 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTill the Layers Collapse: Compressing a Deep Neural Network through the Lenses of Batch Normalization Layers
Dec 19, 2024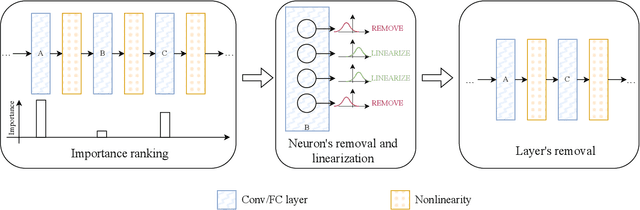
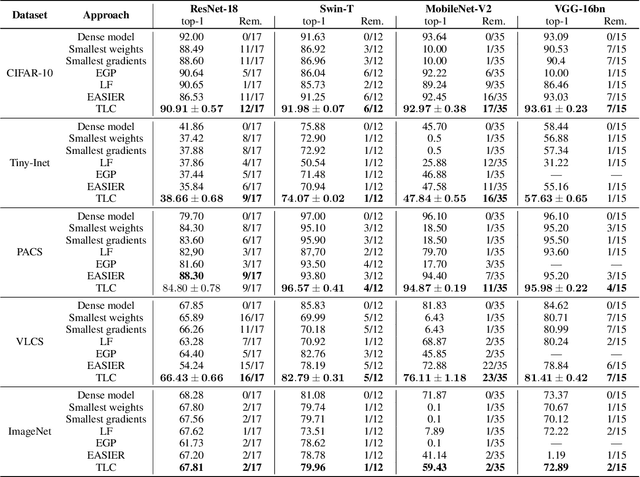
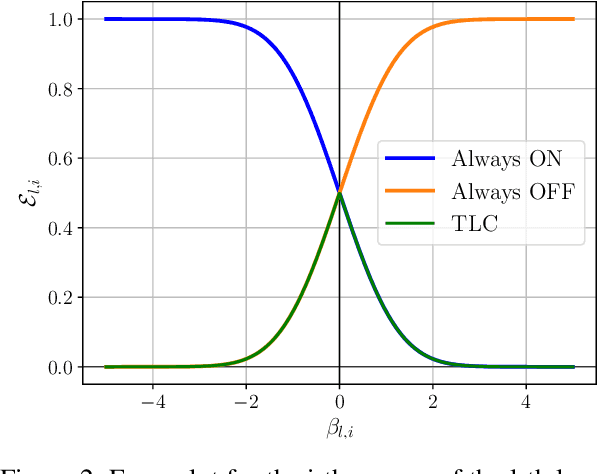
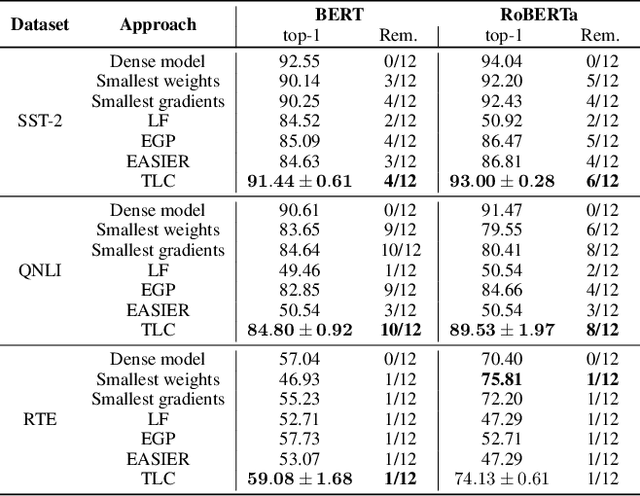
Today, deep neural networks are widely used since they can handle a variety of complex tasks. Their generality makes them very powerful tools in modern technology. However, deep neural networks are often overparameterized. The usage of these large models consumes a lot of computation resources. In this paper, we introduce a method called \textbf{T}ill the \textbf{L}ayers \textbf{C}ollapse (TLC), which compresses deep neural networks through the lenses of batch normalization layers. By reducing the depth of these networks, our method decreases deep neural networks' computational requirements and overall latency. We validate our method on popular models such as Swin-T, MobileNet-V2, and RoBERTa, across both image classification and natural language processing (NLP) tasks.
LaCoOT: Layer Collapse through Optimal Transport
Jun 13, 2024
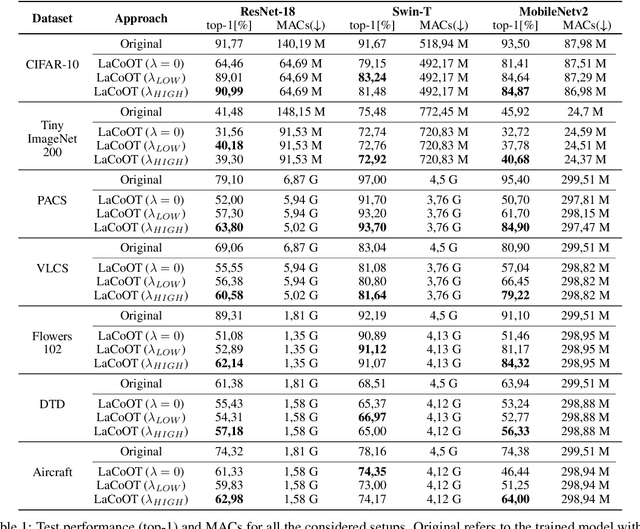
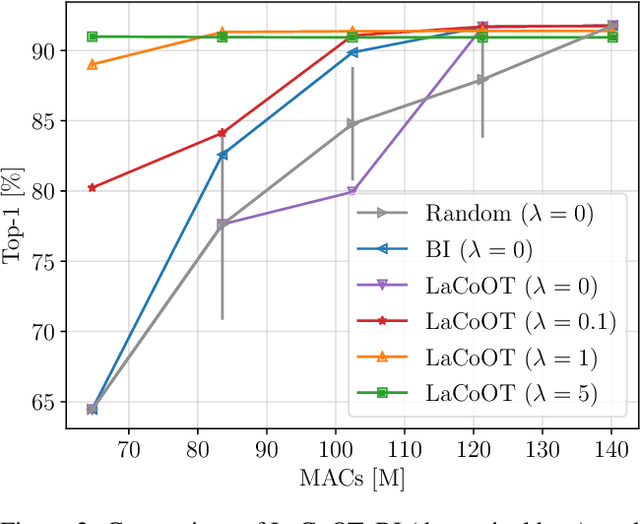
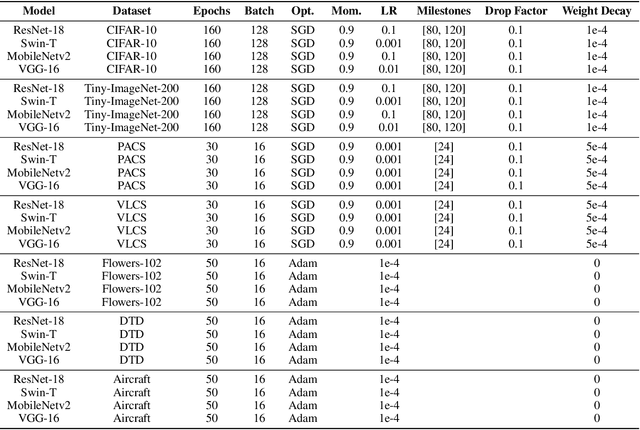
Although deep neural networks are well-known for their remarkable performance in tackling complex tasks, their hunger for computational resources remains a significant hurdle, posing energy-consumption issues and restricting their deployment on resource-constrained devices, which stalls their widespread adoption. In this paper, we present an optimal transport method to reduce the depth of over-parametrized deep neural networks, alleviating their computational burden. More specifically, we propose a new regularization strategy based on the Max-Sliced Wasserstein distance to minimize the distance between the intermediate feature distributions in the neural network. We show that minimizing this distance enables the complete removal of intermediate layers in the network, with almost no performance loss and without requiring any finetuning. We assess the effectiveness of our method on traditional image classification setups. We commit to releasing the source code upon acceptance of the article.