 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeZero-Shot Sketch Based Image Retrieval using Graph Transformer
Jan 25, 2022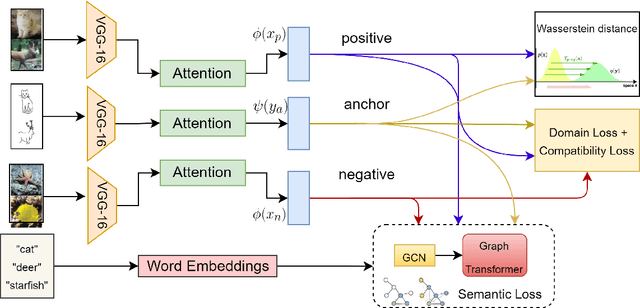
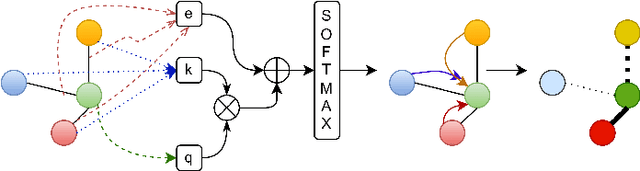

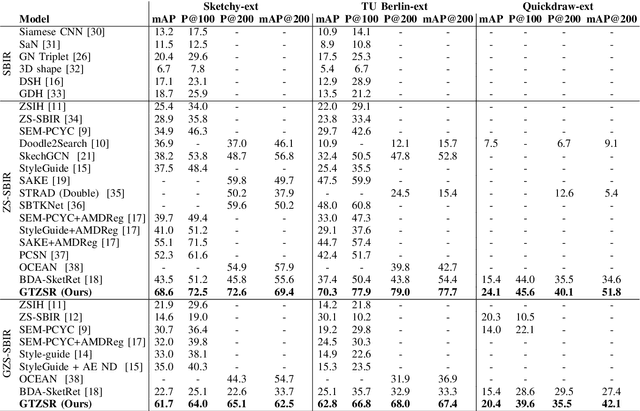
The performance of a zero-shot sketch-based image retrieval (ZS-SBIR) task is primarily affected by two challenges. The substantial domain gap between image and sketch features needs to be bridged, while at the same time the side information has to be chosen tactfully. Existing literature has shown that varying the semantic side information greatly affects the performance of ZS-SBIR. To this end, we propose a novel graph transformer based zero-shot sketch-based image retrieval (GTZSR) framework for solving ZS-SBIR tasks which uses a novel graph transformer to preserve the topology of the classes in the semantic space and propagates the context-graph of the classes within the embedding features of the visual space. To bridge the domain gap between the visual features, we propose minimizing the Wasserstein distance between images and sketches in a learned domain-shared space. We also propose a novel compatibility loss that further aligns the two visual domains by bridging the domain gap of one class with respect to the domain gap of all other classes in the training set. Experimental results obtained on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the existing state-of-the-art methods in both ZS-SBIR and generalized ZS-SBIR.
BDA-SketRet: Bi-Level Domain Adaptation for Zero-Shot SBIR
Jan 17, 2022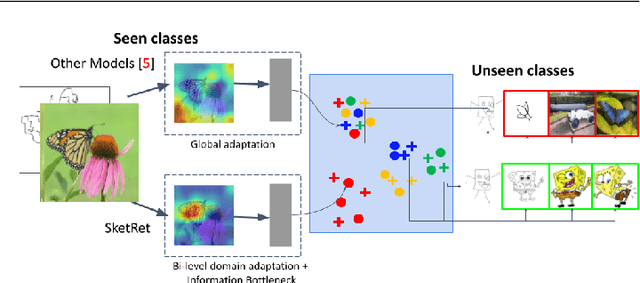
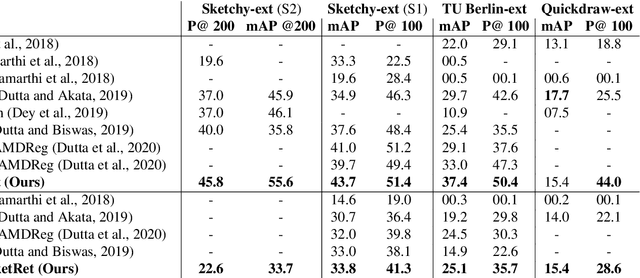
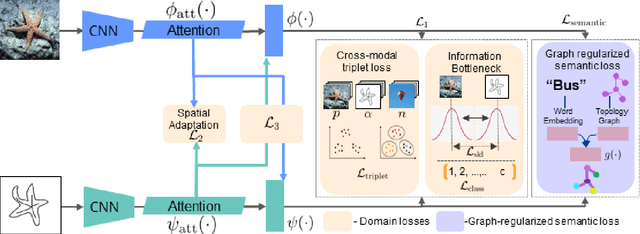
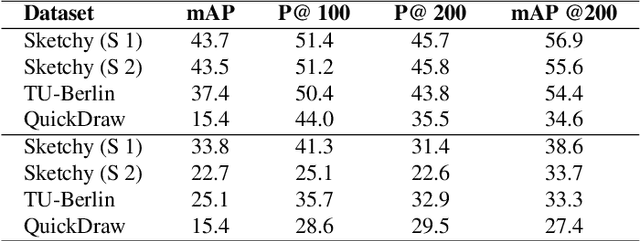
The efficacy of zero-shot sketch-based image retrieval (ZS-SBIR) models is governed by two challenges. The immense distributions-gap between the sketches and the images requires a proper domain alignment. Moreover, the fine-grained nature of the task and the high intra-class variance of many categories necessitates a class-wise discriminative mapping among the sketch, image, and the semantic spaces. Under this premise, we propose BDA-SketRet, a novel ZS-SBIR framework performing a bi-level domain adaptation for aligning the spatial and semantic features of the visual data pairs progressively. In order to highlight the shared features and reduce the effects of any sketch or image-specific artifacts, we propose a novel symmetric loss function based on the notion of information bottleneck for aligning the semantic features while a cross-entropy-based adversarial loss is introduced to align the spatial feature maps. Finally, our CNN-based model confirms the discriminativeness of the shared latent space through a novel topology-preserving semantic projection network. Experimental results on the extended Sketchy, TU-Berlin, and QuickDraw datasets exhibit sharp improvements over the literature.
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021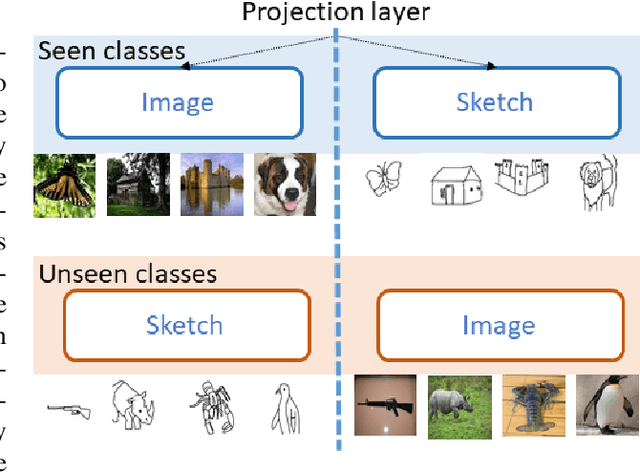
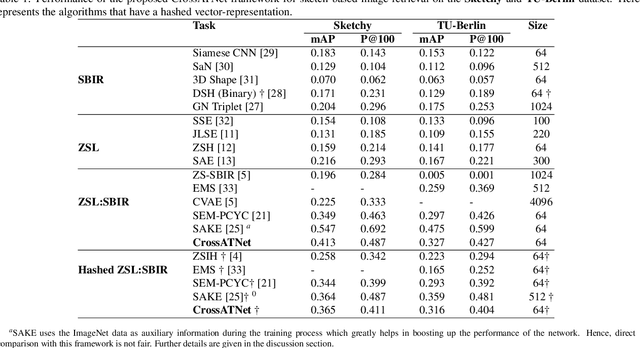
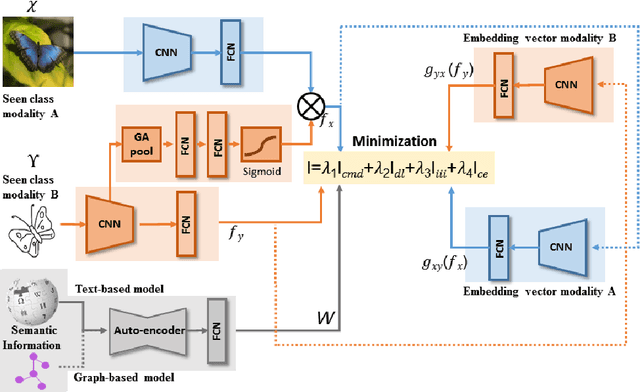
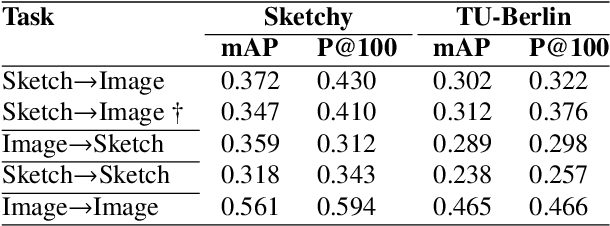
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
GuCNet: A Guided Clustering-based Network for Improved Classification
Oct 11, 2020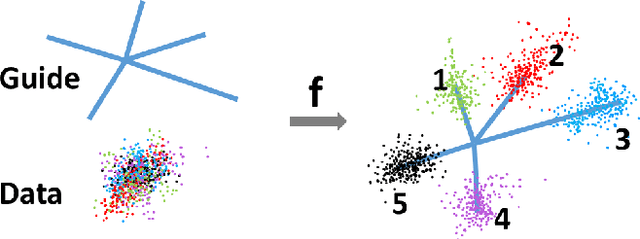
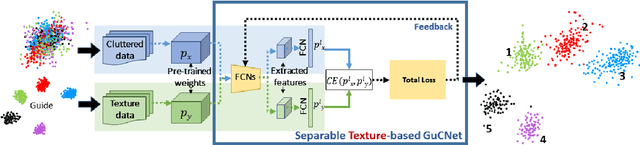
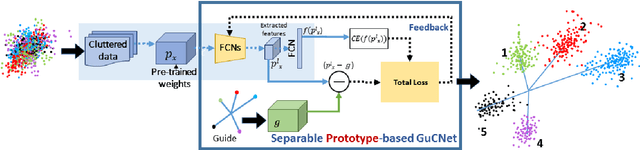

We deal with the problem of semantic classification of challenging and highly-cluttered dataset. We present a novel, and yet a very simple classification technique by leveraging the ease of classifiability of any existing well separable dataset for guidance. Since the guide dataset which may or may not have any semantic relationship with the experimental dataset, forms well separable clusters in the feature set, the proposed network tries to embed class-wise features of the challenging dataset to those distinct clusters of the guide set, making them more separable. Depending on the availability, we propose two types of guide sets: one using texture (image) guides and another using prototype vectors representing cluster centers. Experimental results obtained on the challenging benchmark RSSCN, LSUN, and TU-Berlin datasets establish the efficacy of the proposed method as we outperform the existing state-of-the-art techniques by a considerable margin.
A Zero-Shot Sketch-based Inter-Modal Object Retrieval Scheme for Remote Sensing Images
Aug 12, 2020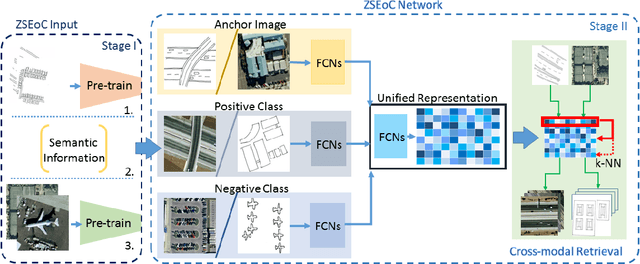
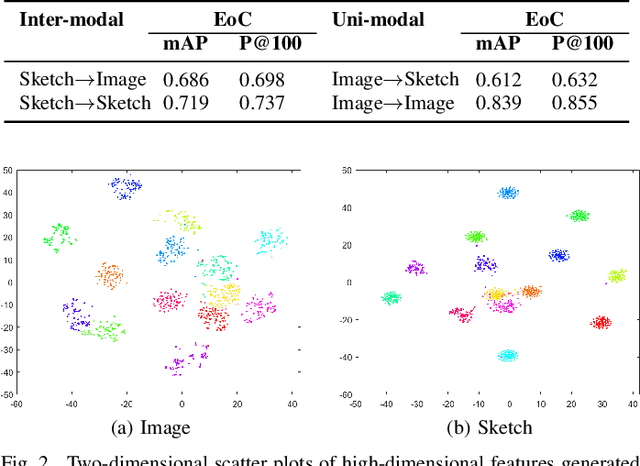
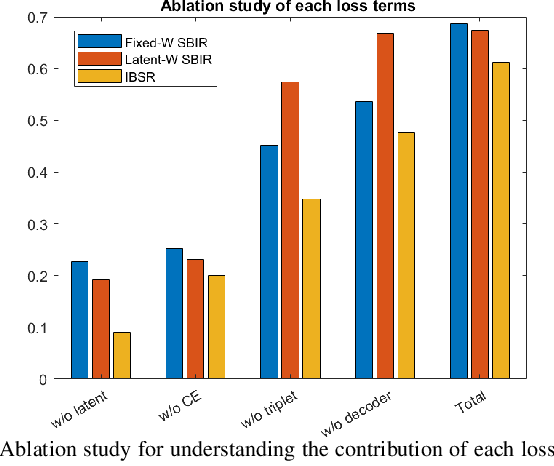

Conventional existing retrieval methods in remote sensing (RS) are often based on a uni-modal data retrieval framework. In this work, we propose a novel inter-modal triplet-based zero-shot retrieval scheme utilizing a sketch-based representation of RS data. The proposed scheme performs efficiently even when the sketch representations are marginally prototypical of the image. We conducted experiments on a new bi-modal image-sketch dataset called Earth on Canvas (EoC) conceived during this study. We perform a thorough bench-marking of this dataset and demonstrate that the proposed network outperforms other state-of-the-art methods for zero-shot sketch-based retrieval framework in remote sensing.
CMIR-NET : A Deep Learning Based Model For Cross-Modal Retrieval In Remote Sensing
May 24, 2019
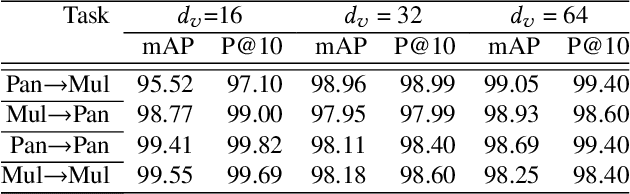
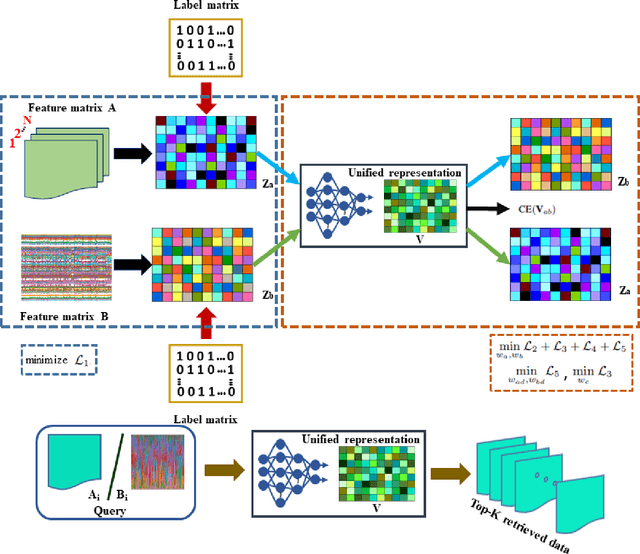
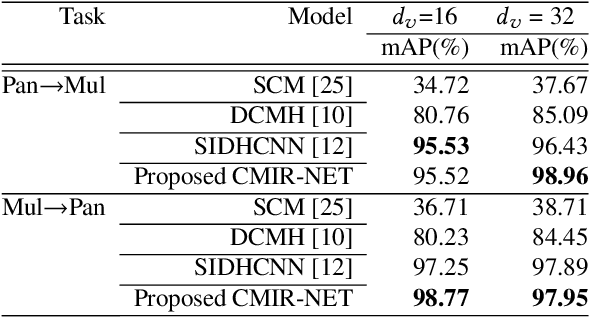
We address the problem of cross-modal information retrieval in the domain of remote sensing. In particular, we are interested in two application scenarios: i) cross-modal retrieval between panchromatic (PAN) and multi-spectral imagery, and ii) multi-label image retrieval between very high resolution (VHR) images and speech based label annotations. Notice that these multi-modal retrieval scenarios are more challenging than the traditional uni-modal retrieval approaches given the inherent differences in distributions between the modalities. However, with the growing availability of multi-source remote sensing data and the scarcity of enough semantic annotations, the task of multi-modal retrieval has recently become extremely important. In this regard, we propose a novel deep neural network based architecture which is considered to learn a discriminative shared feature space for all the input modalities, suitable for semantically coherent information retrieval. Extensive experiments are carried out on the benchmark large-scale PAN - multi-spectral DSRSID dataset and the multi-label UC-Merced dataset. Together with the Merced dataset, we generate a corpus of speech signals corresponding to the labels. Superior performance with respect to the current state-of-the-art is observed in all the cases.
Efficient Retrieval of Logos Using Rough Set Reducts
Apr 10, 2019

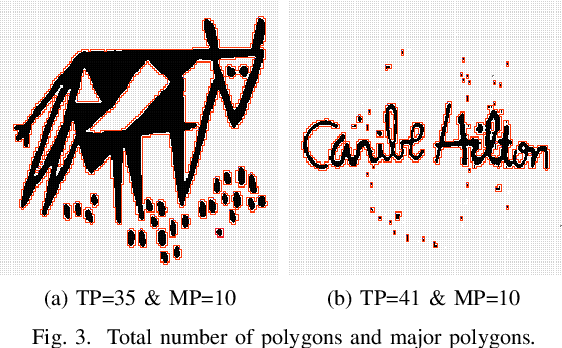

Searching for similar logos in the registered logo database is a very important and tedious task at the trademark office. Speed and accuracy are two aspects that one must attend to while developing a system for retrieval of logos. In this paper, we propose a rough-set based method to quantify the structural information in a logo image that can be used to efficiently index an image. A logo is split into a number of polygons, and for each polygon, we compute the tight upper and lower approximations based on the principles of a rough set. This representation is used for forming feature vectors for retrieval of logos. Experimentation on a standard data set shows the usefulness of the proposed technique. It is computationally efficient and also provides retrieval results at high accuracy.