 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Map Compression through Tensor Decomposition for Deep Learning
Nov 10, 2024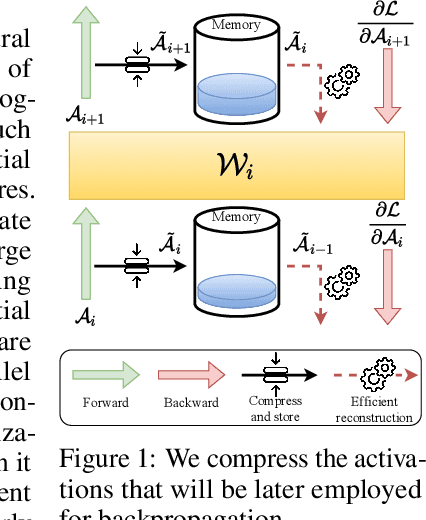

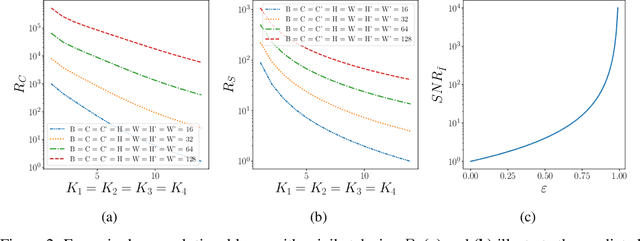

Internet of Things and Deep Learning are synergetically and exponentially growing industrial fields with a massive call for their unification into a common framework called Edge AI. While on-device inference is a well-explored topic in recent research, backpropagation remains an open challenge due to its prohibitive computational and memory costs compared to the extreme resource constraints of embedded devices. Drawing on tensor decomposition research, we tackle the main bottleneck of backpropagation, namely the memory footprint of activation map storage. We investigate and compare the effects of activation compression using Singular Value Decomposition and its tensor variant, High-Order Singular Value Decomposition. The application of low-order decomposition results in considerable memory savings while preserving the features essential for learning, and also offers theoretical guarantees to convergence. Experimental results obtained on main-stream architectures and tasks demonstrate Pareto-superiority over other state-of-the-art solutions, in terms of the trade-off between generalization and memory footprint.
Towards On-device Learning on the Edge: Ways to Select Neurons to Update under a Budget Constraint
Dec 08, 2023



In the realm of efficient on-device learning under extreme memory and computation constraints, a significant gap in successful approaches persists. Although considerable effort has been devoted to efficient inference, the main obstacle to efficient learning is the prohibitive cost of backpropagation. The resources required to compute gradients and update network parameters often exceed the limits of tightly constrained memory budgets. This paper challenges conventional wisdom and proposes a series of experiments that reveal the existence of superior sub-networks. Furthermore, we hint at the potential for substantial gains through a dynamic neuron selection strategy when fine-tuning a target task. Our efforts extend to the adaptation of a recent dynamic neuron selection strategy pioneered by Bragagnolo et al. (NEq), revealing its effectiveness in the most stringent scenarios. Our experiments demonstrate, in the average case, the superiority of a NEq-inspired approach over a random selection. This observation prompts a compelling avenue for further exploration in the area, highlighting the opportunity to design a new class of algorithms designed to facilitate parameter update selection. Our findings usher in a new era of possibilities in the field of on-device learning under extreme constraints and encourage the pursuit of innovative strategies for efficient, resource-friendly model fine-tuning.