 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCMIR-NET : A Deep Learning Based Model For Cross-Modal Retrieval In Remote Sensing
Paper and Code

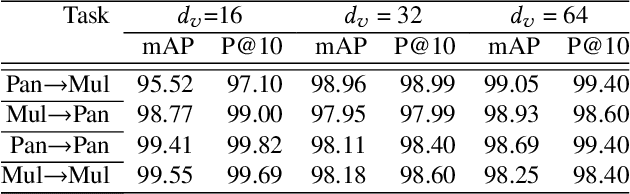
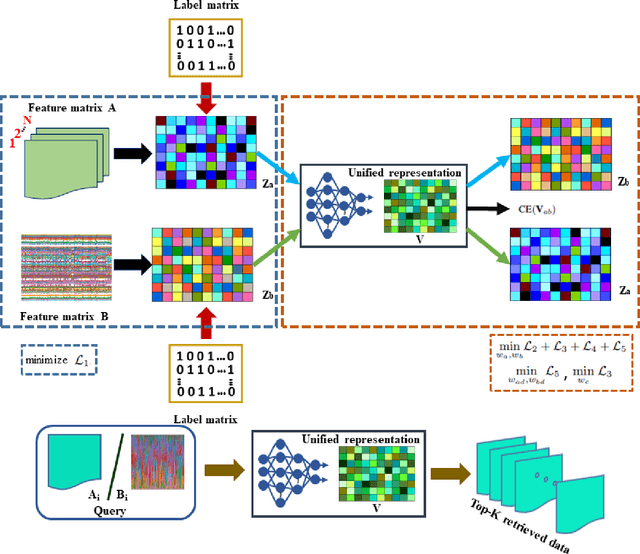
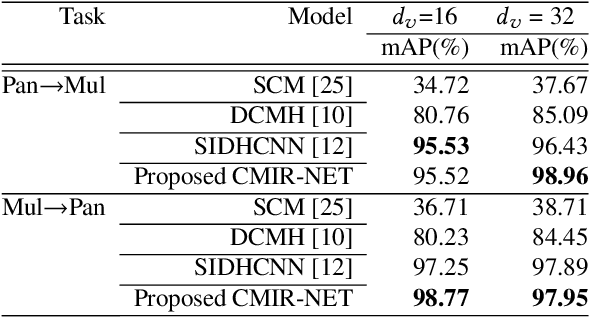
We address the problem of cross-modal information retrieval in the domain of remote sensing. In particular, we are interested in two application scenarios: i) cross-modal retrieval between panchromatic (PAN) and multi-spectral imagery, and ii) multi-label image retrieval between very high resolution (VHR) images and speech based label annotations. Notice that these multi-modal retrieval scenarios are more challenging than the traditional uni-modal retrieval approaches given the inherent differences in distributions between the modalities. However, with the growing availability of multi-source remote sensing data and the scarcity of enough semantic annotations, the task of multi-modal retrieval has recently become extremely important. In this regard, we propose a novel deep neural network based architecture which is considered to learn a discriminative shared feature space for all the input modalities, suitable for semantically coherent information retrieval. Extensive experiments are carried out on the benchmark large-scale PAN - multi-spectral DSRSID dataset and the multi-label UC-Merced dataset. Together with the Merced dataset, we generate a corpus of speech signals corresponding to the labels. Superior performance with respect to the current state-of-the-art is observed in all the cases.