 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHFMCA: Orthonormal Feature Learning for EEG-based Brain Decoding
Feb 04, 2026Electroencephalography (EEG) analysis is critical for brain-computer interfaces and neuroscience, but the intrinsic noise and high dimensionality of EEG signals hinder effective feature learning. We propose a self-supervised framework based on the Hierarchical Functional Maximal Correlation Algorithm (HFMCA), which learns orthonormal EEG representations by enforcing feature decorrelation and reducing redundancy. This design enables robust capture of essential brain dynamics for various EEG recognition tasks. We validate HFMCA on two benchmark datasets, SEED and BCIC-2A, where pretraining with HFMCA consistently outperforms competitive self-supervised baselines, achieving notable gains in classification accuracy. Across diverse EEG tasks, our method demonstrates superior cross-subject generalization under leave-one-subject-out validation, advancing state-of-the-art by 2.71\% on SEED emotion recognition and 2.57\% on BCIC-2A motor imagery classification.
Beyond Low-rank Decomposition: A Shortcut Approach for Efficient On-Device Learning
May 08, 2025On-device learning has emerged as a promising direction for AI development, particularly because of its potential to reduce latency issues and mitigate privacy risks associated with device-server communication, while improving energy efficiency. Despite these advantages, significant memory and computational constraints still represent major challenges for its deployment. Drawing on previous studies on low-rank decomposition methods that address activation memory bottlenecks in backpropagation, we propose a novel shortcut approach as an alternative. Our analysis and experiments demonstrate that our method can reduce activation memory usage, even up to $120.09\times$ compared to vanilla training, while also reducing overall training FLOPs up to $1.86\times$ when evaluated on traditional benchmarks.
Till the Layers Collapse: Compressing a Deep Neural Network through the Lenses of Batch Normalization Layers
Dec 19, 2024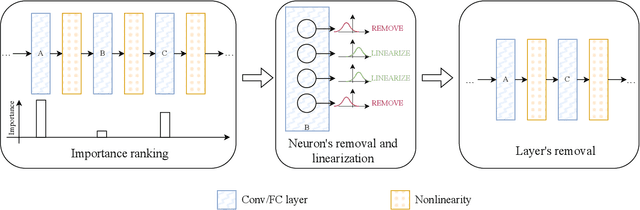
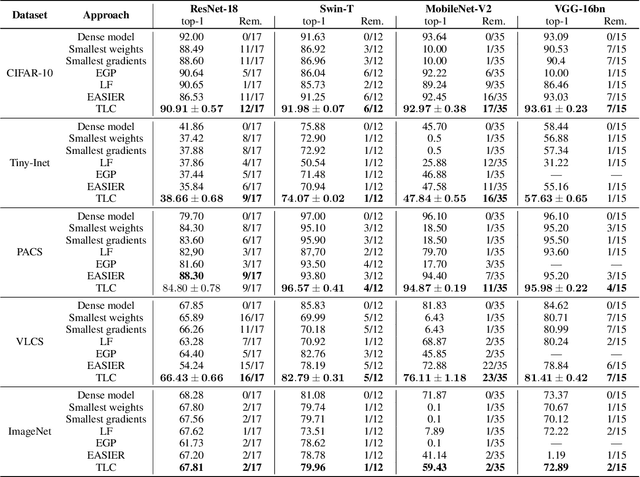
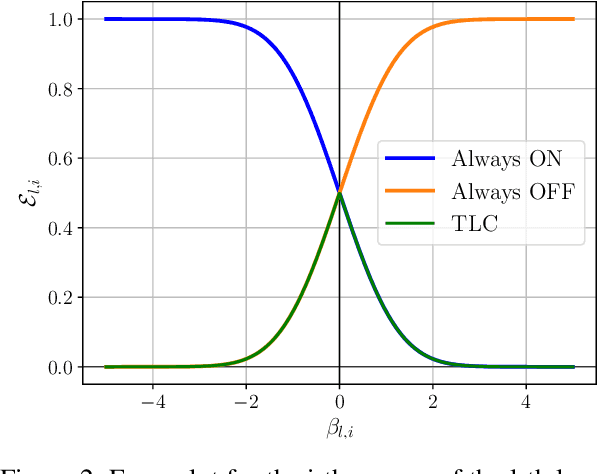
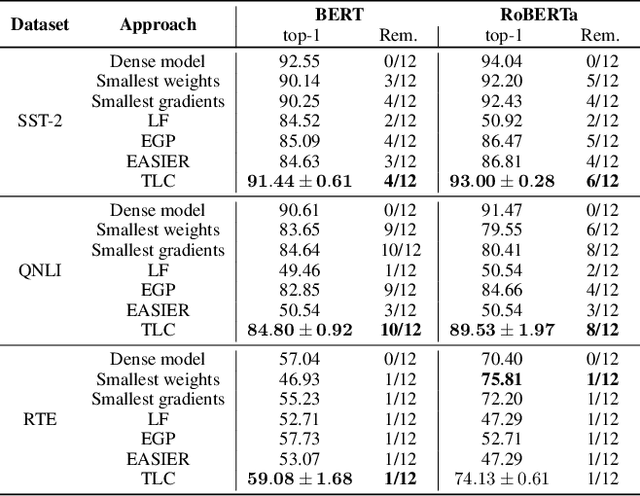
Today, deep neural networks are widely used since they can handle a variety of complex tasks. Their generality makes them very powerful tools in modern technology. However, deep neural networks are often overparameterized. The usage of these large models consumes a lot of computation resources. In this paper, we introduce a method called \textbf{T}ill the \textbf{L}ayers \textbf{C}ollapse (TLC), which compresses deep neural networks through the lenses of batch normalization layers. By reducing the depth of these networks, our method decreases deep neural networks' computational requirements and overall latency. We validate our method on popular models such as Swin-T, MobileNet-V2, and RoBERTa, across both image classification and natural language processing (NLP) tasks.
Activation Map Compression through Tensor Decomposition for Deep Learning
Nov 10, 2024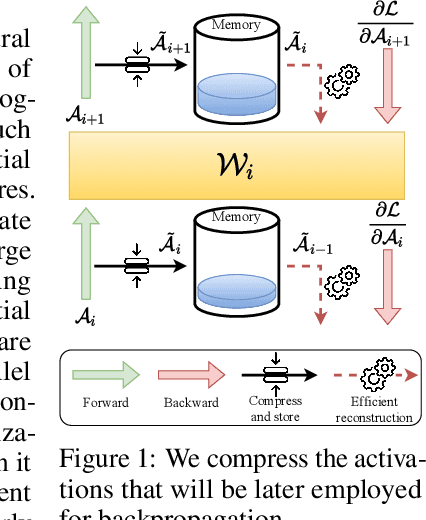

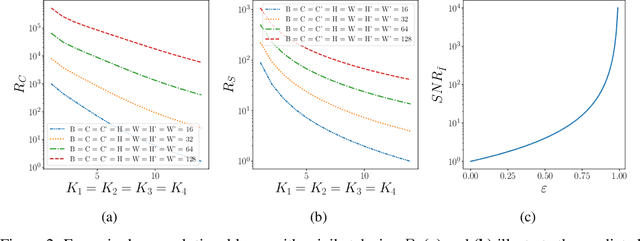

Internet of Things and Deep Learning are synergetically and exponentially growing industrial fields with a massive call for their unification into a common framework called Edge AI. While on-device inference is a well-explored topic in recent research, backpropagation remains an open challenge due to its prohibitive computational and memory costs compared to the extreme resource constraints of embedded devices. Drawing on tensor decomposition research, we tackle the main bottleneck of backpropagation, namely the memory footprint of activation map storage. We investigate and compare the effects of activation compression using Singular Value Decomposition and its tensor variant, High-Order Singular Value Decomposition. The application of low-order decomposition results in considerable memory savings while preserving the features essential for learning, and also offers theoretical guarantees to convergence. Experimental results obtained on main-stream architectures and tasks demonstrate Pareto-superiority over other state-of-the-art solutions, in terms of the trade-off between generalization and memory footprint.
Memory-Optimized Once-For-All Network
Sep 05, 2024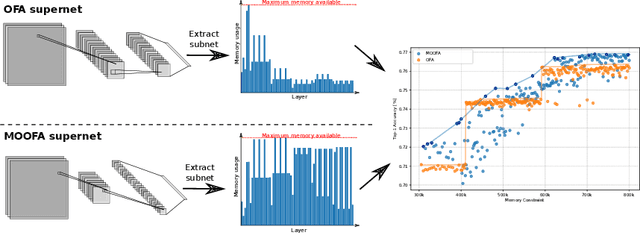



Deploying Deep Neural Networks (DNNs) on different hardware platforms is challenging due to varying resource constraints. Besides handcrafted approaches aiming at making deep models hardware-friendly, Neural Architectures Search is rising as a toolbox to craft more efficient DNNs without sacrificing performance. Among these, the Once-For-All (OFA) approach offers a solution by allowing the sampling of well-performing sub-networks from a single supernet -- this leads to evident advantages in terms of computation. However, OFA does not fully utilize the potential memory capacity of the target device, focusing instead on limiting maximum memory usage per layer. This leaves room for an unexploited potential in terms of model generalizability. In this paper, we introduce a Memory-Optimized OFA (MOOFA) supernet, designed to enhance DNN deployment on resource-limited devices by maximizing memory usage (and for instance, features diversity) across different configurations. Tested on ImageNet, our MOOFA supernet demonstrates improvements in memory exploitation and model accuracy compared to the original OFA supernet. Our code is available at https://github.com/MaximeGirard/memory-optimized-once-for-all.
AI-Driven Intrusion Detection Systems (IDS) on the ROAD dataset: A Comparative Analysis for automotive Controller Area Network (CAN)
Aug 30, 2024



The integration of digital devices in modern vehicles has revolutionized automotive technology, enhancing safety and the overall driving experience. The Controller Area Network (CAN) bus is a central system for managing in-vehicle communication between the electronic control units (ECUs). However, the CAN protocol poses security challenges due to inherent vulnerabilities, lacking encryption and authentication, which, combined with an expanding attack surface, necessitates robust security measures. In response to this challenge, numerous Intrusion Detection Systems (IDS) have been developed and deployed. Nonetheless, an open, comprehensive, and realistic dataset to test the effectiveness of such IDSs remains absent in the existing literature. This paper addresses this gap by considering the latest ROAD dataset, containing stealthy and sophisticated injections. The methodology involves dataset labelling and the implementation of both state-of-the-art deep learning models and traditional machine learning models to show the discrepancy in performance between the datasets most commonly used in the literature and the ROAD dataset, a more realistic alternative.
NEPENTHE: Entropy-Based Pruning as a Neural Network Depth's Reducer
Apr 24, 2024



While deep neural networks are highly effective at solving complex tasks, their computational demands can hinder their usefulness in real-time applications and with limited-resources systems. Besides, for many tasks it is known that these models are over-parametrized: neoteric works have broadly focused on reducing the width of these networks, rather than their depth. In this paper, we aim to reduce the depth of over-parametrized deep neural networks: we propose an eNtropy-basEd Pruning as a nEural Network depTH's rEducer (NEPENTHE) to alleviate deep neural networks' computational burden. Based on our theoretical finding, NEPENTHE focuses on un-structurally pruning connections in layers with low entropy to remove them entirely. We validate our approach on popular architectures such as MobileNet and Swin-T, showing that when encountering an over-parametrization regime, it can effectively linearize some layers (hence reducing the model's depth) with little to no performance loss. The code will be publicly available upon acceptance of the article.
Debiasing surgeon: fantastic weights and how to find them
Mar 21, 2024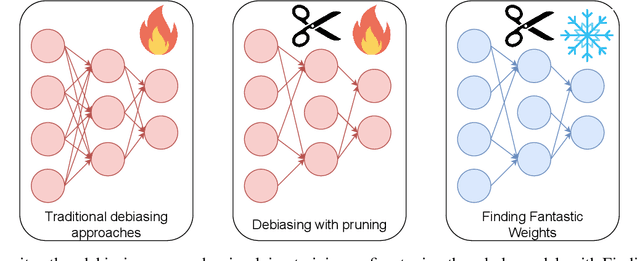

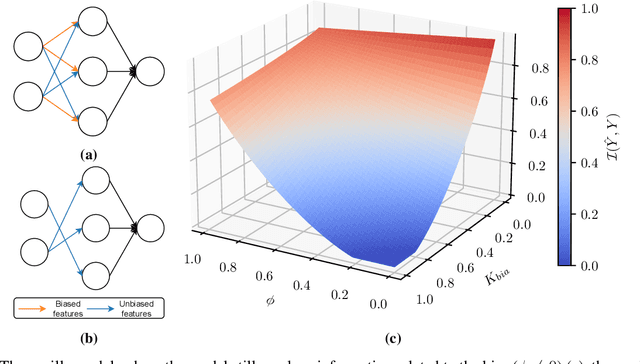
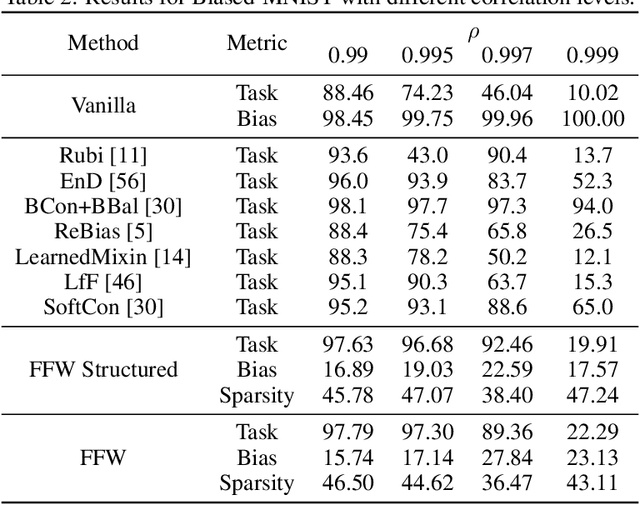
Nowadays an ever-growing concerning phenomenon, the emergence of algorithmic biases that can lead to unfair models, emerges. Several debiasing approaches have been proposed in the realm of deep learning, employing more or less sophisticated approaches to discourage these models from massively employing these biases. However, a question emerges: is this extra complexity really necessary? Is a vanilla-trained model already embodying some ``unbiased sub-networks'' that can be used in isolation and propose a solution without relying on the algorithmic biases? In this work, we show that such a sub-network typically exists, and can be extracted from a vanilla-trained model without requiring additional training. We further validate that such specific architecture is incapable of learning a specific bias, suggesting that there are possible architectural countermeasures to the problem of biases in deep neural networks.
SCoTTi: Save Computation at Training Time with an adaptive framework
Dec 19, 2023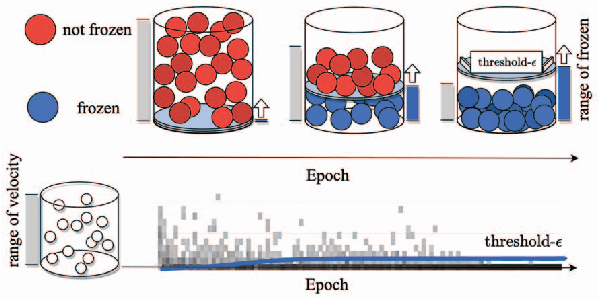
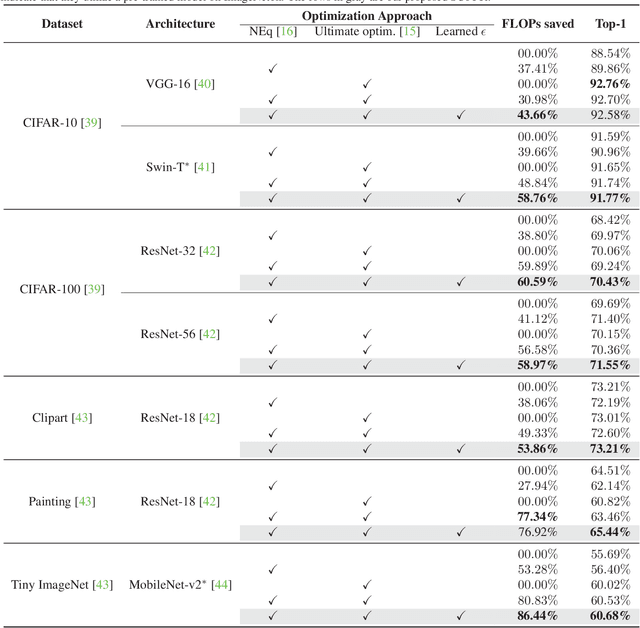
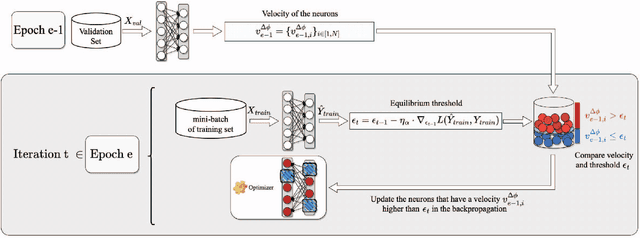
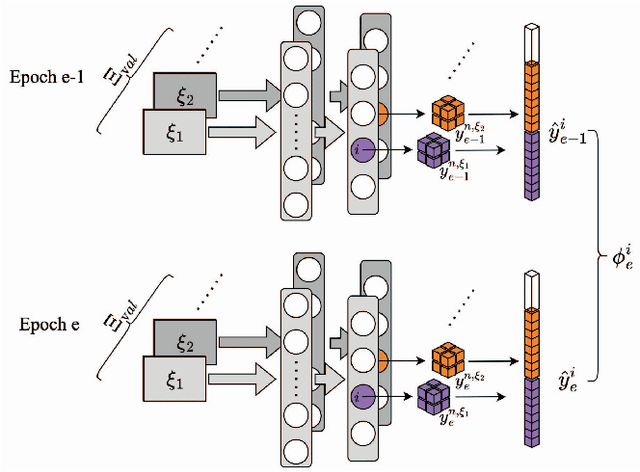
On-device training is an emerging approach in machine learning where models are trained on edge devices, aiming to enhance privacy protection and real-time performance. However, edge devices typically possess restricted computational power and resources, making it challenging to perform computationally intensive model training tasks. Consequently, reducing resource consumption during training has become a pressing concern in this field. To this end, we propose SCoTTi (Save Computation at Training Time), an adaptive framework that addresses the aforementioned challenge. It leverages an optimizable threshold parameter to effectively reduce the number of neuron updates during training which corresponds to a decrease in memory and computation footprint. Our proposed approach demonstrates superior performance compared to the state-of-the-art methods regarding computational resource savings on various commonly employed benchmarks and popular architectures, including ResNets, MobileNet, and Swin-T.
Enhanced EEG-Based Mental State Classification : A novel approach to eliminate data leakage and improve training optimization for Machine Learning
Dec 14, 2023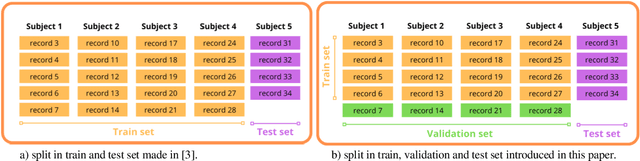
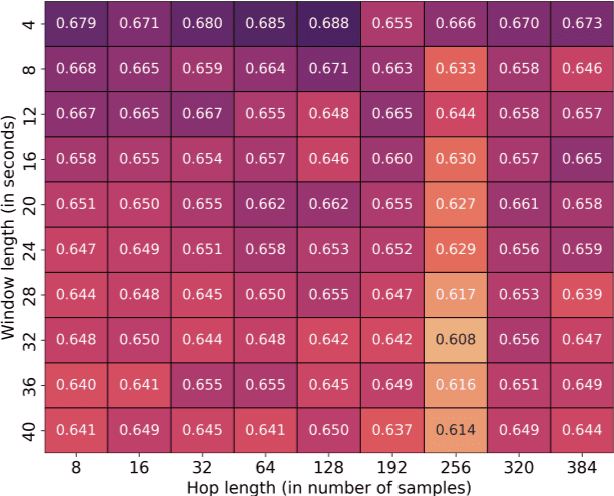
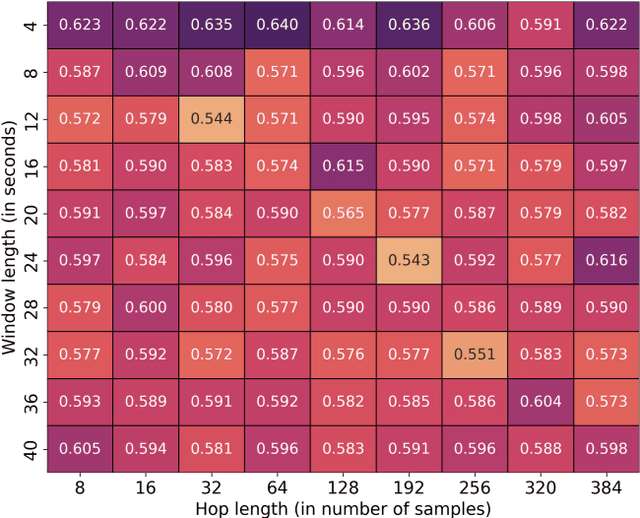
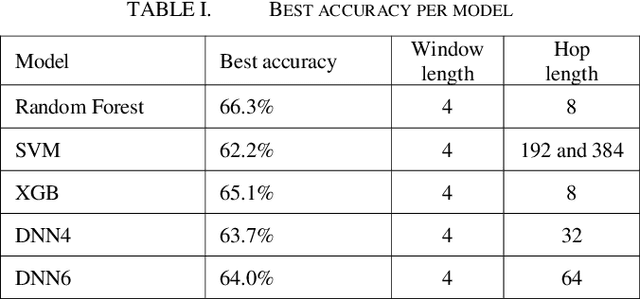
In this paper, we explore prior research and introduce a new methodology for classifying mental state levels based on EEG signals utilizing machine learning (ML). Our method proposes an optimized training method by introducing a validation set and a refined standardization process to rectify data leakage shortcomings observed in preceding studies. Furthermore, we establish novel benchmark figures for various models, including random forest and deep neural networks.