 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeActivation Map Compression through Tensor Decomposition for Deep Learning
Nov 10, 2024

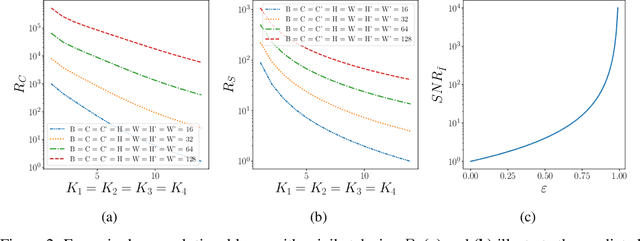

Internet of Things and Deep Learning are synergetically and exponentially growing industrial fields with a massive call for their unification into a common framework called Edge AI. While on-device inference is a well-explored topic in recent research, backpropagation remains an open challenge due to its prohibitive computational and memory costs compared to the extreme resource constraints of embedded devices. Drawing on tensor decomposition research, we tackle the main bottleneck of backpropagation, namely the memory footprint of activation map storage. We investigate and compare the effects of activation compression using Singular Value Decomposition and its tensor variant, High-Order Singular Value Decomposition. The application of low-order decomposition results in considerable memory savings while preserving the features essential for learning, and also offers theoretical guarantees to convergence. Experimental results obtained on main-stream architectures and tasks demonstrate Pareto-superiority over other state-of-the-art solutions, in terms of the trade-off between generalization and memory footprint.
Memory-Optimized Once-For-All Network
Sep 05, 2024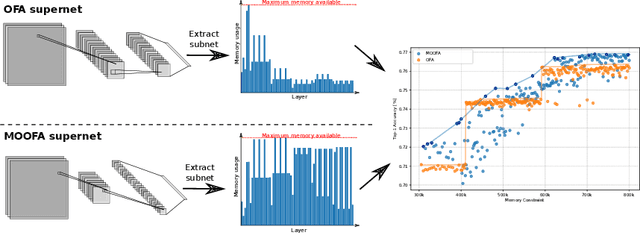



Deploying Deep Neural Networks (DNNs) on different hardware platforms is challenging due to varying resource constraints. Besides handcrafted approaches aiming at making deep models hardware-friendly, Neural Architectures Search is rising as a toolbox to craft more efficient DNNs without sacrificing performance. Among these, the Once-For-All (OFA) approach offers a solution by allowing the sampling of well-performing sub-networks from a single supernet -- this leads to evident advantages in terms of computation. However, OFA does not fully utilize the potential memory capacity of the target device, focusing instead on limiting maximum memory usage per layer. This leaves room for an unexploited potential in terms of model generalizability. In this paper, we introduce a Memory-Optimized OFA (MOOFA) supernet, designed to enhance DNN deployment on resource-limited devices by maximizing memory usage (and for instance, features diversity) across different configurations. Tested on ImageNet, our MOOFA supernet demonstrates improvements in memory exploitation and model accuracy compared to the original OFA supernet. Our code is available at https://github.com/MaximeGirard/memory-optimized-once-for-all.