 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Learning for Assessment of Oral Reading Fluency
Jun 01, 2024Reading fluency assessment is a critical component of literacy programmes, serving to guide and monitor early education interventions. Given the resource intensive nature of the exercise when conducted by teachers, the development of automatic tools that can operate on audio recordings of oral reading is attractive as an objective and highly scalable solution. Multiple complex aspects such as accuracy, rate and expressiveness underlie human judgements of reading fluency. In this work, we investigate end-to-end modeling on a training dataset of children's audio recordings of story texts labeled by human experts. The pre-trained wav2vec2.0 model is adopted due its potential to alleviate the challenges from the limited amount of labeled data. We report the performance of a number of system variations on the relevant measures, and also probe the learned embeddings for lexical and acoustic-prosodic features known to be important to the perception of reading fluency.
Deep Learning For Prominence Detection In Children's Read Speech
Oct 27, 2021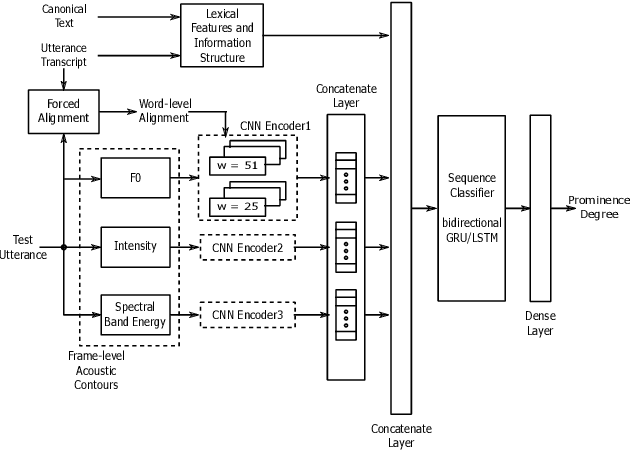
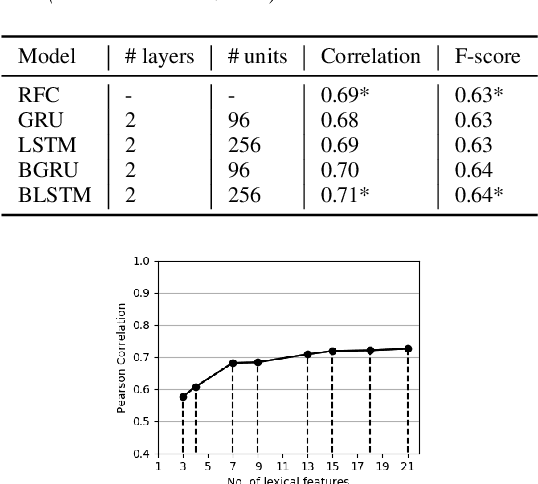
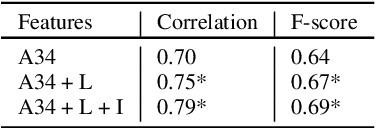
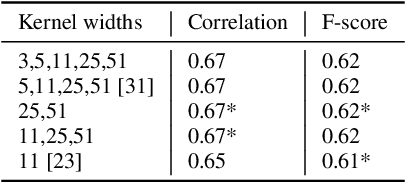
The detection of perceived prominence in speech has attracted approaches ranging from the design of linguistic knowledge-based acoustic features to the automatic feature learning from suprasegmental attributes such as pitch and intensity contours. We present here, in contrast, a system that operates directly on segmented speech waveforms to learn features relevant to prominent word detection for children's oral fluency assessment. The chosen CRNN (convolutional recurrent neural network) framework, incorporating both word-level features and sequence information, is found to benefit from the perceptually motivated SincNet filters as the first convolutional layer. We further explore the benefits of the linguistic association between the prosodic events of phrase boundary and prominence with different multi-task architectures. Matching the previously reported performance on the same dataset of a random forest ensemble predictor trained on carefully chosen hand-crafted acoustic features, we evaluate further the possibly complementary information from hand-crafted acoustic and pre-trained lexical features.