy demand and the user data can be arbitrarily correlated while in the latter setting, there is no correlation between the dataset and the privacy demand. We prove some optimality results, under both PAC error and mean-squared error, for our proposed algorithms and demonstrate superior performance over other baseline techniques experimentally.
Mean Estimation Under Heterogeneous Privacy Demands
Oct 19, 2023

Differential Privacy (DP) is a well-established framework to quantify privacy loss incurred by any algorithm. Traditional formulations impose a uniform privacy requirement for all users, which is often inconsistent with real-world scenarios in which users dictate their privacy preferences individually. This work considers the problem of mean estimation, where each user can impose their own distinct privacy level. The algorithm we propose is shown to be minimax optimal and has a near-linear run-time. Our results elicit an interesting saturation phenomenon that occurs. Namely, the privacy requirements of the most stringent users dictate the overall error rates. As a consequence, users with less but differing privacy requirements are all given more privacy than they require, in equal amounts. In other words, these privacy-indifferent users are given a nontrivial degree of privacy for free, without any sacrifice in the performance of the estimator.
Online Target Q-learning with Reverse Experience Replay: Efficiently finding the Optimal Policy for Linear MDPs
Oct 19, 2021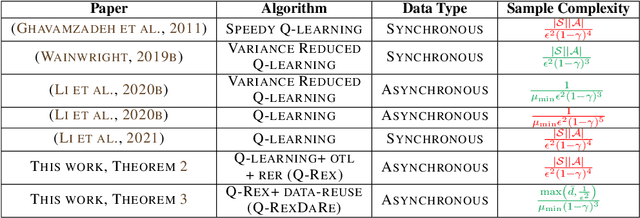
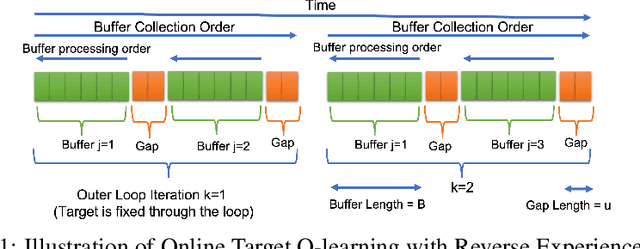

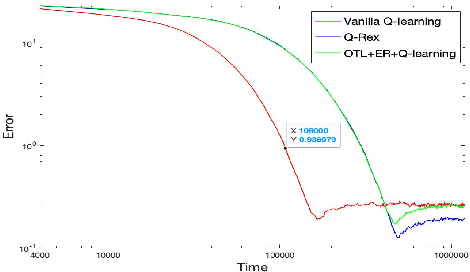
Q-learning is a popular Reinforcement Learning (RL) algorithm which is widely used in practice with function approximation (Mnih et al., 2015). In contrast, existing theoretical results are pessimistic about Q-learning. For example, (Baird, 1995) shows that Q-learning does not converge even with linear function approximation for linear MDPs. Furthermore, even for tabular MDPs with synchronous updates, Q-learning was shown to have sub-optimal sample complexity (Li et al., 2021;Azar et al., 2013). The goal of this work is to bridge the gap between practical success of Q-learning and the relatively pessimistic theoretical results. The starting point of our work is the observation that in practice, Q-learning is used with two important modifications: (i) training with two networks, called online network and target network simultaneously (online target learning, or OTL) , and (ii) experience replay (ER) (Mnih et al., 2015). While they have been observed to play a significant role in the practical success of Q-learning, a thorough theoretical understanding of how these two modifications improve the convergence behavior of Q-learning has been missing in literature. By carefully combining Q-learning with OTL and reverse experience replay (RER) (a form of experience replay), we present novel methods Q-Rex and Q-RexDaRe (Q-Rex + data reuse). We show that Q-Rex efficiently finds the optimal policy for linear MDPs (or more generally for MDPs with zero inherent Bellman error with linear approximation (ZIBEL)) and provide non-asymptotic bounds on sample complexity -- the first such result for a Q-learning method for this class of MDPs under standard assumptions. Furthermore, we demonstrate that Q-RexDaRe in fact achieves near optimal sample complexity in the tabular setting, improving upon the existing results for vanilla Q-learning.
An Optimized Signal Processing Pipeline for Syllable Detection and Speech Rate Estimation
Mar 07, 2021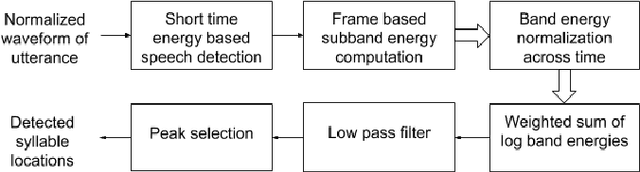
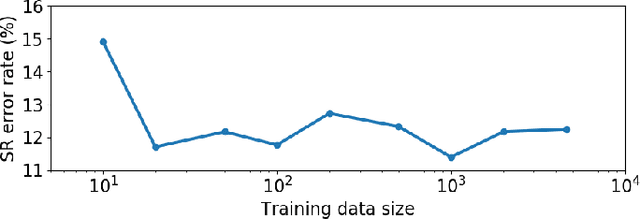
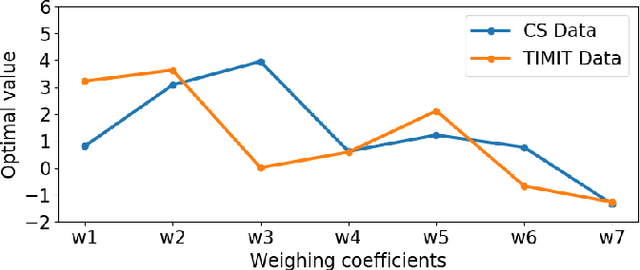

Syllable detection is an important speech analysis task with applications in speech rate estimation, word segmentation, and automatic prosody detection. Based on the well understood acoustic correlates of speech articulation, it has been realized by local peak picking on a frequency-weighted energy contour that represents vowel sonority. While several of the analysis parameters are set based on known speech signal properties, the selection of the frequency-weighting coefficients and peak-picking threshold typically involves heuristics, raising the possibility of data-based optimisation. In this work, we consider the optimization of the parameters based on the direct minimization of naturally arising task-specific objective functions. The resulting non-convex cost function is minimized using a population-based search algorithm to achieve a performance that exceeds previously published performance results on the same corpus using a relatively low amount of labeled data. Further, the optimisation of system parameters on a different corpus is shown to result in an explainable change in the optimal values.
GuCNet: A Guided Clustering-based Network for Improved Classification
Oct 11, 2020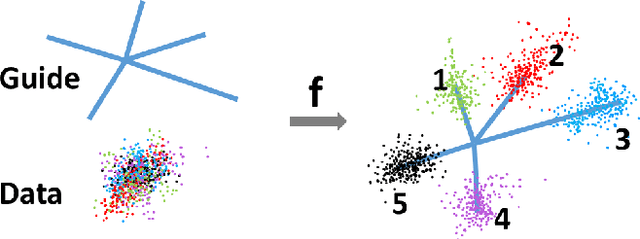
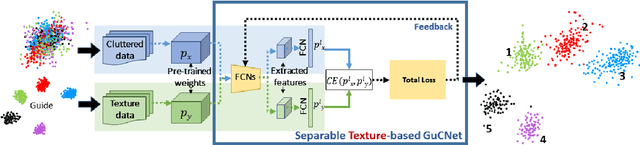
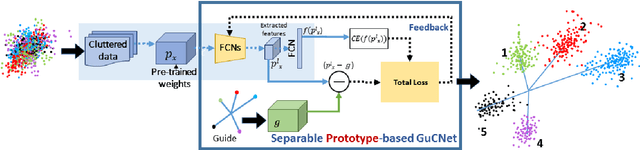

We deal with the problem of semantic classification of challenging and highly-cluttered dataset. We present a novel, and yet a very simple classification technique by leveraging the ease of classifiability of any existing well separable dataset for guidance. Since the guide dataset which may or may not have any semantic relationship with the experimental dataset, forms well separable clusters in the feature set, the proposed network tries to embed class-wise features of the challenging dataset to those distinct clusters of the guide set, making them more separable. Depending on the availability, we propose two types of guide sets: one using texture (image) guides and another using prototype vectors representing cluster centers. Experimental results obtained on the challenging benchmark RSSCN, LSUN, and TU-Berlin datasets establish the efficacy of the proposed method as we outperform the existing state-of-the-art techniques by a considerable margin.
SPAN: Spatial Pyramid Attention Network forImage Manipulation Localization
Sep 01, 2020
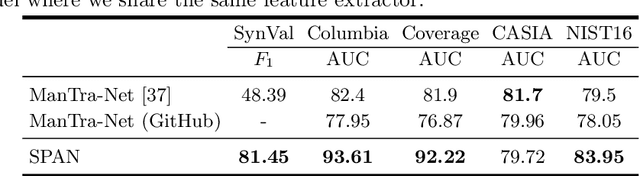
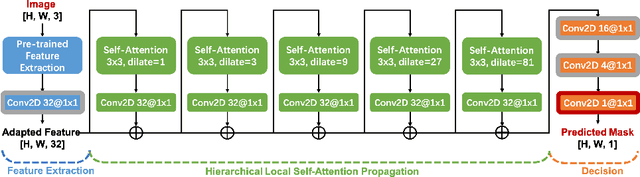
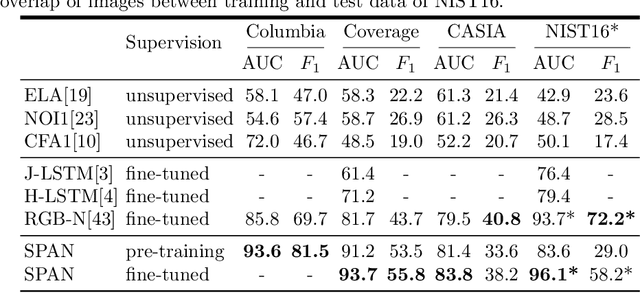
We present a novel framework, Spatial Pyramid Attention Network (SPAN) for detection and localization of multiple types of image manipulations. The proposed architecture efficiently and effectively models the relationship between image patches at multiple scales by constructing a pyramid of local self-attention blocks. The design includes a novel position projection to encode the spatial positions of the patches. SPAN is trained on a generic, synthetic dataset but can also be fine tuned for specific datasets; The proposed method shows significant gains in performance on standard datasets over previous state-of-the-art methods.