 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDebiasing surgeon: fantastic weights and how to find them
Paper and Code
Mar 21, 2024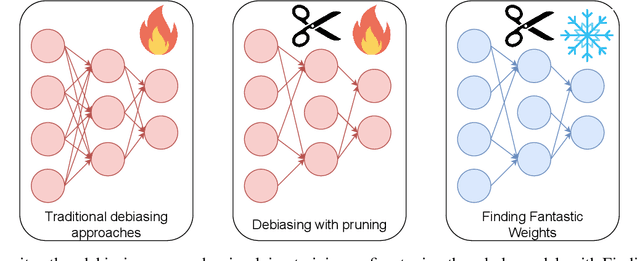

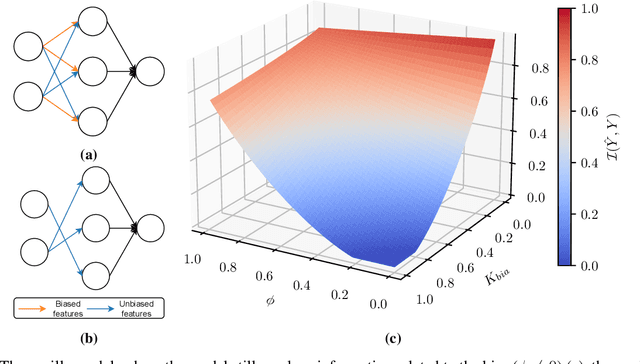
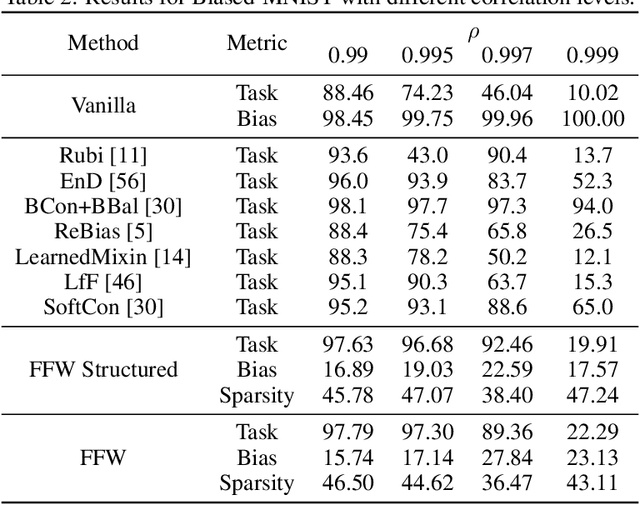
Nowadays an ever-growing concerning phenomenon, the emergence of algorithmic biases that can lead to unfair models, emerges. Several debiasing approaches have been proposed in the realm of deep learning, employing more or less sophisticated approaches to discourage these models from massively employing these biases. However, a question emerges: is this extra complexity really necessary? Is a vanilla-trained model already embodying some ``unbiased sub-networks'' that can be used in isolation and propose a solution without relying on the algorithmic biases? In this work, we show that such a sub-network typically exists, and can be extracted from a vanilla-trained model without requiring additional training. We further validate that such specific architecture is incapable of learning a specific bias, suggesting that there are possible architectural countermeasures to the problem of biases in deep neural networks.