 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeArcGate: Adaptive Arctangent Gated Activation
May 14, 2026Activation functions are central to deep networks, influencing non-linearity, feature learning, convergence, and robustness. This paper proposes the Adaptive Arctangent Gated Activation (ArcGate) function, a flexible formulation that generates a broad spectrum of activation shapes via a three-stage non-linear transformation. Unlike conventional fixed-shape activations such as ReLU, GELU, or SiLU, ArcGate uses seven learnable parameters per layer, allowing the neural network to autonomously optimize its non-linearity to the specific requirements of the feature hierarchy and data distribution. We evaluate ArcGate using ResNet-50 and Vision Transformer (ViT-B/16) architectures on three widely used remote sensing benchmarks: PatternNet, UC Merced Land Use, and the 13-band EuroSAT MSI multispectral dataset. Experimental results show that ArcGate consistently outperforms standard baselines, achieving a peak overall accuracy of 99.67% on PatternNet. Most notably, ArcGate exhibits superior structural resilience in noisy environments, maintaining a 26.65% performance lead over ReLU under moderate Gaussian noise (standard deviation 0.1). Analysis of the learned parameters reveals a depth-dependent functional evolution, where the model increases gating strength in deeper layers to enhance signal propagation. These findings suggest that ArcGate is a robust and adaptive general node activation function for high-resolution earth observation tasks.
Joint Analysis of Optical and SAR Vegetation Indices for Vineyard Monitoring: Assessing Biomass Dynamics and Phenological Stages over Po Valley, Italy
Jun 16, 2025Multi-polarized Synthetic Aperture Radar (SAR) technology has gained increasing attention in agriculture, offering unique capabilities for monitoring vegetation dynamics thanks to its all-weather, day-and-night operation and high revisit frequency. This study presents, for the first time, a comprehensive analysis combining dual-polarimetric radar vegetation index (DpRVI) with optical indices to characterize vineyard crops. Vineyards exhibit distinct non-isotropic scattering behavior due to their pronounced row orientation, making them particularly challenging and interesting targets for remote sensing. The research further investigates the relationship between DpRVI and optical vegetation indices, demonstrating the complementary nature of their information. We demonstrate that DpRVI and optical indices provide complementary information, with low correlation suggesting that they capture distinct vineyard features. Key findings reveal a parabolic trend in DpRVI over the growing season, potentially linked to biomass dynamics estimated via the Winkler Index. Unlike optical indices reflecting vegetation greenness, DpRVI appears more directly related to biomass growth, aligning with specific phenological phases. Preliminary results also highlight the potential of DpRVI for distinguishing vineyards from other crops. This research aligns with the objectives of the PNRR-NODES project, which promotes nature-based solutions (NbS) for sustainable vineyard management. The application of DpRVI for monitoring vineyards is part of integrating remote sensing techniques into the broader field of strategies for climate-related change adaptation and risk reduction, emphasizing the role of innovative SAR-based monitoring in sustainable agriculture.
Efficient Curriculum based Continual Learning with Informative Subset Selection for Remote Sensing Scene Classification
Sep 03, 2023We tackle the problem of class incremental learning (CIL) in the realm of landcover classification from optical remote sensing (RS) images in this paper. The paradigm of CIL has recently gained much prominence given the fact that data are generally obtained in a sequential manner for real-world phenomenon. However, CIL has not been extensively considered yet in the domain of RS irrespective of the fact that the satellites tend to discover new classes at different geographical locations temporally. With this motivation, we propose a novel CIL framework inspired by the recent success of replay-memory based approaches and tackling two of their shortcomings. In order to reduce the effect of catastrophic forgetting of the old classes when a new stream arrives, we learn a curriculum of the new classes based on their similarity with the old classes. This is found to limit the degree of forgetting substantially. Next while constructing the replay memory, instead of randomly selecting samples from the old streams, we propose a sample selection strategy which ensures the selection of highly confident samples so as to reduce the effects of noise. We observe a sharp improvement in the CIL performance with the proposed components. Experimental results on the benchmark NWPU-RESISC45, PatternNet, and EuroSAT datasets confirm that our method offers improved stability-plasticity trade-off than the literature.
A Novel Multi-scale Attention Feature Extraction Block for Aerial Remote Sensing Image Classification
Aug 27, 2023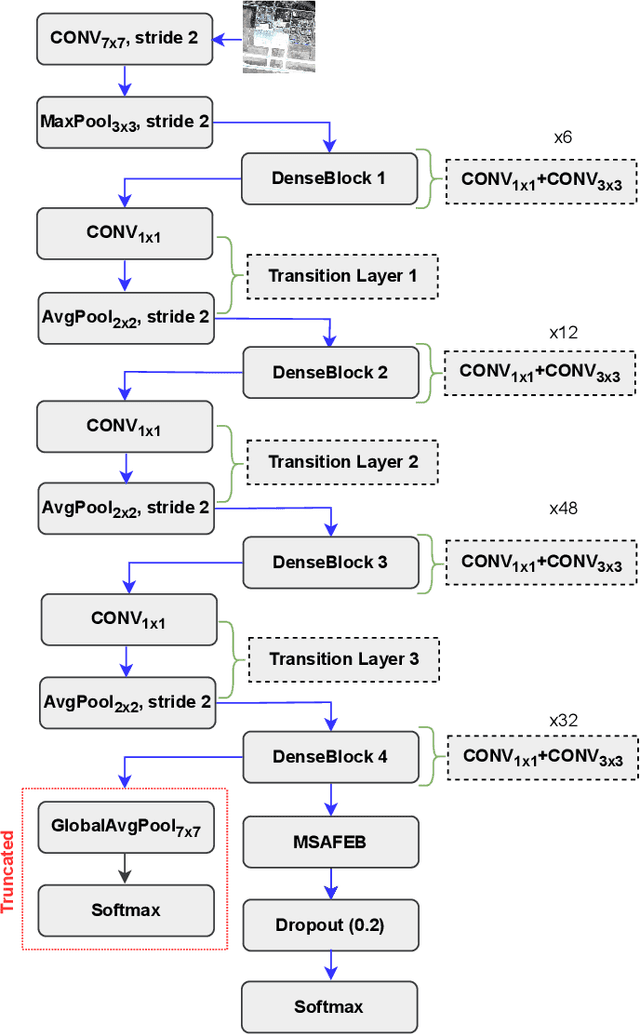
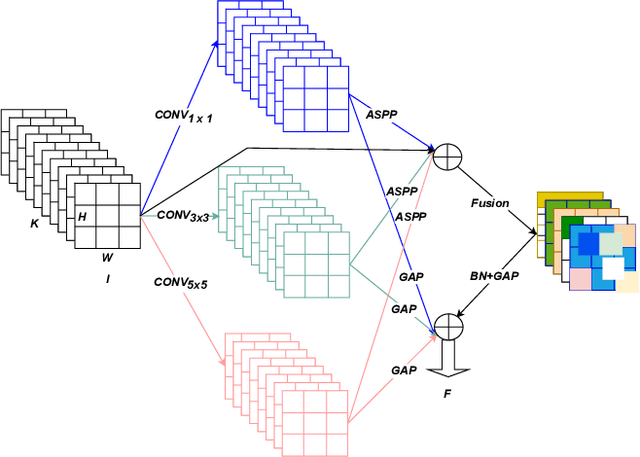

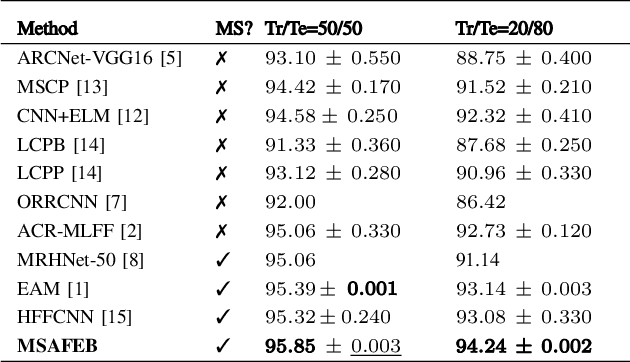
Classification of very high-resolution (VHR) aerial remote sensing (RS) images is a well-established research area in the remote sensing community as it provides valuable spatial information for decision-making. Existing works on VHR aerial RS image classification produce an excellent classification performance; nevertheless, they have a limited capability to well-represent VHR RS images having complex and small objects, thereby leading to performance instability. As such, we propose a novel plug-and-play multi-scale attention feature extraction block (MSAFEB) based on multi-scale convolution at two levels with skip connection, producing discriminative/salient information at a deeper/finer level. The experimental study on two benchmark VHR aerial RS image datasets (AID and NWPU) demonstrates that our proposal achieves a stable/consistent performance (minimum standard deviation of $0.002$) and competent overall classification performance (AID: 95.85\% and NWPU: 94.09\%).
CrossATNet - A Novel Cross-Attention Based Framework for Sketch-Based Image Retrieval
Apr 20, 2021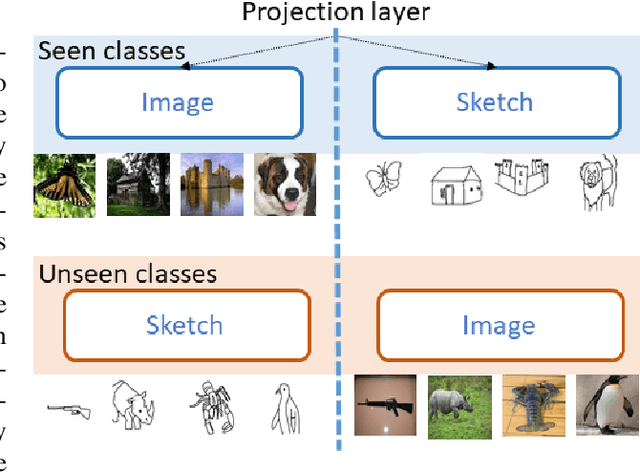
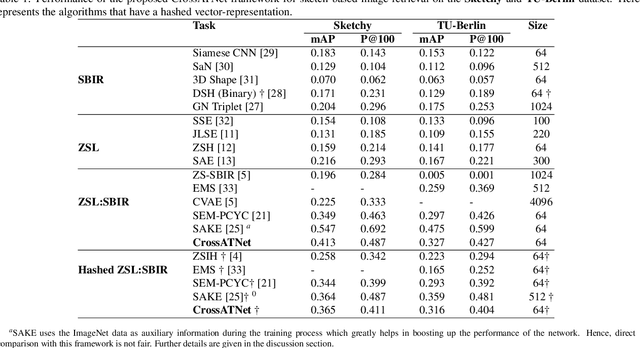
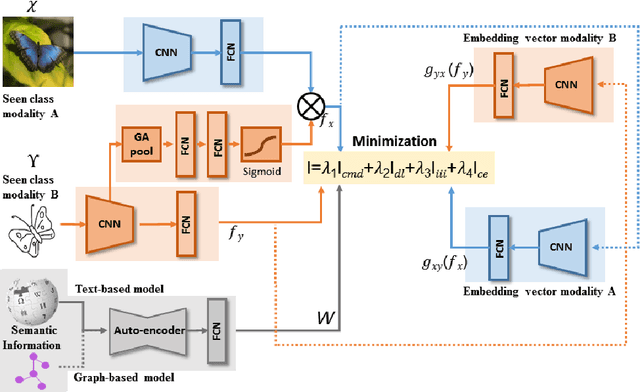
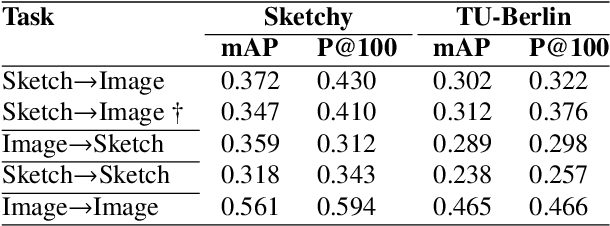
We propose a novel framework for cross-modal zero-shot learning (ZSL) in the context of sketch-based image retrieval (SBIR). Conventionally, the SBIR schema mainly considers simultaneous mappings among the two image views and the semantic side information. Therefore, it is desirable to consider fine-grained classes mainly in the sketch domain using highly discriminative and semantically rich feature space. However, the existing deep generative modeling-based SBIR approaches majorly focus on bridging the gaps between the seen and unseen classes by generating pseudo-unseen-class samples. Besides, violating the ZSL protocol by not utilizing any unseen-class information during training, such techniques do not pay explicit attention to modeling the discriminative nature of the shared space. Also, we note that learning a unified feature space for both the multi-view visual data is a tedious task considering the significant domain difference between sketches and color images. In this respect, as a remedy, we introduce a novel framework for zero-shot SBIR. While we define a cross-modal triplet loss to ensure the discriminative nature of the shared space, an innovative cross-modal attention learning strategy is also proposed to guide feature extraction from the image domain exploiting information from the respective sketch counterpart. In order to preserve the semantic consistency of the shared space, we consider a graph CNN-based module that propagates the semantic class topology to the shared space. To ensure an improved response time during inference, we further explore the possibility of representing the shared space in terms of hash codes. Experimental results obtained on the benchmark TU-Berlin and the Sketchy datasets confirm the superiority of CrossATNet in yielding state-of-the-art results.
A Zero-Shot Sketch-based Inter-Modal Object Retrieval Scheme for Remote Sensing Images
Aug 12, 2020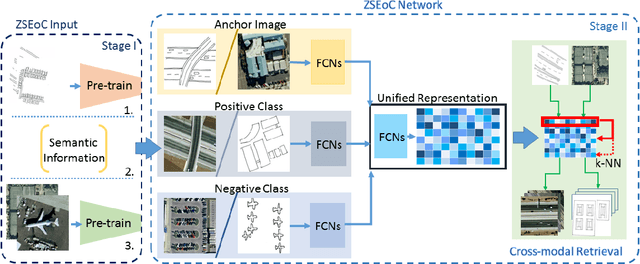
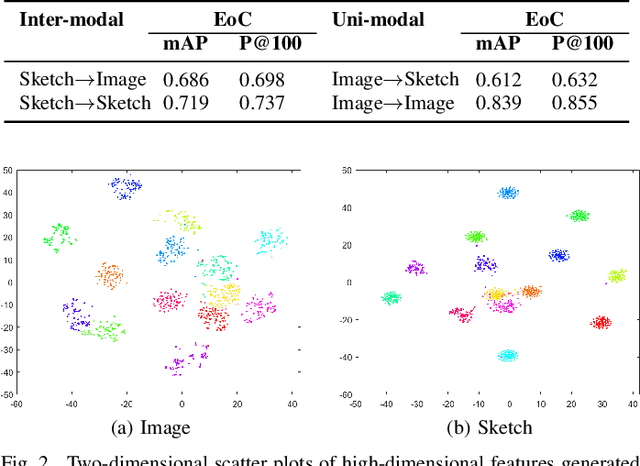

Conventional existing retrieval methods in remote sensing (RS) are often based on a uni-modal data retrieval framework. In this work, we propose a novel inter-modal triplet-based zero-shot retrieval scheme utilizing a sketch-based representation of RS data. The proposed scheme performs efficiently even when the sketch representations are marginally prototypical of the image. We conducted experiments on a new bi-modal image-sketch dataset called Earth on Canvas (EoC) conceived during this study. We perform a thorough bench-marking of this dataset and demonstrate that the proposed network outperforms other state-of-the-art methods for zero-shot sketch-based retrieval framework in remote sensing.
A PolSAR Scattering Power Factorization Framework and Novel Roll-Invariant Parameters Based Unsupervised Classification Scheme Using a Geodesic Distance
Jun 27, 2019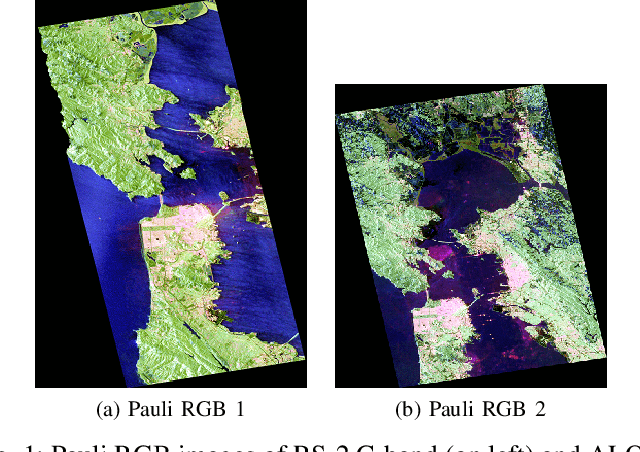


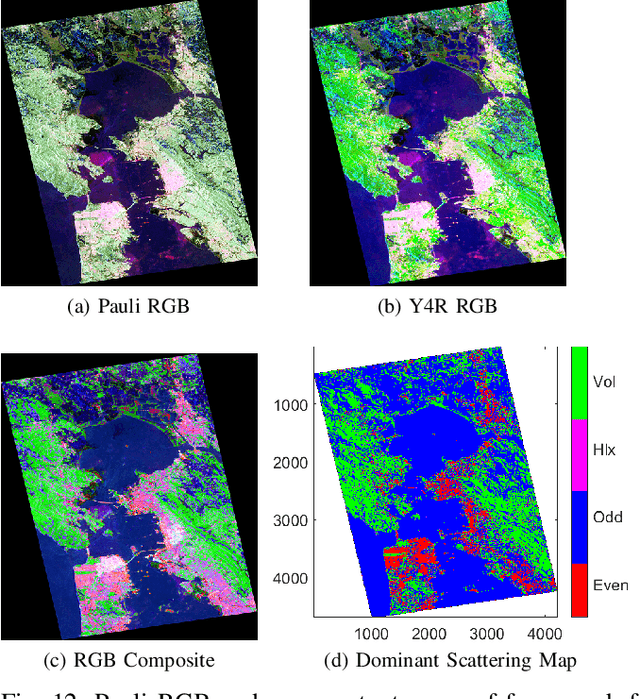
We propose a generic Scattering Power Factorization Framework (SPFF) for Polarimetric Synthetic Aperture Radar (PolSAR) data to directly obtain $N$ scattering power components along with a residue power component for each pixel. Each scattering power component is factorized into similarity (or dissimilarity) using elementary targets and a generalized random volume model. The similarity measure is derived using a geodesic distance between pairs of $4\times4$ real Kennaugh matrices. In standard model-based decomposition schemes, the $3\times3$ Hermitian positive semi-definite covariance (or coherency) matrix is expressed as a weighted linear combination of scattering targets following a fixed hierarchical process. In contrast, under the proposed framework, a convex splitting of unity is performed to obtain the weights while preserving the dominance of the scattering components. The product of the total power (Span) with these weights provides the non-negative scattering power components. Furthermore, the framework along the geodesic distance is effectively used to obtain specific roll-invariant parameters which are then utilized to design an unsupervised classification scheme. The SPFF, the roll invariant parameters, and the classification results are assessed using C-band RADARSAT-2 and L-band ALOS-2 images of San Francisco.
CMIR-NET : A Deep Learning Based Model For Cross-Modal Retrieval In Remote Sensing
May 24, 2019
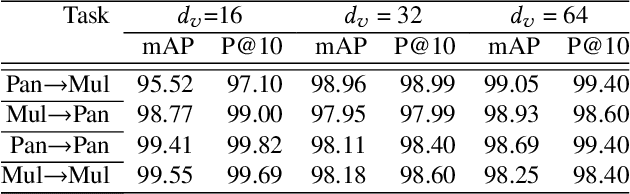
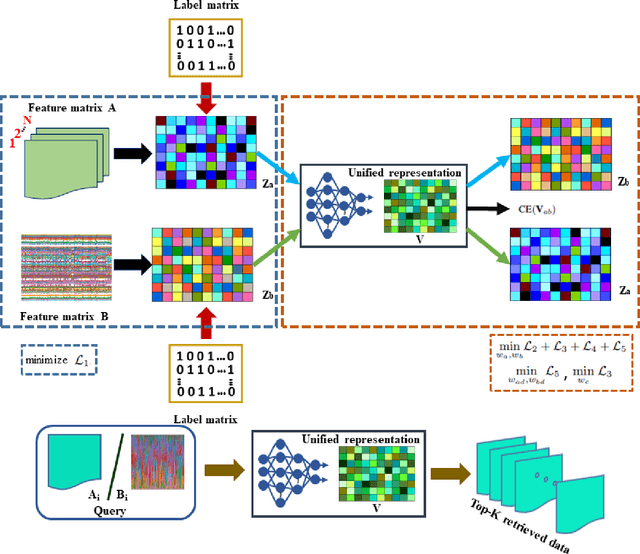
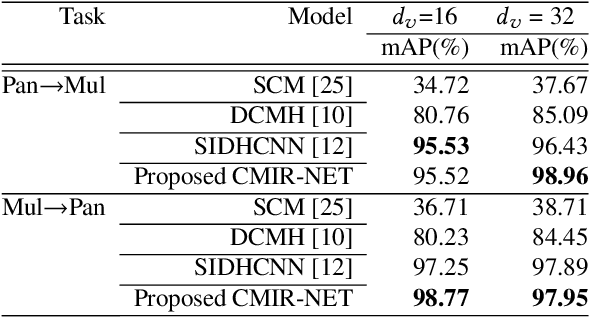
We address the problem of cross-modal information retrieval in the domain of remote sensing. In particular, we are interested in two application scenarios: i) cross-modal retrieval between panchromatic (PAN) and multi-spectral imagery, and ii) multi-label image retrieval between very high resolution (VHR) images and speech based label annotations. Notice that these multi-modal retrieval scenarios are more challenging than the traditional uni-modal retrieval approaches given the inherent differences in distributions between the modalities. However, with the growing availability of multi-source remote sensing data and the scarcity of enough semantic annotations, the task of multi-modal retrieval has recently become extremely important. In this regard, we propose a novel deep neural network based architecture which is considered to learn a discriminative shared feature space for all the input modalities, suitable for semantically coherent information retrieval. Extensive experiments are carried out on the benchmark large-scale PAN - multi-spectral DSRSID dataset and the multi-label UC-Merced dataset. Together with the Merced dataset, we generate a corpus of speech signals corresponding to the labels. Superior performance with respect to the current state-of-the-art is observed in all the cases.
Unsupervised Classification of PolSAR Data Using a Scattering Similarity Measure Derived from a Geodesic Distance
Dec 01, 2017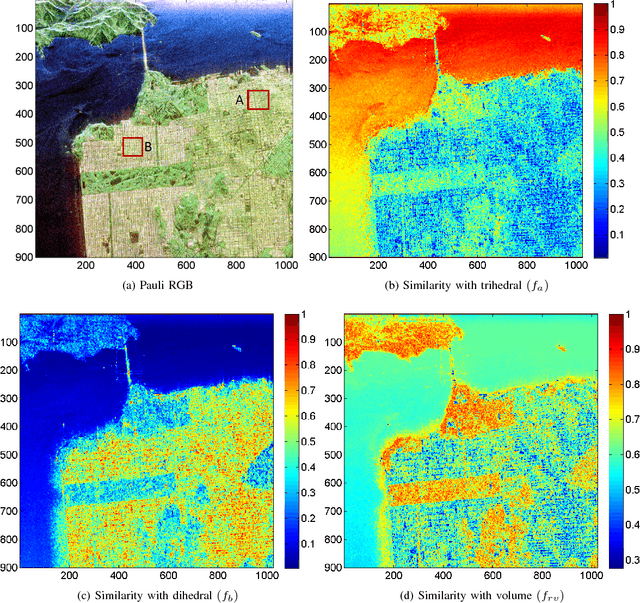
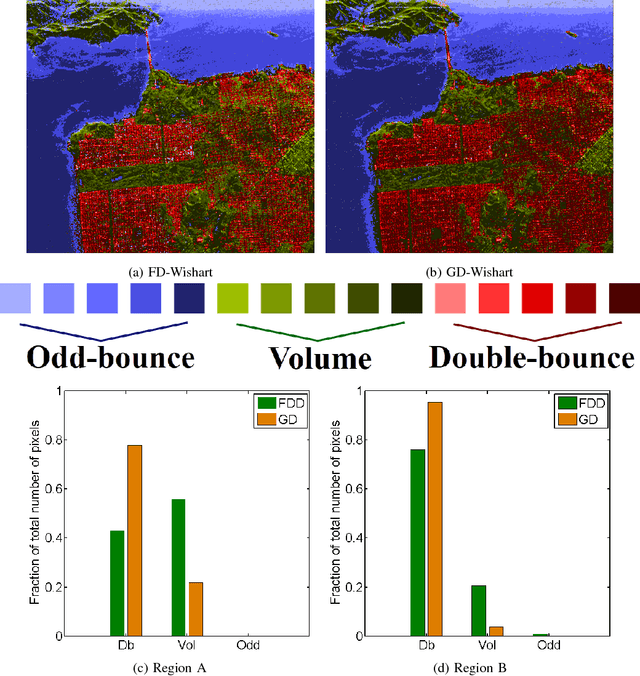

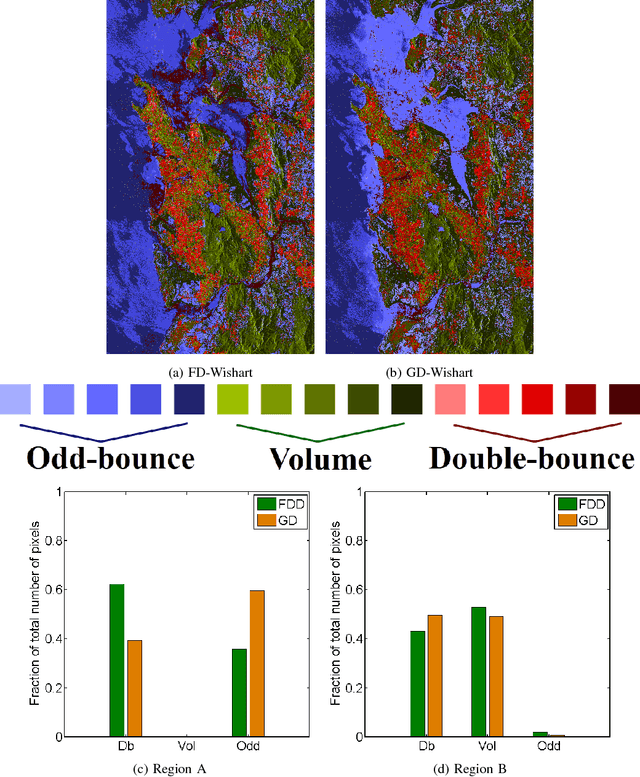
In this letter, we propose a novel technique for obtaining scattering components from Polarimetric Synthetic Aperture Radar (PolSAR) data using the geodesic distance on the unit sphere. This geodesic distance is obtained between an elementary target and the observed Kennaugh matrix, and it is further utilized to compute a similarity measure between scattering mechanisms. The normalized similarity measure for each elementary target is then modulated with the total scattering power (Span). This measure is used to categorize pixels into three categories i.e. odd-bounce, double-bounce and volume, depending on which of the above scattering mechanisms dominate. Then the maximum likelihood classifier of [J.-S. Lee, M. R. Grunes, E. Pottier, and L. Ferro-Famil, Unsupervised terrain classification preserving polarimetric scattering characteristics, IEEE Trans. Geos. Rem. Sens., vol. 42, no. 4, pp. 722731, April 2004.] based on the complex Wishart distribution is iteratively used for each category. Dominant scattering mechanisms are thus preserved in this classification scheme. We show results for L-band AIRSAR and ALOS-2 datasets acquired over San Francisco and Mumbai, respectively. The scattering mechanisms are better preserved using the proposed methodology than the unsupervised classification results using the Freeman-Durden scattering powers on an orientation angle (OA) corrected PolSAR image. Furthermore, (1) the scattering similarity is a completely non-negative quantity unlike the negative powers that might occur in double- bounce and odd-bounce scattering component under Freeman Durden decomposition (FDD), and (2) the methodology can be extended to more canonical targets as well as for bistatic scattering.