 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFew-shot Acoustic Synthesis with Multimodal Flow Matching
Mar 19, 2026Generating audio that is acoustically consistent with a scene is essential for immersive virtual environments. Recent neural acoustic field methods enable spatially continuous sound rendering but remain scene-specific, requiring dense audio measurements and costly training for each environment. Few-shot approaches improve scalability across rooms but still rely on multiple recordings and, being deterministic, fail to capture the inherent uncertainty of scene acoustics under sparse context. We introduce flow-matching acoustic generation (FLAC), a probabilistic method for few-shot acoustic synthesis that models the distribution of plausible room impulse responses (RIRs) given minimal scene context. FLAC leverages a diffusion transformer trained with a flow-matching objective to generate RIRs at arbitrary positions in novel scenes, conditioned on spatial, geometric, and acoustic cues. FLAC outperforms state-of-the-art eight-shot baselines with one-shot on both the AcousticRooms and Hearing Anything Anywhere datasets. To complement standard perceptual metrics, we further introduce AGREE, a joint acoustic-geometry embedding, enabling geometry-consistent evaluation of generated RIRs through retrieval and distributional metrics. This work is the first to apply generative flow matching to explicit RIR synthesis, establishing a new direction for robust and data-efficient acoustic synthesis.
One Wave to Explain Them All: A Unifying Perspective on Post-hoc Explainability
Oct 02, 2024Despite the growing use of deep neural networks in safety-critical decision-making, their inherent black-box nature hinders transparency and interpretability. Explainable AI (XAI) methods have thus emerged to understand a model's internal workings, and notably attribution methods also called saliency maps. Conventional attribution methods typically identify the locations -- the where -- of significant regions within an input. However, because they overlook the inherent structure of the input data, these methods often fail to interpret what these regions represent in terms of structural components (e.g., textures in images or transients in sounds). Furthermore, existing methods are usually tailored to a single data modality, limiting their generalizability. In this paper, we propose leveraging the wavelet domain as a robust mathematical foundation for attribution. Our approach, the Wavelet Attribution Method (WAM) extends the existing gradient-based feature attributions into the wavelet domain, providing a unified framework for explaining classifiers across images, audio, and 3D shapes. Empirical evaluations demonstrate that WAM matches or surpasses state-of-the-art methods across faithfulness metrics and models in image, audio, and 3D explainability. Finally, we show how our method explains not only the where -- the important parts of the input -- but also the what -- the relevant patterns in terms of structural components.
NeRAF: 3D Scene Infused Neural Radiance and Acoustic Fields
May 28, 2024Sound plays a major role in human perception, providing essential scene information alongside vision for understanding our environment. Despite progress in neural implicit representations, learning acoustics that match a visual scene is still challenging. We propose NeRAF, a method that jointly learns acoustic and radiance fields. NeRAF is designed as a Nerfstudio module for convenient access to realistic audio-visual generation. It synthesizes both novel views and spatialized audio at new positions, leveraging radiance field capabilities to condition the acoustic field with 3D scene information. At inference, each modality can be rendered independently and at spatially separated positions, providing greater versatility. We demonstrate the advantages of our method on the SoundSpaces dataset. NeRAF achieves substantial performance improvements over previous works while being more data-efficient. Furthermore, NeRAF enhances novel view synthesis of complex scenes trained with sparse data through cross-modal learning.
The Audio-Visual BatVision Dataset for Research on Sight and Sound
Mar 14, 2023

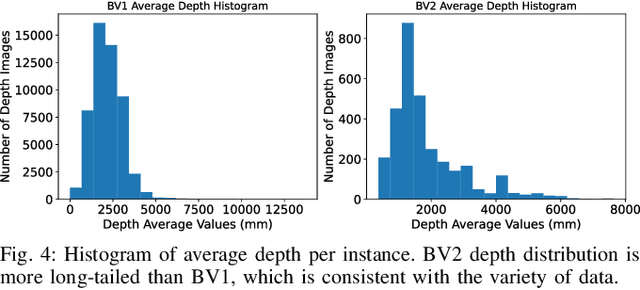
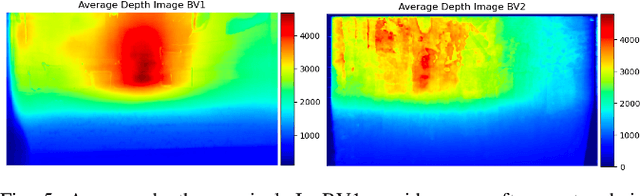
Vision research showed remarkable success in understanding our world, propelled by datasets of images and videos. Sensor data from radar, LiDAR and cameras supports research in robotics and autonomous driving for at least a decade. However, while visual sensors may fail in some conditions, sound has recently shown potential to complement sensor data. Simulated room impulse responses (RIR) in 3D apartment-models became a benchmark dataset for the community, fostering a range of audiovisual research. In simulation, depth is predictable from sound, by learning bat-like perception with a neural network. Concurrently, the same was achieved in reality by using RGB-D images and echoes of chirping sounds. Biomimicking bat perception is an exciting new direction but needs dedicated datasets to explore the potential. Therefore, we collected the BatVision dataset to provide large-scale echoes in complex real-world scenes to the community. We equipped a robot with a speaker to emit chirps and a binaural microphone to record their echoes. Synchronized RGB-D images from the same perspective provide visual labels of traversed spaces. We sampled modern US office spaces to historic French university grounds, indoor and outdoor with large architectural variety. This dataset will allow research on robot echolocation, general audio-visual tasks and sound phaenomena unavailable in simulated data. We show promising results for audio-only depth prediction and show how state-of-the-art work developed for simulated data can also succeed on our dataset. The data can be downloaded at https://forms.gle/W6xtshMgoXGZDwsE7