 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTill the Layers Collapse: Compressing a Deep Neural Network through the Lenses of Batch Normalization Layers
Dec 19, 2024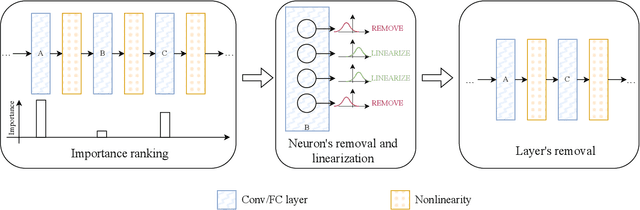
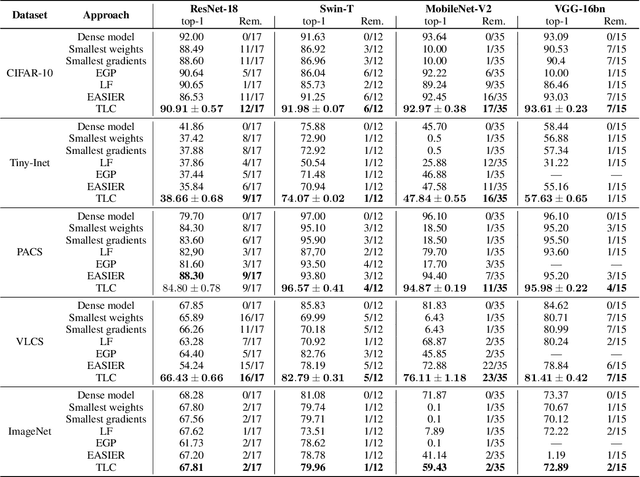
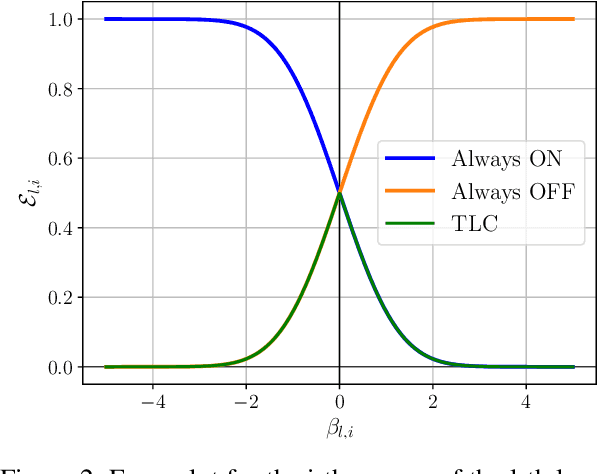
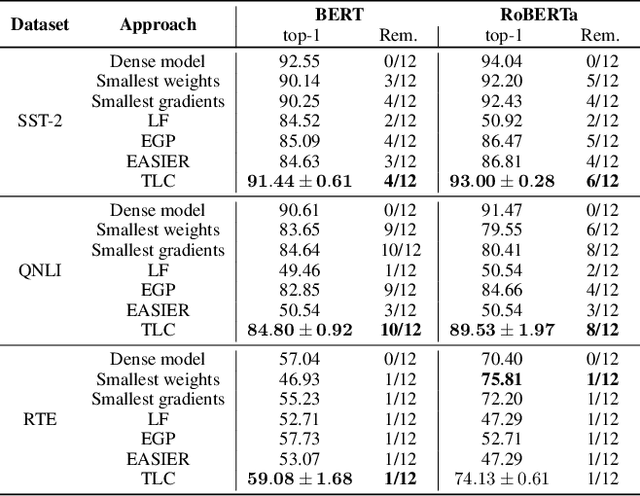
Today, deep neural networks are widely used since they can handle a variety of complex tasks. Their generality makes them very powerful tools in modern technology. However, deep neural networks are often overparameterized. The usage of these large models consumes a lot of computation resources. In this paper, we introduce a method called \textbf{T}ill the \textbf{L}ayers \textbf{C}ollapse (TLC), which compresses deep neural networks through the lenses of batch normalization layers. By reducing the depth of these networks, our method decreases deep neural networks' computational requirements and overall latency. We validate our method on popular models such as Swin-T, MobileNet-V2, and RoBERTa, across both image classification and natural language processing (NLP) tasks.
The Simpler The Better: An Entropy-Based Importance Metric To Reduce Neural Networks' Depth
Apr 27, 2024While deep neural networks are highly effective at solving complex tasks, large pre-trained models are commonly employed even to solve consistently simpler downstream tasks, which do not necessarily require a large model's complexity. Motivated by the awareness of the ever-growing AI environmental impact, we propose an efficiency strategy that leverages prior knowledge transferred by large models. Simple but effective, we propose a method relying on an Entropy-bASed Importance mEtRic (EASIER) to reduce the depth of over-parametrized deep neural networks, which alleviates their computational burden. We assess the effectiveness of our method on traditional image classification setups. The source code will be publicly released upon acceptance of the article.
NEPENTHE: Entropy-Based Pruning as a Neural Network Depth's Reducer
Apr 24, 2024



While deep neural networks are highly effective at solving complex tasks, their computational demands can hinder their usefulness in real-time applications and with limited-resources systems. Besides, for many tasks it is known that these models are over-parametrized: neoteric works have broadly focused on reducing the width of these networks, rather than their depth. In this paper, we aim to reduce the depth of over-parametrized deep neural networks: we propose an eNtropy-basEd Pruning as a nEural Network depTH's rEducer (NEPENTHE) to alleviate deep neural networks' computational burden. Based on our theoretical finding, NEPENTHE focuses on un-structurally pruning connections in layers with low entropy to remove them entirely. We validate our approach on popular architectures such as MobileNet and Swin-T, showing that when encountering an over-parametrization regime, it can effectively linearize some layers (hence reducing the model's depth) with little to no performance loss. The code will be publicly available upon acceptance of the article.
Can Unstructured Pruning Reduce the Depth in Deep Neural Networks?
Aug 18, 2023
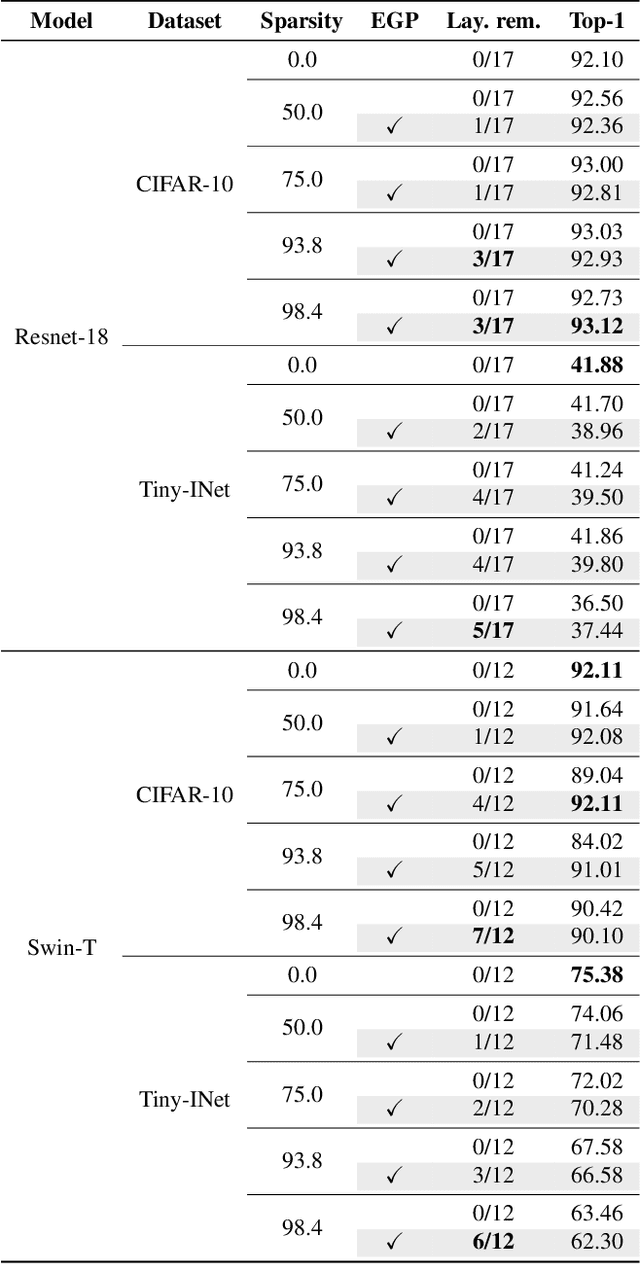
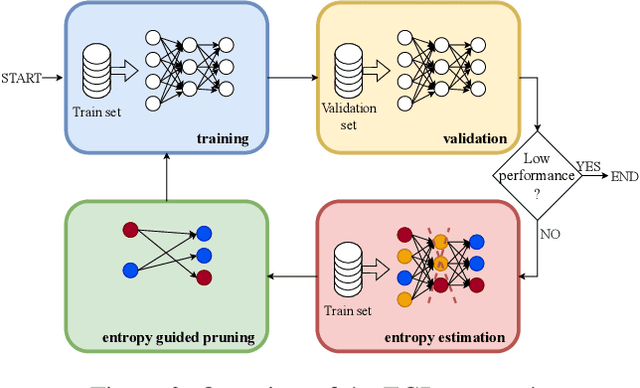

Pruning is a widely used technique for reducing the size of deep neural networks while maintaining their performance. However, such a technique, despite being able to massively compress deep models, is hardly able to remove entire layers from a model (even when structured): is this an addressable task? In this study, we introduce EGP, an innovative Entropy Guided Pruning algorithm aimed at reducing the size of deep neural networks while preserving their performance. The key focus of EGP is to prioritize pruning connections in layers with low entropy, ultimately leading to their complete removal. Through extensive experiments conducted on popular models like ResNet-18 and Swin-T, our findings demonstrate that EGP effectively compresses deep neural networks while maintaining competitive performance levels. Our results not only shed light on the underlying mechanism behind the advantages of unstructured pruning, but also pave the way for further investigations into the intricate relationship between entropy, pruning techniques, and deep learning performance. The EGP algorithm and its insights hold great promise for advancing the field of network compression and optimization. The source code for EGP is released open-source.